Toward Evaluating Robustness of Reinforcement Learning with Adversarial Policy
2305.02605
0
0
🏅
Abstract
Reinforcement learning agents are susceptible to evasion attacks during deployment. In single-agent environments, these attacks can occur through imperceptible perturbations injected into the inputs of the victim policy network. In multi-agent environments, an attacker can manipulate an adversarial opponent to influence the victim policy's observations indirectly. While adversarial policies offer a promising technique to craft such attacks, current methods are either sample-inefficient due to poor exploration strategies or require extra surrogate model training under the black-box assumption. To address these challenges, in this paper, we propose Intrinsically Motivated Adversarial Policy (IMAP) for efficient black-box adversarial policy learning in both single- and multi-agent environments. We formulate four types of adversarial intrinsic regularizers -- maximizing the adversarial state coverage, policy coverage, risk, or divergence -- to discover potential vulnerabilities of the victim policy in a principled way. We also present a novel bias-reduction method to balance the extrinsic objective and the adversarial intrinsic regularizers adaptively. Our experiments validate the effectiveness of the four types of adversarial intrinsic regularizers and the bias-reduction method in enhancing black-box adversarial policy learning across a variety of environments. Our IMAP successfully evades two types of defense methods, adversarial training and robust regularizer, decreasing the performance of the state-of-the-art robust WocaR-PPO agents by 34%-54% across four single-agent tasks. IMAP also achieves a state-of-the-art attacking success rate of 83.91% in the multi-agent game YouShallNotPass. Our code is available at url{https://github.com/x-zheng16/IMAP}.
Create account to get full access
Overview
- Reinforcement learning agents are vulnerable to adversarial attacks during deployment
- In single-agent environments, these attacks can occur through imperceptible modifications to the agent's inputs
- In multi-agent environments, an attacker can manipulate an opposing agent to indirectly influence the victim agent's observations
- Current adversarial policy methods are either inefficient or require additional surrogate model training under a black-box assumption
- To address these challenges, the authors propose Intrinsically Motivated Adversarial Policy (IMAP) for efficient black-box adversarial policy learning in single- and multi-agent settings
Plain English Explanation
Reinforcement learning (RL) is a type of machine learning where agents learn to make decisions by interacting with their environment and receiving rewards or penalties. However, these RL agents can be vulnerable to adversarial attacks during real-world deployment.
In single-agent environments, an attacker can make tiny, imperceptible changes to the inputs the agent receives, which can cause the agent to make completely different decisions. In multi-agent environments, an attacker can manipulate an opposing agent's behavior to indirectly influence the victim agent's observations and decision-making.
While adversarial policies offer a way to craft such attacks, current methods have limitations. Some are inefficient because they struggle to explore the search space effectively, while others require training an additional surrogate model, which is challenging in a black-box setting.
To address these issues, the researchers developed a new approach called Intrinsically Motivated Adversarial Policy (IMAP). IMAP uses four types of adversarial intrinsic regularizers to help the adversarial agent discover vulnerabilities in the victim agent's policy in a more principled way. IMAP also includes a novel bias-reduction method to balance the adversarial objective with the original task objective.
Technical Explanation
The authors propose the Intrinsically Motivated Adversarial Policy (IMAP) framework for efficient black-box adversarial policy learning in both single-agent and multi-agent environments.
IMAP introduces four types of adversarial intrinsic regularizers to guide the discovery of potential vulnerabilities in the victim policy:
- Maximizing adversarial state coverage: Encouraging the adversary to visit a diverse set of states to find weaknesses.
- Maximizing policy coverage: Encouraging the adversary to induce a diverse set of actions from the victim.
- Maximizing risk: Encouraging the adversary to find states where the victim policy has high uncertainty or risk.
- Maximizing divergence: Encouraging the adversary to find states where the victim policy's output deviates significantly from the optimal policy.
The authors also present a novel bias-reduction method to adaptively balance the extrinsic objective (e.g., winning the game) and the adversarial intrinsic regularizers during training.
The researchers evaluate IMAP across a variety of single-agent and multi-agent environments. In the single-agent tasks, IMAP successfully evades two types of defense methods (adversarial training and robust regularizer), decreasing the performance of state-of-the-art robust agents by 34%-54%. In the multi-agent game YouShallNotPass, IMAP achieves a state-of-the-art attacking success rate of 83.91%.
Critical Analysis
The paper presents a compelling approach to crafting efficient black-box adversarial policies against reinforcement learning agents in both single-agent and multi-agent settings. The proposed adversarial intrinsic regularizers provide a principled way to guide the discovery of vulnerabilities in the victim policy, going beyond previous methods that relied on more ad-hoc exploration strategies.
However, the paper does not address some potential limitations and areas for further research. For example, the authors do not discuss the robustness of the IMAP approach to changes in the environment or the victim policy. It would be interesting to see how well IMAP generalizes to new settings or if the discovered vulnerabilities are specific to the training conditions.
Additionally, the privacy implications of adversarial policies are not fully explored. While the paper focuses on the technical aspects of the attack, the ethical considerations and potential societal impact of such techniques could be an important area for future work.
Conclusion
The Intrinsically Motivated Adversarial Policy (IMAP) framework proposed in this paper represents a significant advancement in the field of adversarial policy learning for reinforcement learning agents. By introducing principled adversarial intrinsic regularizers and a bias-reduction method, the authors have developed an efficient black-box approach to discovering vulnerabilities in both single-agent and multi-agent environments.
The success of IMAP in evading state-of-the-art defense methods highlights the potential risks posed by such adversarial attacks during the real-world deployment of reinforcement learning systems. As the capabilities of these systems continue to grow, it will be crucial for researchers and practitioners to carefully consider the security and robustness of these agents, as well as the broader ethical implications of adversarial techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
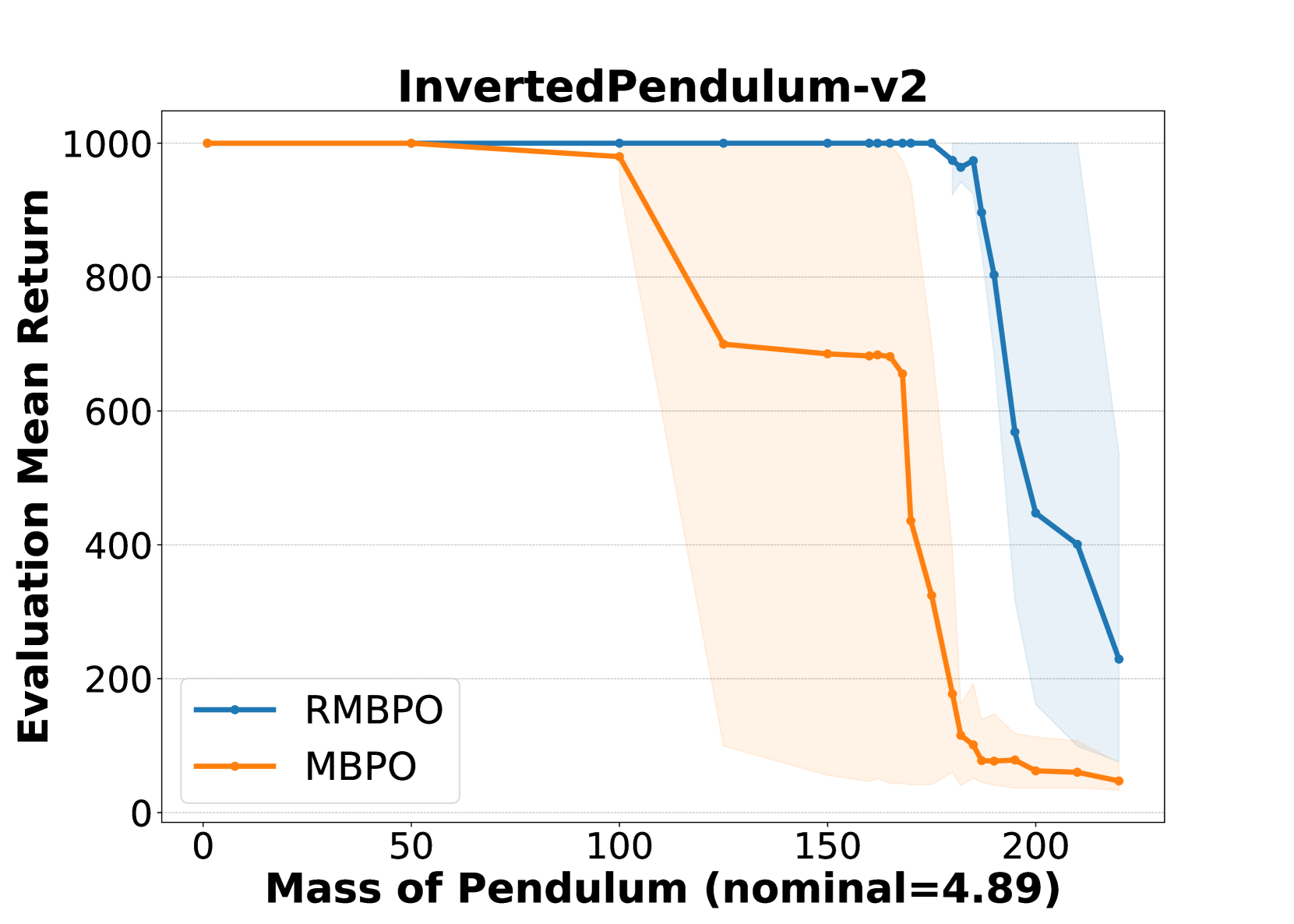
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
7/2/2024

Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
Thanh Nguyen, Tung M. Luu, Tri Ton, Chang D. Yoo
0
0
Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.
5/21/2024

Behavior-Targeted Attack on Reinforcement Learning with Limited Access to Victim's Policy
Shojiro Yamabe, Kazuto Fukuchi, Ryoma Senda, Jun Sakuma
0
0
This study considers the attack on reinforcement learning agents where the adversary aims to control the victim's behavior as specified by the adversary by adding adversarial modifications to the victim's state observation. While some attack methods reported success in manipulating the victim agent's behavior, these methods often rely on environment-specific heuristics. In addition, all existing attack methods require white-box access to the victim's policy. In this study, we propose a novel method for manipulating the victim agent in the black-box (i.e., the adversary is allowed to observe the victim's state and action only) and no-box (i.e., the adversary is allowed to observe the victim's state only) setting without requiring environment-specific heuristics. Our attack method is formulated as a bi-level optimization problem that is reduced to a distribution matching problem and can be solved by an existing imitation learning algorithm in the black-box and no-box settings. Empirical evaluations on several reinforcement learning benchmarks show that our proposed method has superior attack performance to baselines.
6/7/2024

Robust Deep Reinforcement Learning with Adaptive Adversarial Perturbations in Action Space
Qianmei Liu, Yufei Kuang, Jie Wang
0
0
Deep reinforcement learning (DRL) algorithms can suffer from modeling errors between the simulation and the real world. Many studies use adversarial learning to generate perturbation during training process to model the discrepancy and improve the robustness of DRL. However, most of these approaches use a fixed parameter to control the intensity of the adversarial perturbation, which can lead to a trade-off between average performance and robustness. In fact, finding the optimal parameter of the perturbation is challenging, as excessive perturbations may destabilize training and compromise agent performance, while insufficient perturbations may not impart enough information to enhance robustness. To keep the training stable while improving robustness, we propose a simple but effective method, namely, Adaptive Adversarial Perturbation (A2P), which can dynamically select appropriate adversarial perturbations for each sample. Specifically, we propose an adaptive adversarial coefficient framework to adjust the effect of the adversarial perturbation during training. By designing a metric for the current intensity of the perturbation, our method can calculate the suitable perturbation levels based on the current relative performance. The appealing feature of our method is that it is simple to deploy in real-world applications and does not require accessing the simulator in advance. The experiments in MuJoCo show that our method can improve the training stability and learn a robust policy when migrated to different test environments. The code is available at https://github.com/Lqm00/A2P-SAC.
5/21/2024