Multi-word Tokenization for Sequence Compression
2402.09949
0
0
Abstract
Large Language Models have proven highly successful at modelling a variety of tasks. However, this comes at a steep computational cost that hinders wider industrial uptake. In this paper, we present MWT: a Multi-Word Tokenizer that goes beyond word boundaries by representing frequent multi-word expressions as single tokens. MWTs produce a more compact and efficient tokenization that yields two benefits: (1) Increase in performance due to a greater coverage of input data given a fixed sequence length budget; (2) Faster and lighter inference due to the ability to reduce the sequence length with negligible drops in performance. Our results show that MWT is more robust across shorter sequence lengths, thus allowing for major speedups via early sequence truncation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a novel approach called "Multi-word Tokenization" (MWT) for compressing text sequences.
- MWT aims to improve on traditional word-level tokenization by identifying and encoding common multi-word expressions as single tokens.
- The key insight is that compressing sequences by grouping words into meaningful units can lead to more efficient encoding compared to treating each word separately.
Plain English Explanation
The paper describes a method called "Multi-word Tokenization" (MWT) to make text more compact. Traditionally, text is broken down into individual words when it's encoded for storage or transmission. But the authors noticed that certain common multi-word phrases, like "New York City" or "United States of America", could be represented as single units instead.
By identifying and encoding these multi-word expressions as single tokens, the MWT approach can compress the text more effectively than traditional word-level tokenization. The idea is that treating meaningful groups of words as single units allows for more efficient encoding compared to breaking everything down into individual words. This could be useful for applications like improving neural language models or efficient storage and transmission of text data.
Technical Explanation
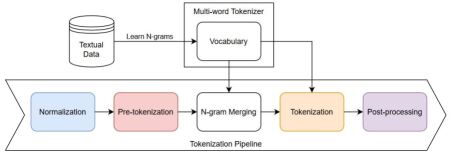
The key innovation in this paper is the Multi-word Tokenization (MWT) approach, which groups common sequences of words into single tokens during the text encoding process. This is in contrast to the more standard practice of tokenizing text at the individual word level.
The authors first train a model to identify multi-word expressions (MWEs) in the text using a combination of statistical and linguistic signals. These MWEs are then substituted in the original text, replacing the individual words with a single token representing the entire phrase.
This MWT-encoded text is then used to train a language model, which can learn the statistical patterns and semantics of the compressed sequences more efficiently than a model trained on uncompressed, word-level text. The authors demonstrate improvements in language modeling performance compared to baseline word-level models, particularly on tasks that benefit from understanding longer-range contextual relationships.
Critical Analysis
The authors acknowledge some limitations of their approach. For example, the MWT process may introduce some ambiguity or errors when identifying the correct multi-word expressions to replace. There is also a tradeoff between the compression gains and the potential loss of fine-grained information by coarsening the text representation.
Additionally, the paper does not explore the implications of injecting multi-bit information into the MWT tokens, which could have interesting applications but also raises potential security and privacy concerns.
Overall, the MWT approach is a clever and promising technique for improving text compression and language modeling. However, further research is needed to fully understand its strengths, limitations, and suitable applications.
Conclusion
This paper introduces a novel "Multi-word Tokenization" (MWT) method for compressing text sequences more effectively than traditional word-level tokenization. By identifying and encoding common multi-word expressions as single tokens, MWT can lead to more efficient representation and processing of text data.
The authors demonstrate how MWT-encoded text can be used to train improved language models, with potential benefits for applications ranging from storage and transmission to natural language understanding. While the approach has some limitations, it represents an intriguing advance in the field of text compression and modeling that warrants further exploration and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, Gabriel Synnaeve
0
0
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
5/1/2024
⚙️
Toward a Theory of Tokenization in LLMs
Nived Rajaraman, Jiantao Jiao, Kannan Ramchandran
0
0
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
4/15/2024
Training LLMs over Neurally Compressed Text
Brian Lester, Jaehoon Lee, Alex Alemi, Jeffrey Pennington, Adam Roberts, Jascha Sohl-Dickstein, Noah Constant
0
0
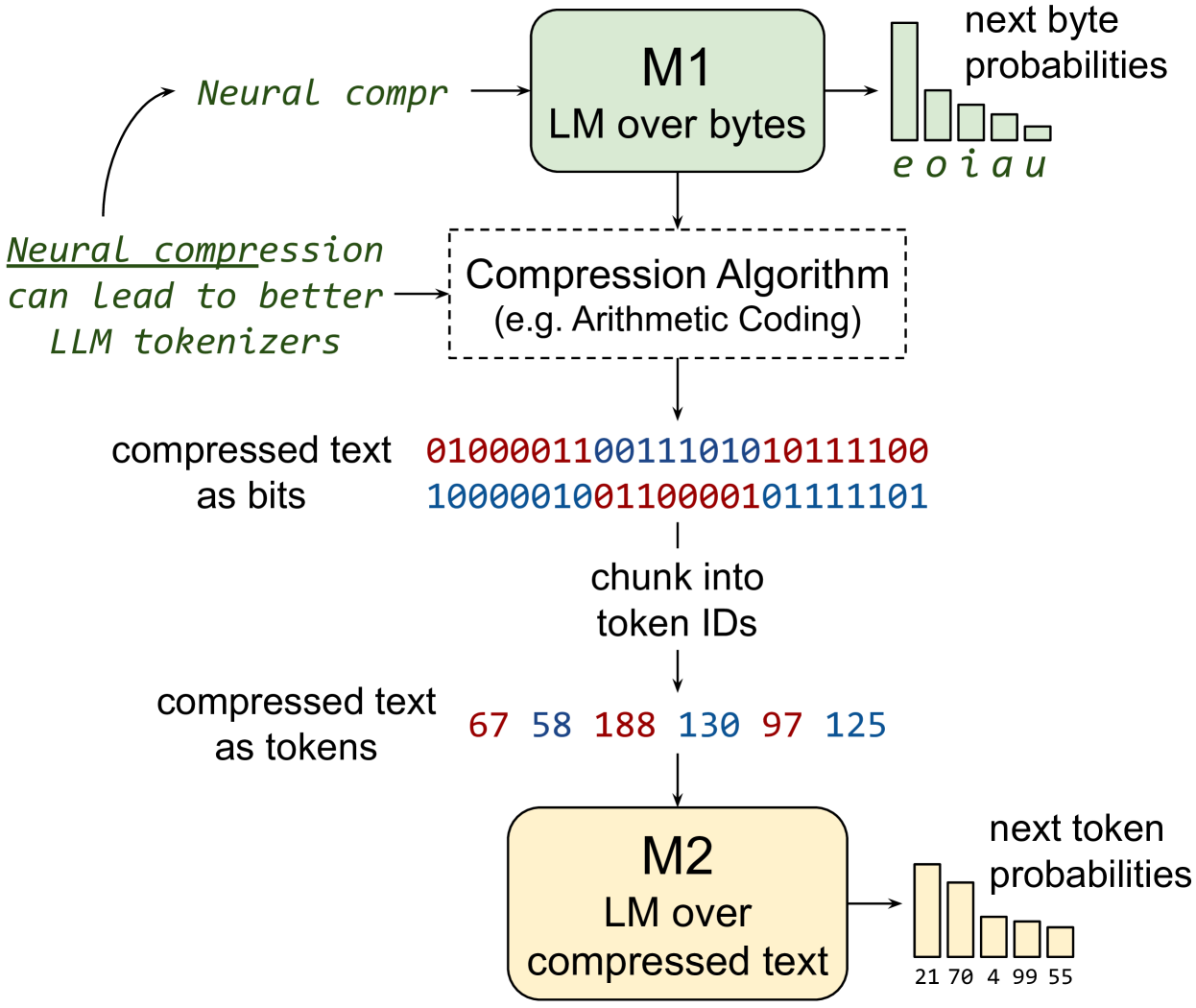
In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can achieve much higher rates of compression. If it were possible to train LLMs directly over neurally compressed text, this would confer advantages in training and serving efficiency, as well as easier handling of long text spans. The main obstacle to this goal is that strong compression tends to produce opaque outputs that are not well-suited for learning. In particular, we find that text naively compressed via Arithmetic Coding is not readily learnable by LLMs. To overcome this, we propose Equal-Info Windows, a novel compression technique whereby text is segmented into blocks that each compress to the same bit length. Using this method, we demonstrate effective learning over neurally compressed text that improves with scale, and outperforms byte-level baselines by a wide margin on perplexity and inference speed benchmarks. While our method delivers worse perplexity than subword tokenizers for models trained with the same parameter count, it has the benefit of shorter sequence lengths. Shorter sequence lengths require fewer autoregressive generation steps, and reduce latency. Finally, we provide extensive analysis of the properties that contribute to learnability, and offer concrete suggestions for how to further improve the performance of high-compression tokenizers.
4/5/2024
🔄
Zero-Shot Tokenizer Transfer
Benjamin Minixhofer, Edoardo Maria Ponti, Ivan Vuli'c
0
0
Language models (LMs) are bound to their tokenizer, which maps raw text to a sequence of vocabulary items (tokens). This restricts their flexibility: for example, LMs trained primarily on English may still perform well in other natural and programming languages, but have vastly decreased efficiency due to their English-centric tokenizer. To mitigate this, we should be able to swap the original LM tokenizer with an arbitrary one, on the fly, without degrading performance. Hence, in this work we define a new problem: Zero-Shot Tokenizer Transfer (ZeTT). The challenge at the core of ZeTT is finding embeddings for the tokens in the vocabulary of the new tokenizer. Since prior heuristics for initializing embeddings often perform at chance level in a ZeTT setting, we propose a new solution: we train a hypernetwork taking a tokenizer as input and predicting the corresponding embeddings. We empirically demonstrate that the hypernetwork generalizes to new tokenizers both with encoder (e.g., XLM-R) and decoder LLMs (e.g., Mistral-7B). Our method comes close to the original models' performance in cross-lingual and coding tasks while markedly reducing the length of the tokenized sequence. We also find that the remaining gap can be quickly closed by continued training on less than 1B tokens. Finally, we show that a ZeTT hypernetwork trained for a base (L)LM can also be applied to fine-tuned variants without extra training. Overall, our results make substantial strides toward detaching LMs from their tokenizer.
5/14/2024