Towards Fast Rates for Federated and Multi-Task Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- This paper proposes new algorithms for federated and multi-task reinforcement learning that achieve faster convergence rates compared to existing methods.
- The key ideas include a new algorithm for federated learning that leverages model-agnostic meta-learning, and a multi-task learning approach that shares representations across tasks.
- The authors demonstrate the effectiveness of their methods on several reinforcement learning benchmarks.
Plain English Explanation
The paper focuses on the challenge of [object Object] and [object Object]. In federated learning, multiple agents or devices collaborate to train a shared model without sharing their raw data. In multi-task learning, a single model is trained to solve multiple related tasks simultaneously.
The key innovation in this paper is the development of new algorithms that can learn these models more efficiently, converging to good solutions faster than previous methods. For federated learning, the authors propose a technique inspired by [object Object] that enables the shared model to adapt quickly to the data of individual agents. For multi-task learning, they introduce a way to share representations across tasks, allowing the model to leverage similarities and accelerate learning.
The authors demonstrate that these algorithms outperform existing federated and multi-task reinforcement learning methods on several benchmark tasks, suggesting they could be valuable tools for real-world applications where fast learning is crucial.
Technical Explanation
The paper proposes two main algorithmic contributions:
-
Federated Reinforcement Learning with Meta-Learning: The authors introduce a new federated learning algorithm called FedMeta that leverages model-agnostic meta-learning. In this approach, the shared global model is trained to quickly adapt to the data of individual agents using a meta-objective. This allows the model to learn a good initial representation that can be fine-tuned efficiently on each agent's local data.
-
Multi-Task Reinforcement Learning with Representation Sharing: For multi-task reinforcement learning, the authors develop an algorithm that learns a shared representation across tasks. This is achieved by introducing a novel regularizer that encourages the model to discover task-agnostic features, which can then be used to accelerate learning on each individual task.
The authors conduct experiments on several reinforcement learning benchmarks, including [object Object] environments and the [object Object] game suite. The results show that their FedMeta and multi-task learning algorithms achieve faster convergence rates and higher final performance compared to existing federated and multi-task RL methods.
Critical Analysis
The paper makes several important contributions to the fields of federated and multi-task reinforcement learning. The proposed algorithms demonstrate significant improvements in learning efficiency, which could be valuable for real-world applications where rapid adaptation and generalization are crucial.
However, the authors do not explore the limitations of their methods in depth. For example, it is unclear how the FedMeta algorithm would scale to larger numbers of agents with more heterogeneous data distributions, or how the multi-task learning approach would perform on tasks with more substantial differences. Additionally, the paper does not provide much insight into the underlying mechanisms that enable the improved convergence rates.
Further research could investigate the robustness of these algorithms to different problem settings, as well as explore ways to make the learning process more interpretable and provide a deeper understanding of the factors driving the performance improvements.
Conclusion
This paper presents novel algorithms for federated and multi-task reinforcement learning that achieve faster convergence rates compared to existing methods. The key ideas include a meta-learning approach for federated learning and a representation sharing technique for multi-task learning. The authors demonstrate the effectiveness of their algorithms on several benchmark tasks, suggesting they could be valuable tools for real-world applications where rapid adaptation and generalization are important.
While the paper makes significant technical contributions, further research is needed to fully understand the limitations and potential of these methods. Exploring their scalability, robustness, and interpretability could lead to important insights and drive the field of reinforcement learning forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Towards Fast Rates for Federated and Multi-Task Reinforcement Learning
Feng Zhu, Robert W. Heath Jr., Aritra Mitra
We consider a setting involving $N$ agents, where each agent interacts with an environment modeled as a Markov Decision Process (MDP). The agents' MDPs differ in their reward functions, capturing heterogeneous objectives/tasks. The collective goal of the agents is to communicate intermittently via a central server to find a policy that maximizes the average of long-term cumulative rewards across environments. The limited existing work on this topic either only provide asymptotic rates, or generate biased policies, or fail to establish any benefits of collaboration. In response, we propose Fast-FedPG - a novel federated policy gradient algorithm with a carefully designed bias-correction mechanism. Under a gradient-domination condition, we prove that our algorithm guarantees (i) fast linear convergence with exact gradients, and (ii) sub-linear rates that enjoy a linear speedup w.r.t. the number of agents with noisy, truncated policy gradients. Notably, in each case, the convergence is to a globally optimal policy with no heterogeneity-induced bias. In the absence of gradient-domination, we establish convergence to a first-order stationary point at a rate that continues to benefit from collaboration.
Read more9/10/2024
0
Asynchronous Federated Reinforcement Learning with Policy Gradient Updates: Algorithm Design and Convergence Analysis
Guangchen Lan, Dong-Jun Han, Abolfazl Hashemi, Vaneet Aggarwal, Christopher G. Brinton
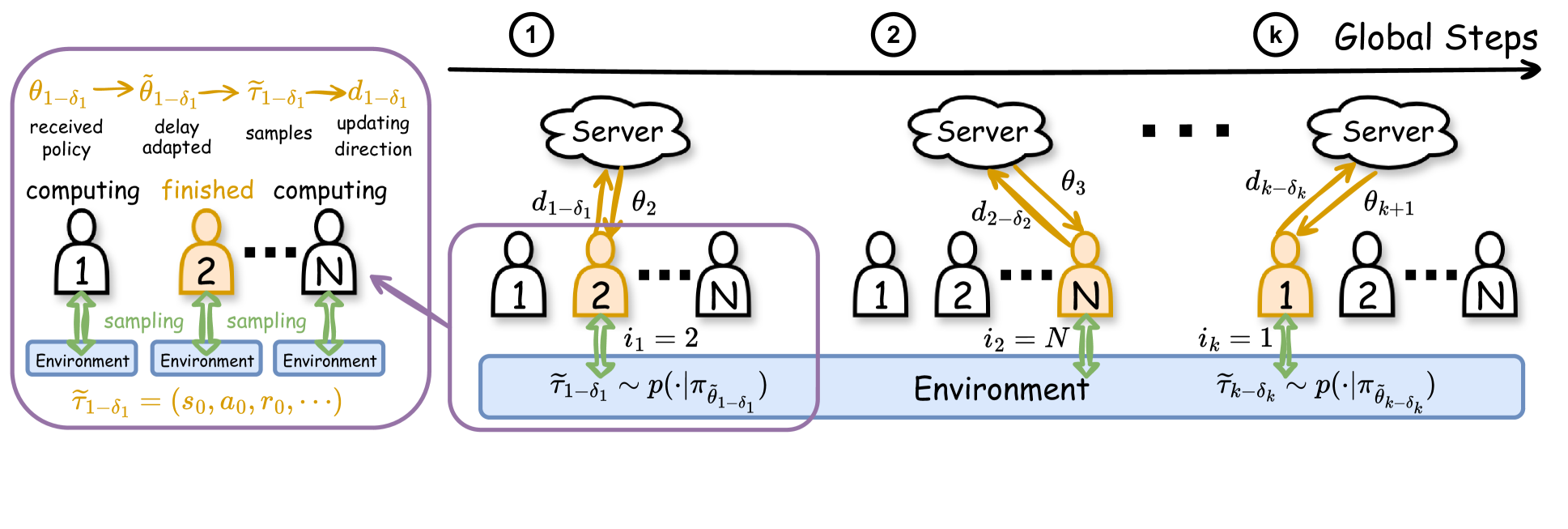
To improve the efficiency of reinforcement learning, we propose a novel asynchronous federated reinforcement learning framework termed AFedPG, which constructs a global model through collaboration among $N$ agents using policy gradient (PG) updates. To handle the challenge of lagged policies in asynchronous settings, we design delay-adaptive lookahead and normalized update techniques that can effectively handle the heterogeneous arrival times of policy gradients. We analyze the theoretical global convergence bound of AFedPG, and characterize the advantage of the proposed algorithm in terms of both the sample complexity and time complexity. Specifically, our AFedPG method achieves $mathcal{O}(frac{{epsilon}^{-2.5}}{N})$ sample complexity at each agent on average. Compared to the single agent setting with $mathcal{O}(epsilon^{-2.5})$ sample complexity, it enjoys a linear speedup with respect to the number of agents. Moreover, compared to synchronous FedPG, AFedPG improves the time complexity from $mathcal{O}(frac{t_{max}}{N})$ to $mathcal{O}(frac{1}{sum_{i=1}^{N} frac{1}{t_{i}}})$, where $t_{i}$ denotes the time consumption in each iteration at the agent $i$, and $t_{max}$ is the largest one. The latter complexity $mathcal{O}(frac{1}{sum_{i=1}^{N} frac{1}{t_{i}}})$ is always smaller than the former one, and this improvement becomes significant in large-scale federated settings with heterogeneous computing powers ($t_{max}gg t_{min}$). Finally, we empirically verify the improved performances of AFedPG in three MuJoCo environments with varying numbers of agents. We also demonstrate the improvements with different computing heterogeneity.
Read more4/16/2024
🌿
0
Federated Natural Policy Gradient and Actor Critic Methods for Multi-task Reinforcement Learning
Tong Yang, Shicong Cen, Yuting Wei, Yuxin Chen, Yuejie Chi
Federated reinforcement learning (RL) enables collaborative decision making of multiple distributed agents without sharing local data trajectories. In this work, we consider a multi-task setting, in which each agent has its own private reward function corresponding to different tasks, while sharing the same transition kernel of the environment. Focusing on infinite-horizon Markov decision processes, the goal is to learn a globally optimal policy that maximizes the sum of the discounted total rewards of all the agents in a decentralized manner, where each agent only communicates with its neighbors over some prescribed graph topology. We develop federated vanilla and entropy-regularized natural policy gradient (NPG) methods in the tabular setting under softmax parameterization, where gradient tracking is applied to estimate the global Q-function to mitigate the impact of imperfect information sharing. We establish non-asymptotic global convergence guarantees under exact policy evaluation, where the rates are nearly independent of the size of the state-action space and illuminate the impacts of network size and connectivity. To the best of our knowledge, this is the first time that near dimension-free global convergence is established for federated multi-task RL using policy optimization. We further go beyond the tabular setting by proposing a federated natural actor critic (NAC) method for multi-task RL with function approximation, and establish its finite-time sample complexity taking the errors of function approximation into account.
Read more8/19/2024
🏅
0
Federated Reinforcement Learning with Constraint Heterogeneity
Hao Jin, Liangyu Zhang, Zhihua Zhang
We study a Federated Reinforcement Learning (FedRL) problem with constraint heterogeneity. In our setting, we aim to solve a reinforcement learning problem with multiple constraints while $N$ training agents are located in $N$ different environments with limited access to the constraint signals and they are expected to collaboratively learn a policy satisfying all constraint signals. Such learning problems are prevalent in scenarios of Large Language Model (LLM) fine-tuning and healthcare applications. To solve the problem, we propose federated primal-dual policy optimization methods based on traditional policy gradient methods. Specifically, we introduce $N$ local Lagrange functions for agents to perform local policy updates, and these agents are then scheduled to periodically communicate on their local policies. Taking natural policy gradient (NPG) and proximal policy optimization (PPO) as policy optimization methods, we mainly focus on two instances of our algorithms, ie, {FedNPG} and {FedPPO}. We show that FedNPG achieves global convergence with an $tilde{O}(1/sqrt{T})$ rate, and FedPPO efficiently solves complicated learning tasks with the use of deep neural networks.
Read more5/7/2024