To be Continuous, or to be Discrete, Those are Bits of Questions

0
🔄
Sign in to get full access
Overview
- Binary representation is proposed as a new type of data representation that lies between continuous and discrete representations.
- This paper investigates using binary representation on the output side, allowing models to produce binary labels instead of continuous outputs.
- To preserve structural information along with label information, the authors extend a previous method called contrastive hashing into "structured contrastive hashing".
Plain English Explanation
The paper explores a new way to represent data called binary representation. This representation is in between the typical continuous and discrete representations used in machine learning. The authors wanted to see if they could use this binary representation not just for the input to a model, but also for the output.
To do this, they built on a previous technique called contrastive hashing. They modified it to preserve the structure and relationships in the output, not just the labels. This new method is called "structured contrastive hashing".
The key idea is that by using binary outputs instead of continuous ones, the model can produce discrete labels that are still rich in information and preserve important structural details. This could be useful for tasks like natural language processing, where the output needs to capture the complex relationships in language.
Technical Explanation
The paper proposes a new technique called "structured contrastive hashing" that extends previous work on contrastive hashing to allow models to output binary labels instead of continuous values.
To do this, the authors make a few key modifications to the contrastive hashing approach:
- They upgrade the CKY algorithm from working at the label-level to the bit-level, allowing the model to output a binary representation for each label.
- They define a new similarity function that considers the "span marginal probabilities" - essentially, how likely each part of the output structure is.
- They introduce a novel contrastive loss function along with a carefully designed instance selection strategy to train the model.
This allows the model to produce binary outputs that preserve the structural information in the target, rather than just the label information. The authors show that this "structured contrastive hashing" approach achieves competitive performance on various structured prediction tasks.
The key insight is that binary representation can serve as a middle ground between the continuous nature of deep learning and the inherently discrete structure of natural language and other domains. This bridges the gap and may lead to more interpretable and efficient models, especially for hybrid architectures.
Critical Analysis
The paper provides a compelling approach to leveraging binary representation for structured prediction tasks. However, there are a few potential limitations and areas for further research:
-
The experiments are focused on a limited set of tasks, so the generalizability of the method is not fully established. More extensive testing on a broader range of problems would help validate the approach.
-
The authors do not provide a detailed analysis of the computational efficiency or training time of the structured contrastive hashing method compared to other techniques. This could be an important practical consideration.
-
While the binary outputs preserve structural information, it's unclear how interpretable these representations are to human users. More work may be needed to ensure the model's decisions are transparent and explainable.
-
The paper does not discuss potential biases or fairness issues that could arise from using binary representations, especially in high-stakes applications. This is an important consideration for any new modeling approach.
Overall, the research presents an interesting step towards bridging the gap between continuous and discrete representations in deep learning. Further exploration of the strengths, limitations, and real-world implications of this approach would be valuable for advancing the field.
Conclusion
This paper proposes a novel technique called "structured contrastive hashing" that extends previous work on contrastive hashing to allow machine learning models to output binary labels instead of continuous values.
The key innovation is preserving the structural information in the output, not just the label information. This is achieved through modifications to the CKY algorithm, a new similarity function, and a specialized contrastive loss function.
The authors demonstrate that this binary output representation can achieve competitive performance on structured prediction tasks, suggesting it may serve as a useful middle ground between the continuous nature of deep learning and the inherently discrete structure of natural language and other domains.
Further research is needed to fully understand the strengths, limitations, and real-world implications of this approach, but it represents an intriguing step towards more interpretable and efficient machine learning models, especially for hybrid architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
To be Continuous, or to be Discrete, Those are Bits of Questions
Yiran Wang, Masao Utiyama
Recently, binary representation has been proposed as a novel representation that lies between continuous and discrete representations. It exhibits considerable information-preserving capability when being used to replace continuous input vectors. In this paper, we investigate the feasibility of further introducing it to the output side, aiming to allow models to output binary labels instead. To preserve the structural information on the output side along with label information, we extend the previous contrastive hashing method as structured contrastive hashing. More specifically, we upgrade CKY from label-level to bit-level, define a new similarity function with span marginal probabilities, and introduce a novel contrastive loss function with a carefully designed instance selection strategy. Our model achieves competitive performance on various structured prediction tasks, and demonstrates that binary representation can be considered a novel representation that further bridges the gap between the continuous nature of deep learning and the discrete intrinsic property of natural languages.
Read more6/13/2024

0
ResBit: Residual Bit Vector for Categorical Values
Masane Fuchi, Amar Zanashir, Hiroto Minami, Tomohiro Takagi
One-hot vectors, a method for representing discrete/categorical data, are commonly used in machine learning due to their simplicity and intuitiveness. However, the one-hot vectors suffer from a linear increase in dimensionality, posing computational and memory challenges, especially when dealing with datasets containing numerous categories. To address this issue, we propose Residual Bit Vectors (ResBit), a technique for densely representing categorical data. While Analog Bits presents a similar approach, it faces challenges in categorical data generation tasks. ResBit overcomes these limitations, offering a more versatile solution. In our experiments, we focus on tabular data generation, examining the performance across scenarios with varying amounts of categorical data. We verify the acceleration and ensure the maintenance or improvement of performance.
Read more4/30/2024
0
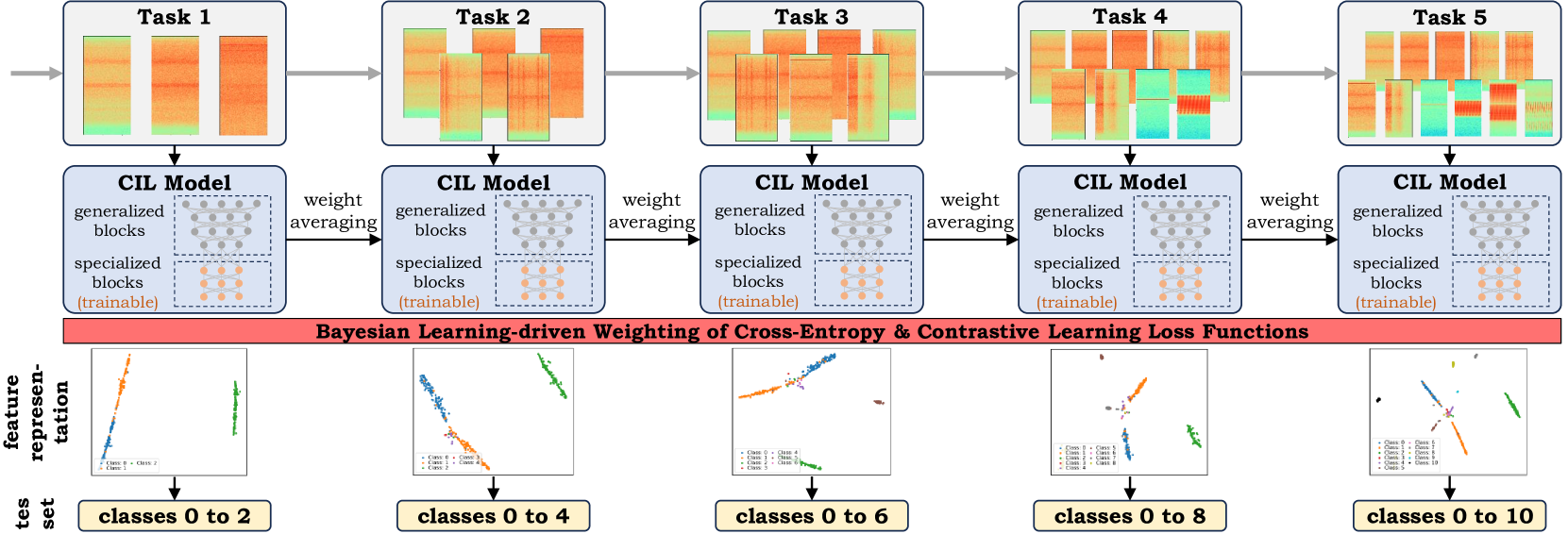
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 and CIFAR-100 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Read more7/15/2024
📉
0
Pre-Training Representations of Binary Code Using Contrastive Learning
Yifan Zhang, Chen Huang, Kevin Cao, Yueke Zhang, Scott Thomas Andersen, Huajie Shao, Kevin Leach, Yu Huang
Compiled software is delivered as executable binary code. Developers write source code to express the software semantics, but the compiler converts it to a binary format that the CPU can directly execute. Therefore, binary code analysis is critical to applications in reverse engineering and computer security tasks where source code is not available. However, unlike source code and natural language that contain rich semantic information, binary code is typically difficult for human engineers to understand and analyze. While existing work uses AI models to assist source code analysis, few studies have considered binary code. In this paper, we propose a COntrastive learning Model for Binary cOde Analysis, or COMBO, that incorporates source code and comment information into binary code during representation learning. Specifically, we present three components in COMBO: (1) a primary contrastive learning method for cold-start pre-training, (2) a simplex interpolation method to incorporate source code, comments, and binary code, and (3) an intermediate representation learning algorithm to provide binary code embeddings. Finally, we evaluate the effectiveness of the pre-trained representations produced by COMBO using three indicative downstream tasks relating to binary code: algorithmic functionality classification, binary code similarity, and vulnerability detection. Our experimental results show that COMBO facilitates representation learning of binary code visualized by distribution analysis, and improves the performance on all three downstream tasks by 5.45% on average compared to state-of-the-art large-scale language representation models. To the best of our knowledge, COMBO is the first language representation model that incorporates source code, binary code, and comments into contrastive code representation learning and unifies multiple tasks for binary code analysis.
Read more8/22/2024