Beyond Performance Plateaus: A Comprehensive Study on Scalability in Speech Enhancement
2406.04269
0
0
Abstract
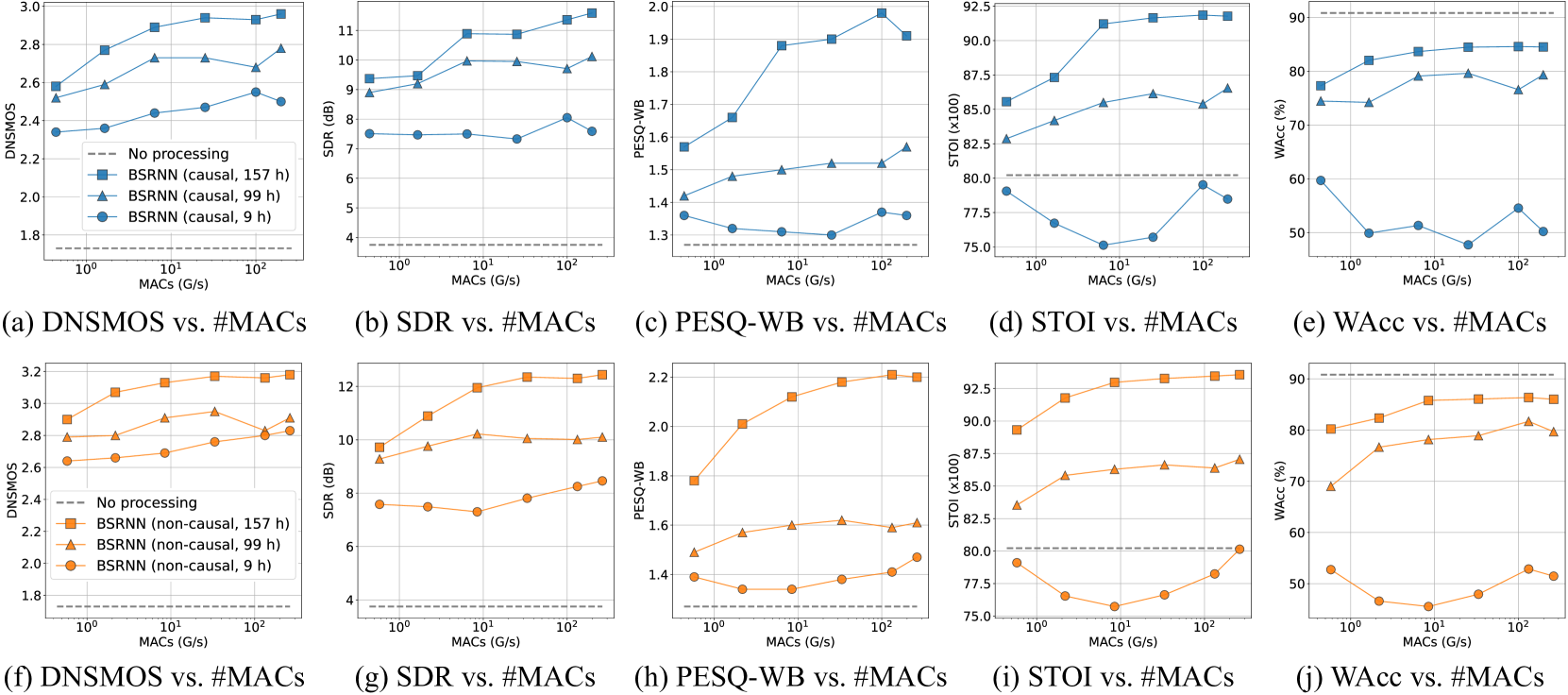
Deep learning-based speech enhancement (SE) models have achieved impressive performance in the past decade. Numerous advanced architectures have been designed to deliver state-of-the-art performance; however, their scalability potential remains unrevealed. Meanwhile, the majority of research focuses on small-sized datasets with restricted diversity, leading to a plateau in performance improvement. In this paper, we aim to provide new insights for addressing the above issues by exploring the scalability of SE models in terms of architectures, model sizes, compute budgets, and dataset sizes. Our investigation involves several popular SE architectures and speech data from different domains. Experiments reveal both similarities and distinctions between the scaling effects in SE and other tasks such as speech recognition. These findings further provide insights into the under-explored SE directions, e.g., larger-scale multi-domain corpora and efficiently scalable architectures.
Create account to get full access
Overview
- This paper presents a comprehensive study on the scalability of speech enhancement models, going beyond performance plateaus.
- The research explores the scalability of speech enhancement models as the model size and dataset size increase.
- The study examines the architectural choices and their impact on model performance and scalability.
- The findings offer insights into the design of efficient and scalable speech enhancement models, particularly for deployment on resource-constrained devices.
Plain English Explanation
This research paper looks at how well speech enhancement models can handle larger and more complex datasets. Speech enhancement is the process of improving the quality of audio recordings by reducing background noise and other distortions. As datasets and model sizes grow, the performance of these models can plateau, meaning they stop improving even as more resources are added.
The researchers in this study wanted to understand why this happens and how to design speech enhancement models that can continue improving as they get bigger. They tested different model architectures and training approaches to see how they impact performance and scalability. The goal was to find ways to create speech enhancement models that are efficient and can work well even on devices with limited resources, like smartphones or smart speakers.
The key insights from this research can help speech enhancement model developers design more powerful and flexible systems that can keep getting better as the data and models grow in size. This could lead to significant improvements in audio quality for a wide range of applications, from voice assistants to teleconferencing to hearing aids.
Technical Explanation
The paper presents a comprehensive study on the scalability of speech enhancement models, exploring how their performance changes as the model size and dataset size increase. The researchers examined different architectural choices and their impact on model performance and scalability.
The study utilized a variety of speech enhancement models, including those based on Scaling Properties of Speech and Language Models, Speech Enhancement with Deep Learning Architecture for Efficient Edge Deployment, Spiking Structured State-Space Model for Monaural Speech Enhancement, and A Lightweight Dual-Stage Framework for Personalized Speech Enhancement. The researchers also explored approaches like Enhancing CTC-based Speech Recognition with Diverse Modeling.
The experiments involved scaling the model size and dataset size to observe the impact on performance metrics such as speech quality, speech intelligibility, and computational efficiency. The findings provide insights into the design of efficient and scalable speech enhancement models, particularly for deployment on resource-constrained devices.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of the scalability of speech enhancement models. The researchers have explored a wide range of architectures and training approaches, offering valuable insights into the factors that contribute to model performance and scalability.
One potential limitation of the study is the reliance on standard evaluation metrics, which may not fully capture the nuances of speech quality and intelligibility as perceived by human listeners. Additionally, the paper does not delve into the potential trade-offs between model complexity, computational efficiency, and end-user experience, which could be an important consideration for real-world deployments.
Further research could investigate the impact of specialized hardware acceleration, such as the use of spiking neural networks or other neuromorphic computing approaches, on the scalability and efficiency of speech enhancement models. Additionally, exploring personalized or adaptable models that can cater to individual user preferences and hearing needs could be a fruitful area for future work.
Conclusion
This comprehensive study on the scalability of speech enhancement models offers important insights for the design of efficient and high-performing speech enhancement systems. The researchers have explored a range of architectural choices and their impact on model performance and scalability, providing a valuable resource for developers and researchers working in this field.
The findings from this study can inform the development of next-generation speech enhancement solutions that can continue to improve as datasets and model sizes grow, ultimately leading to enhanced audio quality and accessibility for a wide range of applications, from voice assistants to hearing aids. The critical analysis highlights areas for further research and development, paving the way for continued advancements in this important domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
Wangyou Zhang, Robin Scheibler, Kohei Saijo, Samuele Cornell, Chenda Li, Zhaoheng Ni, Anurag Kumar, Jan Pirklbauer, Marvin Sach, Shinji Watanabe, Tim Fingscheidt, Yanmin Qian
0
0
The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
6/10/2024
Scaling Properties of Speech Language Models
Santiago Cuervo, Ricard Marxer
0
0
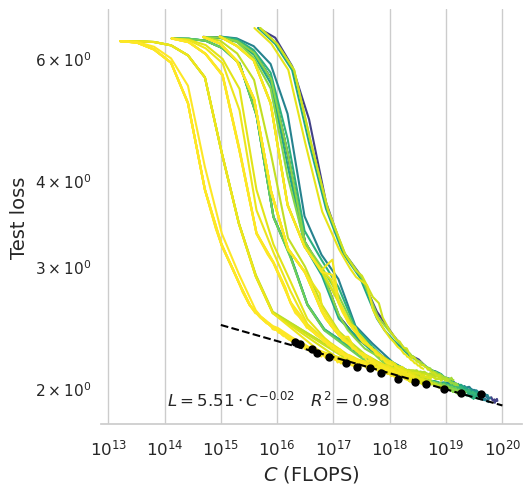
Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
4/17/2024
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
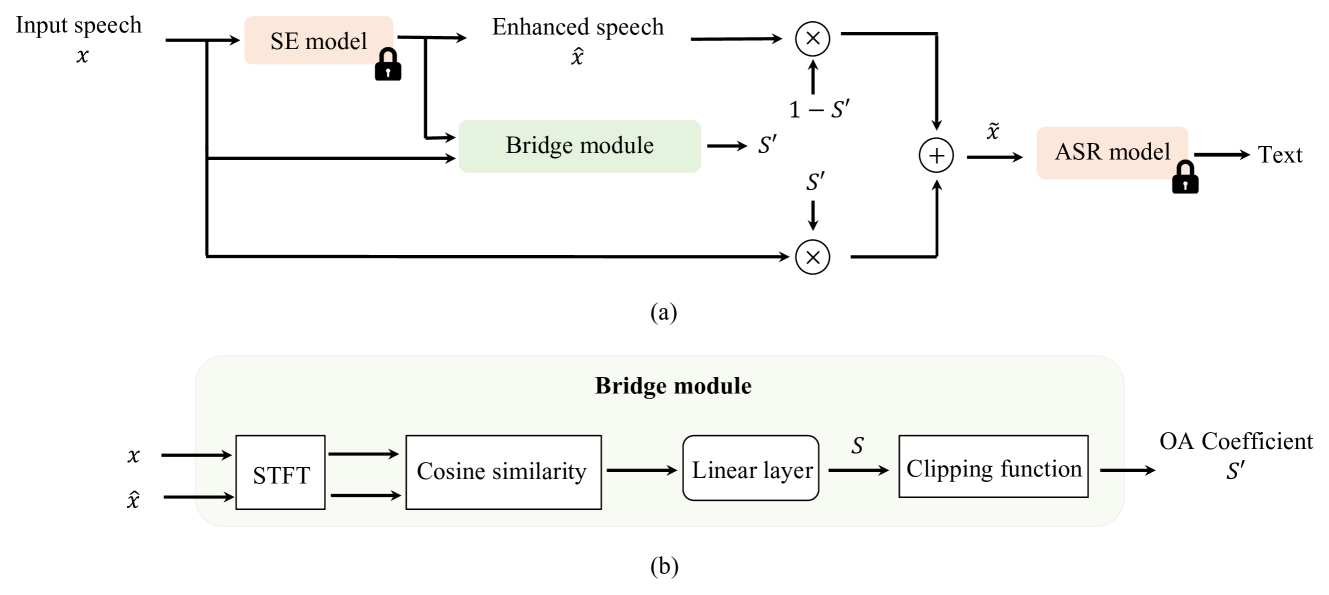
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024
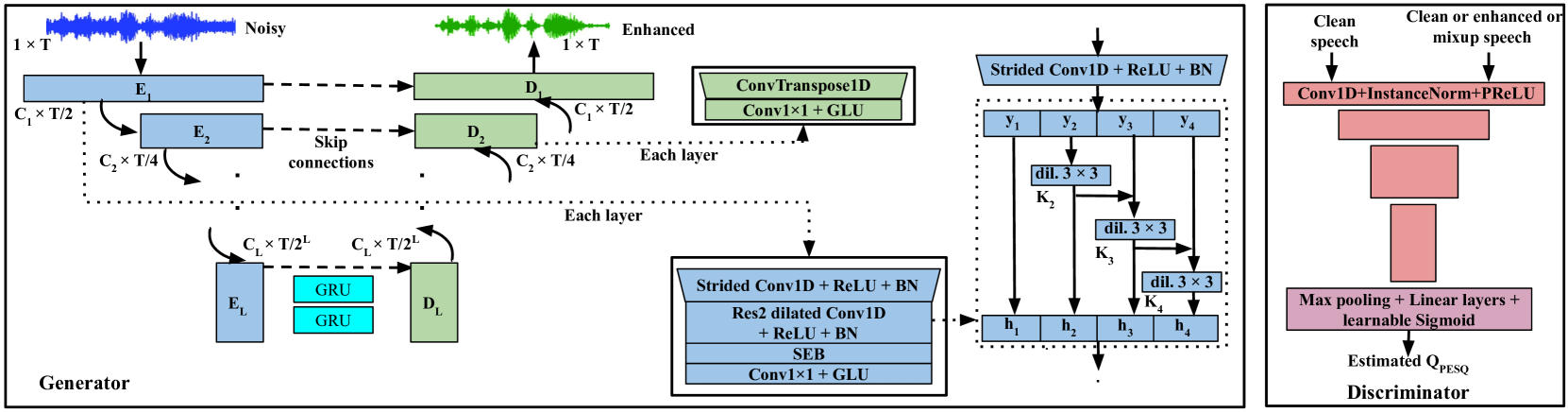
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
0
0
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
5/28/2024