TransCoder: Towards Unified Transferable Code Representation Learning Inspired by Human Skills

0
Sign in to get full access
Overview
- This paper introduces TransCoder, a new approach to learning transferable code representations inspired by human skills.
- The goal is to develop a unified model that can understand and generate code across different programming languages, similar to how humans can learn to code in multiple languages.
- The research explores techniques for learning code representations that capture the semantics and structure of code, and can be effectively transferred to various coding tasks.
Plain English Explanation
The researchers behind this paper are trying to create a new way for AI systems to work with and understand code. Typically, AI models are trained on code in a specific programming language, and they struggle to apply what they've learned to other languages. The researchers wanted to develop a more "human-like" approach, where the AI can learn general concepts about coding that can be applied across different programming languages.
The key idea is to take inspiration from how humans learn to code. When people learn a new programming language, they don't start from scratch - they leverage the coding skills and knowledge they've developed in other languages. The researchers wanted to capture this transferable knowledge in their AI model, called TransCoder.
The goal of TransCoder is to learn code representations that capture the underlying structure and semantics of code, rather than just the specific syntax of a single language. This allows the model to understand the fundamental concepts of coding, and apply that knowledge to tasks like code generation, translation, and optimization, across a variety of programming languages.
The researchers experimented with different techniques to achieve this, like exploring the power of large language models for automated coding and leveraging intermediate representations to make language models more robust. The key insight is that by learning a unified, transferable code representation, the AI can become much more flexible and capable when working with code.
Technical Explanation
The researchers propose a novel approach called TransCoder that aims to learn a unified, transferable code representation inspired by how humans develop coding skills across multiple programming languages.
The core idea is to train a single neural network model that can understand and generate code in different programming languages, rather than having separate models for each language. To achieve this, the researchers explore various techniques:
-
Structure-aware Fine-tuning: The model is first pre-trained on a large corpus of code in multiple languages to learn general code semantics and structures. It is then fine-tuned on specific coding tasks, preserving the high-level structural understanding. This is similar to structure-aware fine-tuning approaches for code.
-
Intermediate Representations: The model learns to map code from different languages into a shared, language-agnostic intermediate representation. This allows the model to reason about code at a more abstract level, similar to how IRCoder uses intermediate representations to make language models more robust.
-
Joint Text-Code Embeddings: The model learns to align textual descriptions of coding concepts with their corresponding code representations. This joint text-source code embedding approach helps the model understand the semantic relationship between natural language and code.
-
Code Instruction Tuning: The model is further fine-tuned on a large corpus of natural language instructions paired with their corresponding code snippets. This code instruction tuning allows the model to better understand the mapping between natural language and code.
Through these techniques, the researchers aim to develop a transferable code representation that captures the underlying structure and semantics of code, rather than just the surface-level syntax. This allows the TransCoder model to perform a variety of coding-related tasks, such as code generation, translation, and optimization, across multiple programming languages.
Critical Analysis
The TransCoder approach is a promising step towards more flexible and capable AI systems for working with code. By learning a unified, transferable code representation, the model can potentially be applied to a wide range of coding tasks and languages, overcoming the typical limitations of language-specific models.
However, the paper does not provide a comprehensive evaluation of the model's performance across a diverse set of programming languages and tasks. The experiments primarily focus on a few common languages, such as Python, Java, and C++. It would be valuable to see how well the model generalizes to less common or more specialized programming languages.
Additionally, the paper does not delve into the potential challenges or limitations of the TransCoder approach. For example, it's unclear how the model would handle rapidly evolving programming languages, or how it would scale to handle the complexity of real-world software projects. Further research is needed to explore the robustness and scalability of the TransCoder approach.
Despite these potential limitations, the core idea of learning a transferable code representation is a promising direction for the field of AI-powered software development. By taking inspiration from human coding skills, the TransCoder approach represents a step towards more flexible and adaptable AI systems that can assist developers in a wide range of programming tasks.
Conclusion
The TransCoder paper presents a novel approach to learning transferable code representations, inspired by how humans develop coding skills across multiple programming languages. By exploring techniques like structure-aware fine-tuning, intermediate representations, joint text-code embeddings, and code instruction tuning, the researchers aim to create a unified model that can understand and generate code in a variety of languages.
The key innovation of TransCoder is the ability to capture the underlying structure and semantics of code, rather than just the specific syntax of individual programming languages. This allows the model to apply its learned knowledge to a wide range of coding-related tasks, such as code generation, translation, and optimization.
While the paper does not provide a comprehensive evaluation of the model's performance, the core idea of learning a transferable code representation is a promising direction for the field of AI-powered software development. By taking inspiration from human coding skills, the TransCoder approach represents a step towards more flexible and adaptable AI systems that can assist developers in a variety of programming tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TransCoder: Towards Unified Transferable Code Representation Learning Inspired by Human Skills
Qiushi Sun, Nuo Chen, Jianing Wang, Xiang Li, Ming Gao
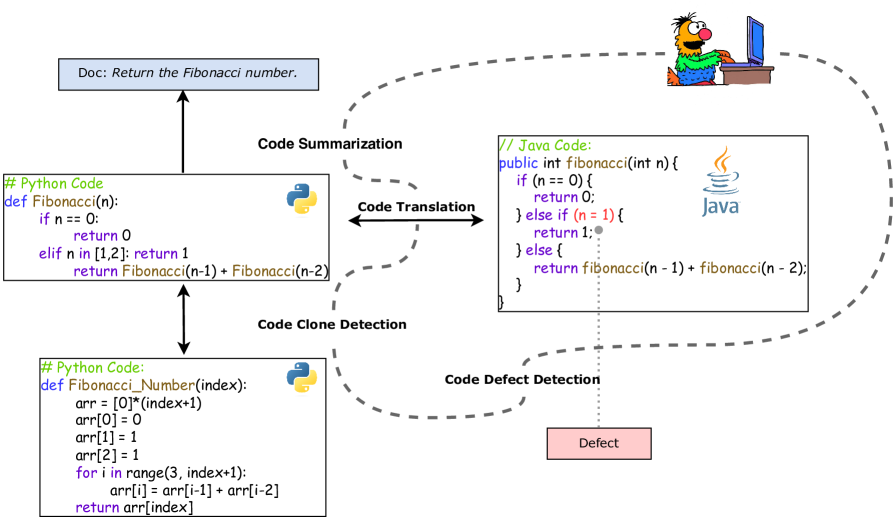
Code pre-trained models (CodePTMs) have recently demonstrated a solid capacity to process various software intelligence tasks, e.g., code clone detection, code translation, and code summarization. The current mainstream method that deploys these models to downstream tasks is to fine-tune them on individual tasks, which is generally costly and needs sufficient data for large models. To tackle the issue, in this paper, we present TransCoder, a unified Transferable fine-tuning strategy for Code representation learning. Inspired by human inherent skills of knowledge generalization, TransCoder drives the model to learn better code-related meta-knowledge like human programmers. Specifically, we employ a tunable prefix encoder as the meta-learner to capture cross-task and cross-language transferable knowledge, respectively. Besides, tasks with minor training sample sizes and languages with small corpus can be remarkably benefited from our approach. Extensive experiments conducted on benchmark datasets clearly demonstrate that our method can lead to superior performance on various code-related tasks and encourage mutual reinforcement. We also show that TransCoder is applicable in low-resource scenarios. Our codes are available at https://github.com/QiushiSun/TransCoder.
Read more5/10/2024
0
Toward Exploring the Code Understanding Capabilities of Pre-trained Code Generation Models
Jiayi Lin, Yutao Xie, Yue Yu, Yibiao Yang, Lei Zhang
Recently, large code generation models trained in a self-supervised manner on extensive unlabeled programming language data have achieved remarkable success. While these models acquire vast amounts of code knowledge, they perform poorly on code understanding tasks, such as code search and clone detection, as they are specifically trained for generation. Pre-training a larger encoder-only architecture model from scratch on massive code data can improve understanding performance. However, this approach is costly and time-consuming, making it suboptimal. In this paper, we pioneer the transfer of knowledge from pre-trained code generation models to code understanding tasks, significantly reducing training costs. We examine effective strategies for enabling decoder-only models to acquire robust code representations. Furthermore, we introduce CL4D, a contrastive learning method designed to enhance the representation capabilities of decoder-only models. Comprehensive experiments demonstrate that our approach achieves state-of-the-art performance in understanding tasks such as code search and clone detection. Our analysis shows that our method effectively reduces the distance between semantically identical samples in the representation space. These findings suggest the potential for unifying code understanding and generation tasks using a decoder-only structured model.
Read more6/19/2024

0
UniCoder: Scaling Code Large Language Model via Universal Code
Tao Sun, Linzheng Chai, Jian Yang, Yuwei Yin, Hongcheng Guo, Jiaheng Liu, Bing Wang, Liqun Yang, Zhoujun Li
Intermediate reasoning or acting steps have successfully improved large language models (LLMs) for handling various downstream natural language processing (NLP) tasks. When applying LLMs for code generation, recent works mainly focus on directing the models to articulate intermediate natural-language reasoning steps, as in chain-of-thought (CoT) prompting, and then output code with the natural language or other structured intermediate steps. However, such output is not suitable for code translation or generation tasks since the standard CoT has different logical structures and forms of expression with the code. In this work, we introduce the universal code (UniCode) as the intermediate representation. It is a description of algorithm steps using a mix of conventions of programming languages, such as assignment operator, conditional operator, and loop. Hence, we collect an instruction dataset UniCoder-Instruct to train our model UniCoder on multi-task learning objectives. UniCoder-Instruct comprises natural-language questions, code solutions, and the corresponding universal code. The alignment between the intermediate universal code representation and the final code solution significantly improves the quality of the generated code. The experimental results demonstrate that UniCoder with the universal code significantly outperforms the previous prompting methods by a large margin, showcasing the effectiveness of the structural clues in pseudo-code.
Read more6/26/2024
0
IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators
Indraneil Paul, Goran Glavav{s}, Iryna Gurevych
Code understanding and generation have fast become some of the most popular applications of language models (LMs). Nonetheless, research on multilingual aspects of Code-LMs (i.e., LMs for code generation) such as cross-lingual transfer between different programming languages, language-specific data augmentation, and post-hoc LM adaptation, alongside exploitation of data sources other than the original textual content, has been much sparser than for their natural language counterparts. In particular, most mainstream Code-LMs have been pre-trained on source code files alone. In this work, we investigate the prospect of leveraging readily available compiler intermediate representations (IR) - shared across programming languages - to improve the multilingual capabilities of Code-LMs and facilitate cross-lingual transfer. To this end, we first compile SLTrans, a parallel dataset consisting of nearly 4M self-contained source code files coupled with respective intermediate representations. Next, starting from various base Code-LMs (ranging in size from 1.1B to 7.3B parameters), we carry out continued causal language modelling training on SLTrans, forcing the Code-LMs to (1) learn the IR language and (2) align the IR constructs with respective constructs of various programming languages. Our resulting models, dubbed IRCoder, display sizeable and consistent gains across a wide variety of code generation tasks and metrics, including prompt robustness, multilingual code completion, code understanding, and instruction following.
Read more4/16/2024