Towards Interpretable Reinforcement Learning with Constrained Normalizing Flow Policies

0

Sign in to get full access
Overview
- This paper presents a novel reinforcement learning (RL) algorithm that uses constrained normalizing flow policies to improve the interpretability of RL agents.
- The approach aims to learn more transparent and understandable policies by constraining the policy distribution to a specific family of distributions known as normalizing flows.
- The authors demonstrate the effectiveness of their method on several benchmark RL tasks and show that the learned policies are more interpretable than standard RL policies.
Plain English Explanation
In reinforcement learning, agents learn to make decisions by interacting with an environment and receiving rewards or penalties. However, the policies (decision-making strategies) learned by standard RL algorithms can be opaque and difficult for humans to understand.
The researchers in this paper developed a new RL algorithm that addresses this issue. Their approach uses a special type of policy called a "constrained normalizing flow policy." This policy is more interpretable because it is restricted to a particular family of mathematical functions called normalizing flows, which have a special structure that makes them easier to understand.
By constraining the policy in this way, the algorithm learns policies that are more transparent and can be more easily explained to humans. The authors show that their method performs well on several standard RL benchmark tasks, while also producing policies that are more interpretable than those learned by traditional RL algorithms.
This work is part of a broader effort to make RL systems more interpretable and explainable, which is an important goal for deploying RL in real-world applications where understanding the agent's decision-making process is crucial.
Technical Explanation
The key technical innovation in this paper is the use of constrained normalizing flow policies for reinforcement learning. Normalizing flows are a class of flexible probability distributions that can be used to represent complex, high-dimensional data. By constraining the RL policy to be a normalizing flow, the authors ensure that the policy has a specific mathematical structure that makes it more interpretable.
Specifically, the authors propose an RL algorithm that learns a constrained normalizing flow policy by maximizing the expected return while also minimizing the Kullback-Leibler (KL) divergence between the policy and a reference normalizing flow distribution. This encourages the policy to stay close to the reference distribution, which helps maintain interpretability.
The authors evaluate their method on several benchmark RL tasks, including Mujoco locomotion and Atari games. They show that their constrained normalizing flow policies achieve comparable performance to standard RL policies, while also providing more interpretable representations of the agent's decision-making process.
Critical Analysis
The authors present a compelling approach for improving the interpretability of RL agents, which is an important and timely challenge in the field. By constraining the policy to a specific family of distributions, they are able to produce policies that are more transparent and easier for humans to understand.
However, the paper does not address some potential limitations of the approach. For example, the choice of reference distribution for the KL divergence constraint may have a significant impact on the interpretability of the learned policies, but this is not explored in depth.
Additionally, the authors only evaluate their method on a limited set of benchmark tasks, and it would be valuable to see how it performs on more complex, real-world problems where interpretability may be even more crucial. Further research is needed to fully understand the strengths and weaknesses of this approach compared to other interpretable RL methods.
Conclusion
This paper presents a novel RL algorithm that uses constrained normalizing flow policies to improve the interpretability of RL agents. By restricting the policy to a specific family of distributions, the authors are able to produce policies that are more transparent and easier for humans to understand, while still achieving strong performance on benchmark tasks.
This work is an important step towards making RL systems more interpretable and explainable, which is crucial for deploying RL in real-world applications where understanding the agent's decision-making process is essential. Further research is needed to fully explore the potential of this approach and address its limitations, but the authors have made a valuable contribution to the field of interpretable RL.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Interpretable Reinforcement Learning with Constrained Normalizing Flow Policies
Finn Rietz, Erik Schaffernicht, Stefan Heinrich, Johannes A. Stork
Reinforcement learning policies are typically represented by black-box neural networks, which are non-interpretable and not well-suited for safety-critical domains. To address both of these issues, we propose constrained normalizing flow policies as interpretable and safe-by-construction policy models. We achieve safety for reinforcement learning problems with instantaneous safety constraints, for which we can exploit domain knowledge by analytically constructing a normalizing flow that ensures constraint satisfaction. The normalizing flow corresponds to an interpretable sequence of transformations on action samples, each ensuring alignment with respect to a particular constraint. Our experiments reveal benefits beyond interpretability in an easier learning objective and maintained constraint satisfaction throughout the entire learning process. Our approach leverages constraints over reward engineering while offering enhanced interpretability, safety, and direct means of providing domain knowledge to the agent without relying on complex reward functions.
Read more5/3/2024
0
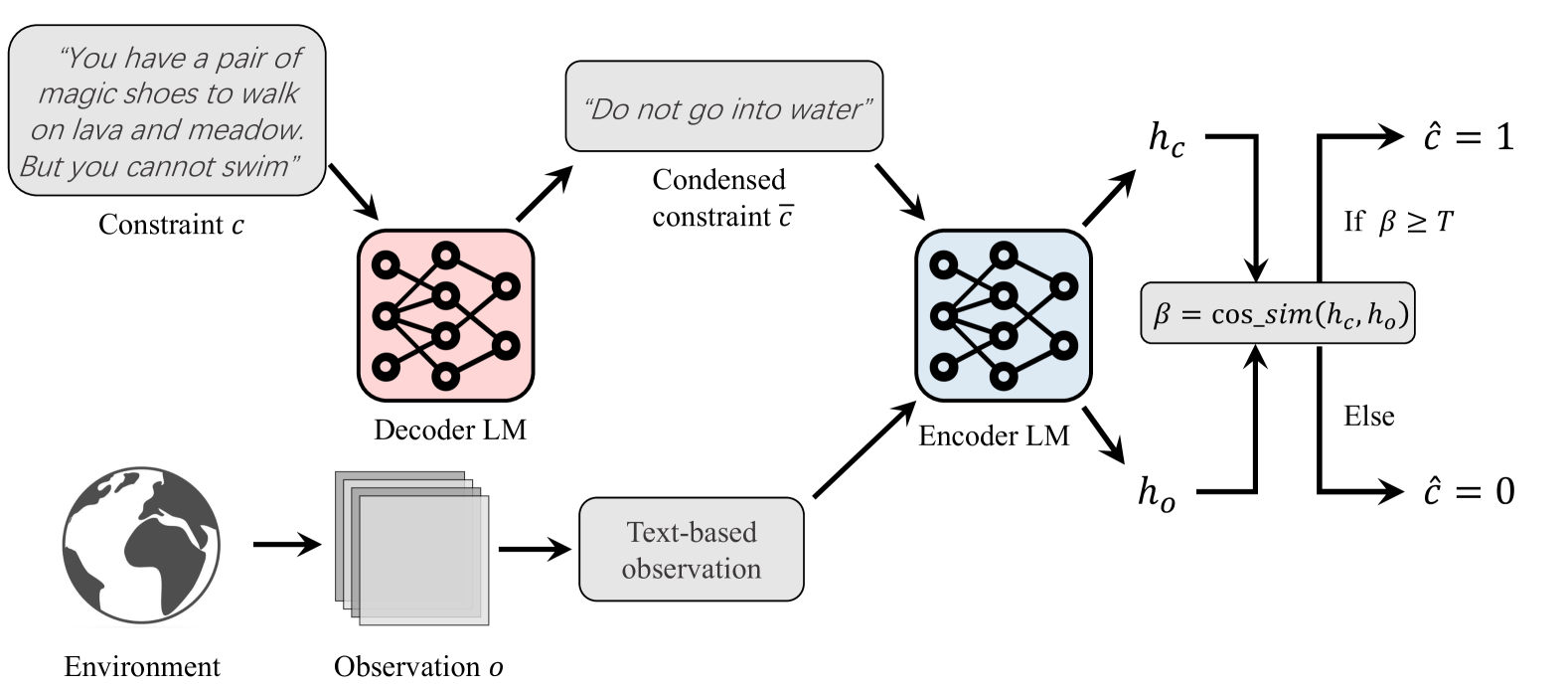
Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
Xingzhou Lou, Junge Zhang, Ziyan Wang, Kaiqi Huang, Yali Du
Safe reinforcement learning (RL) agents accomplish given tasks while adhering to specific constraints. Employing constraints expressed via easily-understandable human language offers considerable potential for real-world applications due to its accessibility and non-reliance on domain expertise. Previous safe RL methods with natural language constraints typically adopt a recurrent neural network, which leads to limited capabilities when dealing with various forms of human language input. Furthermore, these methods often require a ground-truth cost function, necessitating domain expertise for the conversion of language constraints into a well-defined cost function that determines constraint violation. To address these issues, we proposes to use pre-trained language models (LM) to facilitate RL agents' comprehension of natural language constraints and allow them to infer costs for safe policy learning. Through the use of pre-trained LMs and the elimination of the need for a ground-truth cost, our method enhances safe policy learning under a diverse set of human-derived free-form natural language constraints. Experiments on grid-world navigation and robot control show that the proposed method can achieve strong performance while adhering to given constraints. The usage of pre-trained LMs allows our method to comprehend complicated constraints and learn safe policies without the need for ground-truth cost at any stage of training or evaluation. Extensive ablation studies are conducted to demonstrate the efficacy of each part of our method.
Read more5/16/2024
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024
🏅
0
Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
Chen-Hao Chao, Chien Feng, Wei-Fang Sun, Cheng-Kuang Lee, Simon See, Chun-Yi Lee
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
Read more5/24/2024