Towards Realistic Synthetic User-Generated Content: A Scaffolding Approach to Generating Online Discussions

0

Sign in to get full access
Overview
- The paper presents a novel approach to generating realistic synthetic user-generated content (UGC), such as online discussions, using a scaffolding technique.
- The goal is to create a system that can generate synthetic data that closely mimics the characteristics and patterns of real UGC, which can be useful for various applications like training machine learning models.
- The authors propose a multi-stage process that combines large language models (LLMs) with additional scaffolding techniques to produce more realistic and coherent synthetic discussions.
Plain English Explanation
The researchers wanted to find a way to create realistic artificial online conversations that look and feel like real human-written content. This is important because these kinds of synthetic datasets can be used to train machine learning models without needing to use actual private user data.
To do this, the team developed a multi-step process that builds on the capabilities of large language models (LLMs) - powerful AI systems that can generate human-like text. They added additional "scaffolding" techniques on top of the LLM to make the synthetic discussions even more realistic and coherent, following best practices for synthetic data generation.
The end result is a system that can generate massive amounts of synthetic online conversations that closely mimic the characteristics of real user-generated content, without needing to collect or use actual user data. This has many potential applications, such as training better AI systems for online moderation, recommendation engines, and more.
Technical Explanation
The paper proposes a scaffolding approach to generating realistic synthetic user-generated content (UGC), focusing on online discussions as the main use case. The key elements of their approach include:
-
Large Language Model (LLM) Generation: The process starts by using a state-of-the-art LLM to generate initial synthetic discussion threads based on prompts.
-
Scaffolding Techniques:
- Persona Modeling: The researchers create synthetic user personas with distinct writing styles, topical interests, and conversational patterns.
- Discourse Structure Modeling: They model the hierarchical structure of discussion threads, including reply-to relationships and conversational flow.
- Coherence Modeling: Additional techniques are used to improve the overall coherence and consistency of the generated discussions.
-
Multi-Stage Generation: The system goes through several iterations, applying the scaffolding techniques to refine and improve the realism of the synthetic discussions.
The authors evaluate their approach using both automatic metrics and human evaluations, demonstrating that the resulting synthetic discussions exhibit more realistic characteristics compared to those generated by the LLM alone or other baselines.
Critical Analysis
The paper presents a compelling approach to generating realistic synthetic UGC, and the proposed scaffolding techniques seem promising. However, the authors acknowledge several limitations and areas for future research:
- The evaluation is focused on a specific domain (online discussions) and may not generalize well to other types of UGC.
- The synthetic personas and discourse structures are still relatively simple compared to the complex patterns observed in real-world data.
- The authors note that further work is needed to ensure the generated content is sufficiently diverse and avoids potential biases or harmful content.
Additionally, while the paper demonstrates the potential of this approach, there are still open questions around the broader implications and ethical considerations of using synthetic data, especially at scale. Responsible development and deployment of such technologies will be crucial.
Conclusion
This paper presents an innovative scaffolding approach to generating realistic synthetic user-generated content, focusing on the specific domain of online discussions. By combining the power of large language models with additional techniques to model user personas, discourse structure, and coherence, the researchers have developed a system that can produce synthetic data that more closely mimics the characteristics of real-world UGC.
The potential applications of this work are significant, as synthetic data can be used to train and evaluate various AI systems without the need for collecting and using actual user data. However, the authors highlight the need for further research to address the limitations and ensure the responsible development and deployment of such technologies.
Overall, this paper represents an important step forward in the field of synthetic data generation, with promising implications for advancing the state of the art in machine learning and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Realistic Synthetic User-Generated Content: A Scaffolding Approach to Generating Online Discussions
Krisztian Balog, John Palowitch, Barbara Ikica, Filip Radlinski, Hamidreza Alvari, Mehdi Manshadi
The emergence of synthetic data represents a pivotal shift in modern machine learning, offering a solution to satisfy the need for large volumes of data in domains where real data is scarce, highly private, or difficult to obtain. We investigate the feasibility of creating realistic, large-scale synthetic datasets of user-generated content, noting that such content is increasingly prevalent and a source of frequently sought information. Large language models (LLMs) offer a starting point for generating synthetic social media discussion threads, due to their ability to produce diverse responses that typify online interactions. However, as we demonstrate, straightforward application of LLMs yields limited success in capturing the complex structure of online discussions, and standard prompting mechanisms lack sufficient control. We therefore propose a multi-step generation process, predicated on the idea of creating compact representations of discussion threads, referred to as scaffolds. Our framework is generic yet adaptable to the unique characteristics of specific social media platforms. We demonstrate its feasibility using data from two distinct online discussion platforms. To address the fundamental challenge of ensuring the representativeness and realism of synthetic data, we propose a portfolio of evaluation measures to compare various instantiations of our framework.
Read more8/19/2024

0
The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
Stefan Sylvius Wagner, Maike Behrendt, Marc Ziegele, Stefan Harmeling
Stance detection holds great potential for enhancing the quality of online political discussions, as it has shown to be useful for summarizing discussions, detecting misinformation, and evaluating opinion distributions. Usually, transformer-based models are used directly for stance detection, which require large amounts of data. However, the broad range of debate questions in online political discussion creates a variety of possible scenarios that the model is faced with and thus makes data acquisition for model training difficult. In this work, we show how to leverage LLM-generated synthetic data to train and improve stance detection agents for online political discussions:(i) We generate synthetic data for specific debate questions by prompting a Mistral-7B model and show that fine-tuning with the generated synthetic data can substantially improve the performance of stance detection. (ii) We examine the impact of combining synthetic data with the most informative samples from an unlabelled dataset. First, we use the synthetic data to select the most informative samples, second, we combine both these samples and the synthetic data for fine-tuning. This approach reduces labelling effort and consistently surpasses the performance of the baseline model that is trained with fully labeled data. Overall, we show in comprehensive experiments that LLM-generated data greatly improves stance detection performance for online political discussions.
Read more6/19/2024
0
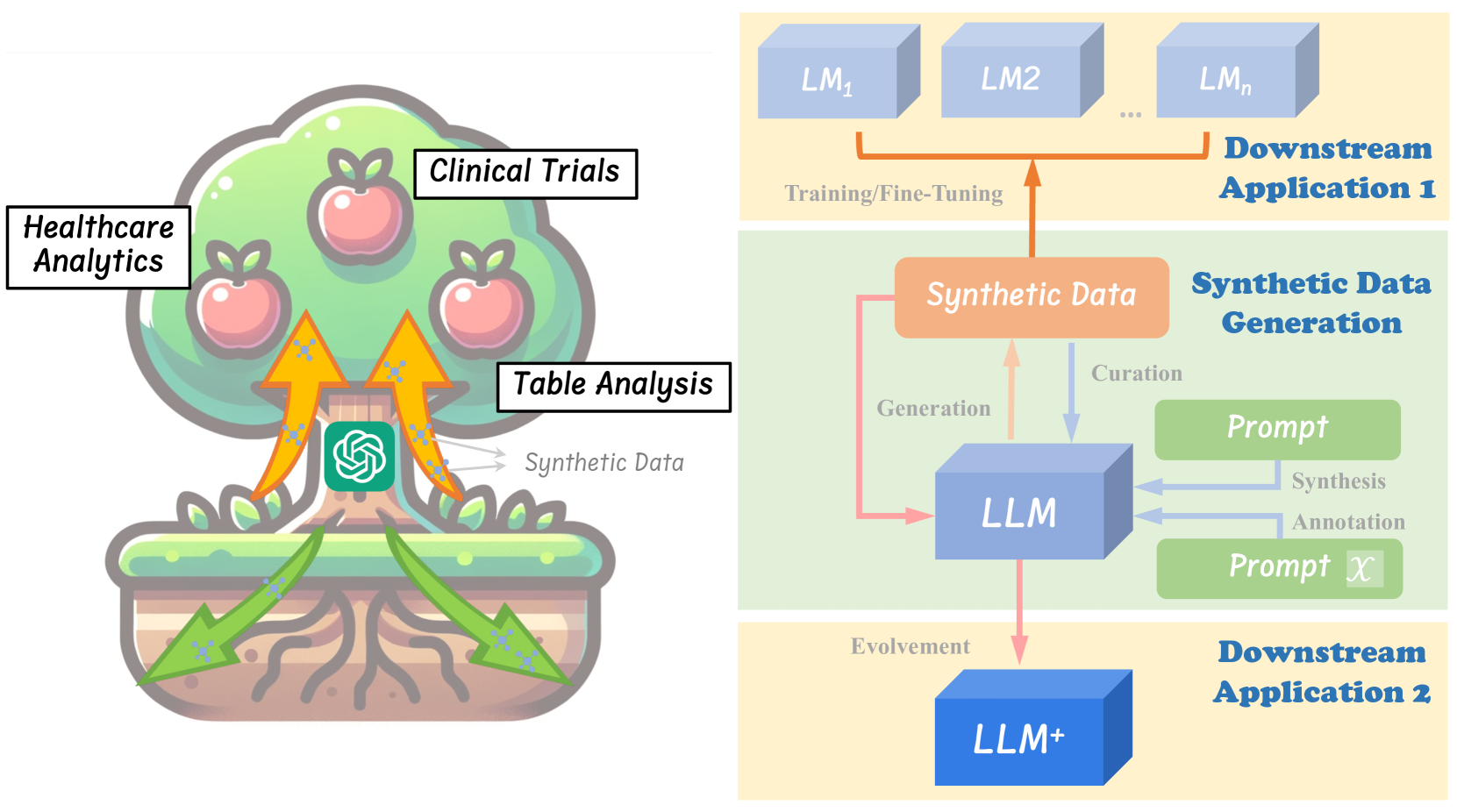
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024
0
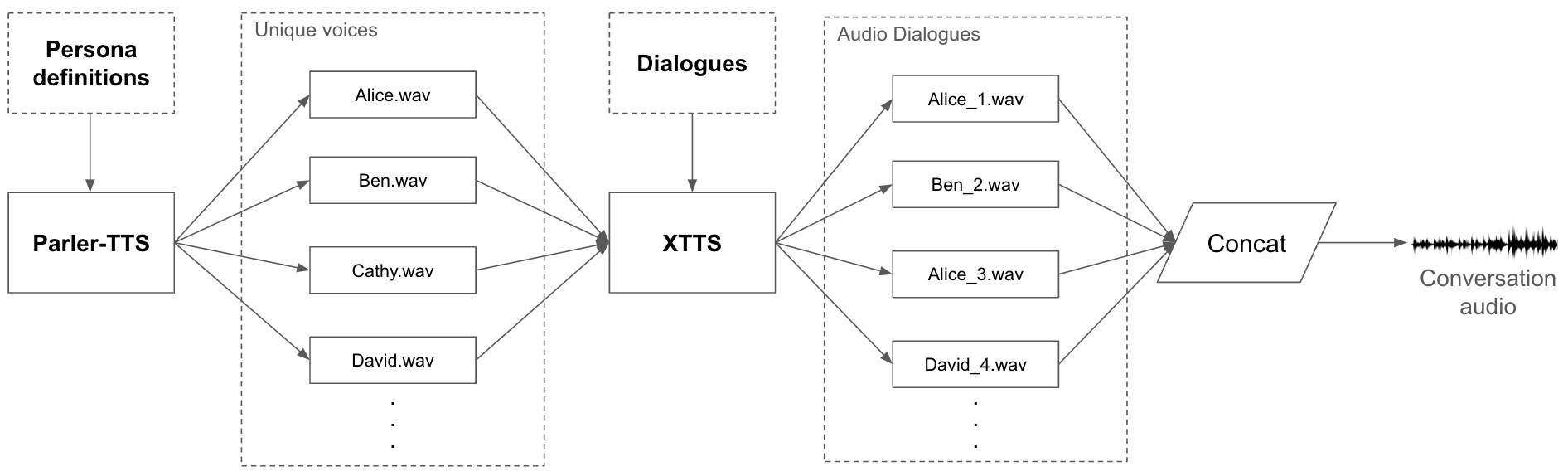
A Framework for Synthetic Audio Conversations Generation using Large Language Models
Kaung Myat Kyaw, Jonathan Hoyin Chan
In this paper, we introduce ConversaSynth, a framework designed to generate synthetic conversation audio using large language models (LLMs) with multiple persona settings. The framework first creates diverse and coherent text-based dialogues across various topics, which are then converted into audio using text-to-speech (TTS) systems. Our experiments demonstrate that ConversaSynth effectively generates highquality synthetic audio datasets, which can significantly enhance the training and evaluation of models for audio tagging, audio classification, and multi-speaker speech recognition. The results indicate that the synthetic datasets generated by ConversaSynth exhibit substantial diversity and realism, making them suitable for developing robust, adaptable audio-based AI systems.
Read more9/4/2024