Topic Modeling with Fine-tuning LLMs and Bag of Sentences

0

Sign in to get full access
Overview
- The provided paper presents a novel topic modeling approach that leverages pre-trained language models and a bag of sentences technique.
- The proposed method aims to improve the efficiency and flexibility of topic modeling for short text data.
- The research was presented at the International Conference on Agents and Artificial Intelligence (ICAART) in 2024.
Plain English Explanation
Topic modeling is a technique used to automatically discover the main themes or topics within a collection of text documents. This can be particularly challenging when working with short text data, such as social media posts or product reviews, as there is often limited context available.
The researchers in this paper introduce a new approach that combines pre-trained language models and a bag of sentences technique to improve the efficiency and flexibility of topic modeling for short texts. Pre-trained language models are powerful machine learning models that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. By incorporating these pre-trained models, the researchers aim to enhance the text embeddings used for topic modeling, leading to more accurate and informative results.
The bag of sentences approach involves representing each document as a collection of its individual sentences, rather than a single block of text. This allows the model to better capture the nuances and relationships between different ideas within a document, which can be particularly useful for short text data.
Overall, this research presents a novel and practical solution for topic modeling that addresses the challenges of working with short text data, with the potential to unlock valuable insights from a wide range of text-based sources.
Technical Explanation
The researchers propose a two-step approach for efficient and flexible topic modeling using pre-trained language models and a bag of sentences technique.
In the first step, they generate sentence embeddings for each sentence in the input text using a pre-trained language model. These sentence embeddings capture the semantic and contextual information of the individual sentences, which can then be used to represent the overall document.
In the second step, the researchers apply latent Dirichlet allocation (LDA), a popular topic modeling algorithm, to the bag of sentence embeddings. This allows the model to identify the latent topics within the collection of short text documents, while leveraging the rich semantic information captured by the pre-trained language model.
The key innovations of this approach include:
-
Leveraging Pre-Trained Language Models: By using pre-trained language models to generate sentence embeddings, the researchers can effectively leverage the vast knowledge and language understanding encoded in these powerful models, without the need for extensive task-specific training.
-
Bag of Sentences Representation: Representing each document as a bag of sentences, rather than a single block of text, enables the model to better capture the nuanced relationships between different ideas and topics within short text data.
-
Flexible and Efficient Topic Modeling: The combination of pre-trained language models and the bag of sentences approach enhances the text embeddings used for topic modeling, leading to more accurate and informative results, while also improving the overall efficiency of the topic modeling process.
Through extensive experiments on various short text datasets, the researchers demonstrate the effectiveness of their proposed approach, outperforming traditional topic modeling methods in terms of both topic coherence and computational efficiency.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper:
-
Domain-Specific Considerations: While the proposed method has been evaluated on general short text datasets, the performance may vary when applied to domain-specific corpora. Exploring the adaptability of the approach to different domains could be an interesting avenue for future research.
-
Interactive Topic Modeling: The current implementation of the method is static, requiring the entire corpus to be available upfront. Developing an interactive topic modeling approach that can handle streaming or incrementally added data could enhance the practical applicability of the technique.
-
Interpretability and Explainability: The use of pre-trained language models in the proposed method introduces a degree of complexity that may impact the interpretability and explainability of the resulting topic models. Exploring methods to improve the transparency and interpretability of the topic modeling process could be a valuable contribution.
Despite these limitations, the paper presents a compelling and practical approach to topic modeling that addresses the challenges of working with short text data. The researchers have demonstrated the effectiveness of their method through rigorous experimentation, and the potential implications of this work for various text-based applications are worth further exploration.
Conclusion
This research paper introduces a novel topic modeling approach that leverages pre-trained language models and a bag of sentences technique to improve the efficiency and flexibility of topic modeling for short text data. By incorporating powerful pre-trained language models and representing documents as collections of sentences, the proposed method is able to enhance the text embeddings used for topic modeling, leading to more accurate and informative results.
The key contributions of this work include the effective utilization of pre-trained language models for topic modeling, the bag of sentences approach to better capture the nuances within short text data, and the overall improvements in the efficiency and flexibility of the topic modeling process.
While the researchers have identified several areas for further research, this work represents a significant step forward in addressing the challenges of topic modeling for short text data and has the potential to unlock valuable insights from a wide range of text-based sources across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Topic Modeling with Fine-tuning LLMs and Bag of Sentences
Johannes Schneider
Large language models (LLM)'s are increasingly used for topic modeling outperforming classical topic models such as LDA. Commonly, pre-trained LLM encoders such as BERT are used out-of-the-box despite the fact that fine-tuning is known to improve LLMs considerably. The challenge lies in obtaining a suitable (labeled) dataset for fine-tuning. In this paper, we use the recent idea to use bag of sentences as the elementary unit in computing topics. In turn, we derive an approach FT-Topic to perform unsupervised fine-tuning relying primarily on two steps for constructing a training dataset in an automatic fashion. First, a heuristic method to identifies pairs of sentence groups that are either assumed to be of the same or different topics. Second, we remove sentence pairs that are likely labeled incorrectly. The dataset is then used to fine-tune an encoder LLM, which can be leveraged by any topic modeling approach using embeddings. However, in this work, we demonstrate its effectiveness by deriving a novel state-of-the-art topic modeling method called SenClu, which achieves fast inference through an expectation-maximization algorithm and hard assignments of sentence groups to a single topic, while giving users the possibility to encode prior knowledge on the topic-document distribution. Code is at url{https://github.com/JohnTailor/FT-Topic}
Read more8/7/2024
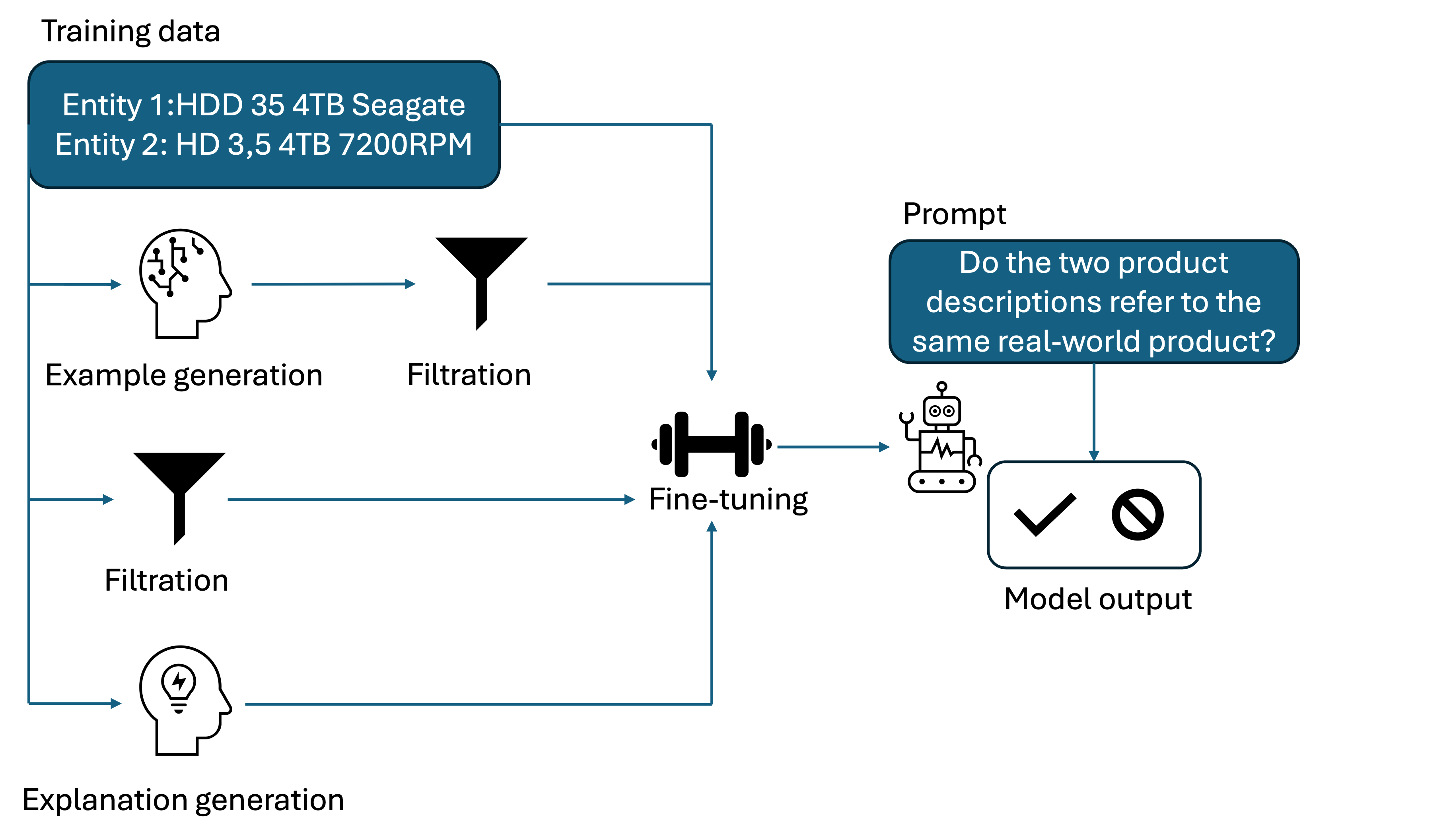
0
Fine-tuning Large Language Models for Entity Matching
Aaron Steiner, Ralph Peeters, Christian Bizer
Generative large language models (LLMs) are a promising alternative to pre-trained language models for entity matching due to their high zero-shot performance and their ability to generalize to unseen entities. Existing research on using LLMs for entity matching has focused on prompt engineering and in-context learning. This paper explores the potential of fine-tuning LLMs for entity matching. We analyze fine-tuning along two dimensions: 1) The representation of training examples, where we experiment with adding different types of LLM-generated explanations to the training set, and 2) the selection and generation of training examples using LLMs. In addition to the matching performance on the source dataset, we investigate how fine-tuning affects the model's ability to generalize to other in-domain datasets as well as across topical domains. Our experiments show that fine-tuning significantly improves the performance of the smaller models while the results for the larger models are mixed. Fine-tuning also improves the generalization to in-domain datasets while hurting cross-domain transfer. We show that adding structured explanations to the training set has a positive impact on the performance of three out of four LLMs, while the proposed example selection and generation methods only improve the performance of Llama 3.1 8B while decreasing the performance of GPT-4o Mini.
Read more9/14/2024

0
Topic Modeling for Short Texts with Large Language Models
Tomoki Doi, Masaru Isonuma, Hitomi Yanaka
As conventional topic models rely on word co-occurrence to infer latent topics, topic modeling for short texts has been a long-standing challenge. Large Language Models (LLMs) can potentially overcome this challenge by contextually learning the semantics of words via pretraining. This paper studies two approaches, parallel prompting and sequential prompting, to use LLMs for topic modeling. Due to the input length limitations, LLMs cannot process many texts at once. By splitting the texts into smaller subsets and processing them parallelly or sequentially, an arbitrary number of texts can be handled by LLMs. Experimental results demonstrated that our methods can identify more coherent topics than existing ones while maintaining the diversity of the induced topics. Furthermore, we found that the inferred topics adequately covered the input texts, while hallucinated topics were hardly generated.
Read more6/4/2024
💬
0
Leveraging Large Language Models for Knowledge-free Weak Supervision in Clinical Natural Language Processing
Enshuo Hsu, Kirk Roberts
The performance of deep learning-based natural language processing systems is based on large amounts of labeled training data which, in the clinical domain, are not easily available or affordable. Weak supervision and in-context learning offer partial solutions to this issue, particularly using large language models (LLMs), but their performance still trails traditional supervised methods with moderate amounts of gold-standard data. In particular, inferencing with LLMs is computationally heavy. We propose an approach leveraging fine-tuning LLMs and weak supervision with virtually no domain knowledge that still achieves consistently dominant performance. Using a prompt-based approach, the LLM is used to generate weakly-labeled data for training a downstream BERT model. The weakly supervised model is then further fine-tuned on small amounts of gold standard data. We evaluate this approach using Llama2 on three different n2c2 datasets. With no more than 10 gold standard notes, our final BERT models weakly supervised by fine-tuned Llama2-13B consistently outperformed out-of-the-box PubMedBERT by 4.7% to 47.9% in F1 scores. With only 50 gold standard notes, our models achieved close performance to fully fine-tuned systems.
Read more6/12/2024