Transferable and Principled Efficiency for Open-Vocabulary Segmentation
2404.07448
0
0

Abstract
Recent success of pre-trained foundation vision-language models makes Open-Vocabulary Segmentation (OVS) possible. Despite the promising performance, this approach introduces heavy computational overheads for two challenges: 1) large model sizes of the backbone; 2) expensive costs during the fine-tuning. These challenges hinder this OVS strategy from being widely applicable and affordable in real-world scenarios. Although traditional methods such as model compression and efficient fine-tuning can address these challenges, they often rely on heuristics. This means that their solutions cannot be easily transferred and necessitate re-training on different models, which comes at a cost. In the context of efficient OVS, we target achieving performance that is comparable to or even better than prior OVS works based on large vision-language foundation models, by utilizing smaller models that incur lower training costs. The core strategy is to make our efficiency principled and thus seamlessly transferable from one OVS framework to others without further customization. Comprehensive experiments on diverse OVS benchmarks demonstrate our superior trade-off between segmentation accuracy and computation costs over previous works. Our code is available on https://github.com/Xujxyang/OpenTrans
Create account to get full access
Overview
- This paper introduces a new approach for open-vocabulary semantic segmentation, which allows for segmenting objects in images using any textual description, rather than being limited to a predefined set of categories.
- The proposed method leverages a vision-language pre-training model to enable efficient and transferable open-vocabulary segmentation, without requiring per-category training or fine-tuning.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing it can outperform previous open-vocabulary segmentation methods while being more efficient and generalizable.
Plain English Explanation
The paper discusses a new way to do "semantic segmentation," which is the task of identifying and outlining different objects in an image. Typically, semantic segmentation models are trained to recognize a fixed set of object categories, like "car," "person," or "dog." However, this paper introduces a method that can segment objects using any textual description, not just the pre-defined categories.
This is enabled by using a "vision-language pre-training model," which is a type of AI model that has been trained on a large amount of image and text data. This allows the model to understand the relationship between visual elements and language, so it can segment objects based on free-form textual descriptions, rather than being limited to a fixed set of classes.
The key advantage of this approach is that it is more flexible and efficient. Rather than having to train a separate segmentation model for each new object category, the pre-trained vision-language model can be directly applied to segment objects based on any textual prompt. The authors show that this method outperforms previous open-vocabulary segmentation techniques, while also being more computationally efficient.
Technical Explanation
The paper introduces a novel approach for open-vocabulary semantic segmentation, which allows for segmenting objects in images using any textual description, rather than being limited to a predefined set of categories. The proposed method leverages a vision-language pre-training model to enable efficient and transferable open-vocabulary segmentation, without requiring per-category training or fine-tuning.
The key components of the approach are:
- A vision-language pre-training model that can encode both visual and textual inputs into a shared embedding space.
- A segmentation head that takes the vision-language embeddings and outputs a segmentation mask for the given textual prompt.
- A training procedure that optimizes the model to accurately segment objects based on diverse textual descriptions, without overfitting to specific categories.
The authors evaluate their method on several benchmark datasets, including 3D object segmentation and open-vocabulary food segmentation. They show that their approach can outperform previous open-vocabulary segmentation methods while being more efficient and generalizable, thanks to the transferable knowledge learned during pre-training.
Critical Analysis
The paper presents a compelling approach for open-vocabulary segmentation, which addresses an important limitation of traditional segmentation models that are restricted to a fixed set of object categories. The authors' use of a vision-language pre-training model is a clever way to enable more flexible and efficient segmentation, as it allows the model to leverage its general understanding of the visual-linguistic relationship, rather than requiring per-category training.
That said, the paper does not extensively discuss the potential limitations or caveats of the proposed method. For example, it is unclear how the performance and efficiency of the approach would scale as the number of possible textual prompts increases, or how robust the segmentation quality is to more complex or ambiguous language inputs.
Additionally, while the authors demonstrate the effectiveness of their method on several benchmark datasets, it would be valuable to see an analysis of its real-world applicability and the types of use cases where it would provide the most benefit. Open-vocabulary keyword spotting and online open-vocabulary mapping are two related areas that could potentially benefit from the techniques introduced in this paper.
Overall, the paper makes a valuable contribution to the field of open-vocabulary segmentation, but further research and analysis would be needed to fully understand the strengths, limitations, and practical implications of the proposed approach.
Conclusion
This paper presents a novel method for open-vocabulary semantic segmentation that leverages a vision-language pre-training model to enable efficient and transferable object segmentation using any textual description. The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing it can outperform previous open-vocabulary segmentation techniques while being more computationally efficient.
The key innovation of this work is the use of a vision-language pre-training model, which allows the segmentation model to leverage its general understanding of the visual-linguistic relationship, rather than requiring per-category training or fine-tuning. This makes the approach more flexible and scalable, as it can be applied to segment objects based on diverse textual prompts without the need for extensive retraining.
While the paper does not extensively explore the potential limitations or real-world applicability of the proposed method, it represents an important step forward in the field of open-vocabulary segmentation, with potential implications for a wide range of computer vision and language-based applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, and Future
Chaoyang Zhu, Long Chen
0
0
As the most fundamental scene understanding tasks, object detection and segmentation have made tremendous progress in deep learning era. Due to the expensive manual labeling cost, the annotated categories in existing datasets are often small-scale and pre-defined, i.e., state-of-the-art fully-supervised detectors and segmentors fail to generalize beyond the closed vocabulary. To resolve this limitation, in the last few years, the community has witnessed an increasing attention toward Open-Vocabulary Detection (OVD) and Segmentation (OVS). By ``open-vocabulary'', we mean that the models can classify objects beyond pre-defined categories. In this survey, we provide a comprehensive review on recent developments of OVD and OVS. A taxonomy is first developed to organize different tasks and methodologies. We find that the permission and usage of weak supervision signals can well discriminate different methodologies, including: visual-semantic space mapping, novel visual feature synthesis, region-aware training, pseudo-labeling, knowledge distillation, and transfer learning. The proposed taxonomy is universal across different tasks, covering object detection, semantic/instance/panoptic segmentation, 3D and video understanding. The main design principles, key challenges, development routes, methodology strengths, and weaknesses are thoroughly analyzed. In addition, we benchmark each task along with the vital components of each method in appendix and updated online at https://github.com/seanzhuh/awesome-open-vocabulary-detection-and-segmentation. Finally, several promising directions are provided and discussed to stimulate future research.
4/16/2024

Understanding Multi-Granularity for Open-Vocabulary Part Segmentation
Jiho Choi, Seonho Lee, Seungho Lee, Minhyun Lee, Hyunjung Shim
0
0
Open-vocabulary part segmentation (OVPS) is an emerging research area focused on segmenting fine-grained entities based on diverse and previously unseen vocabularies. Our study highlights the inherent complexities of part segmentation due to intricate boundaries and diverse granularity, reflecting the knowledge-based nature of part identification. To address these challenges, we propose PartCLIPSeg, a novel framework utilizing generalized parts and object-level contexts to mitigate the lack of generalization in fine-grained parts. PartCLIPSeg integrates competitive part relationships and attention control techniques, alleviating ambiguous boundaries and underrepresented parts. Experimental results demonstrate that PartCLIPSeg outperforms existing state-of-the-art OVPS methods, offering refined segmentation and an advanced understanding of part relationships in images. Through extensive experiments, our model demonstrated an improvement over the state-of-the-art models on the Pascal-Part-116, ADE20K-Part-234, and PartImageNet datasets.
6/18/2024
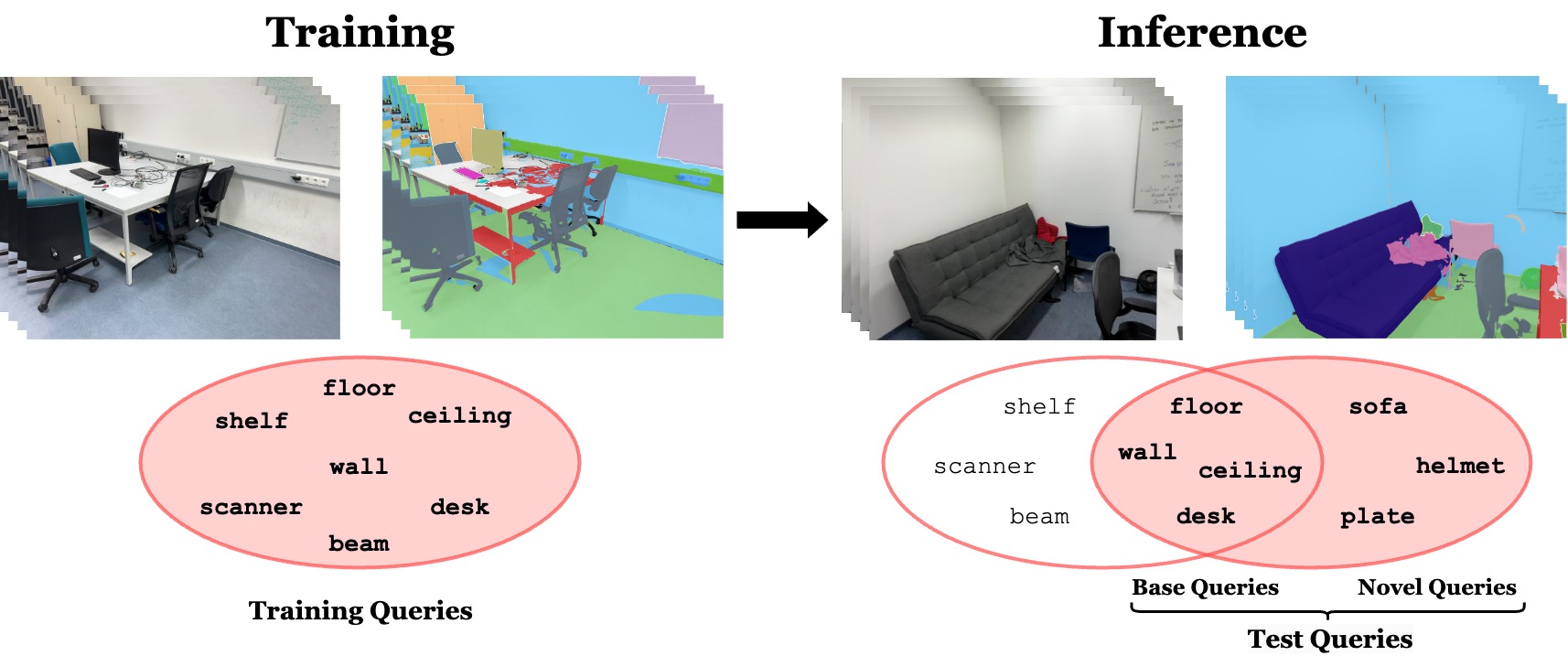
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
0
0
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
5/31/2024
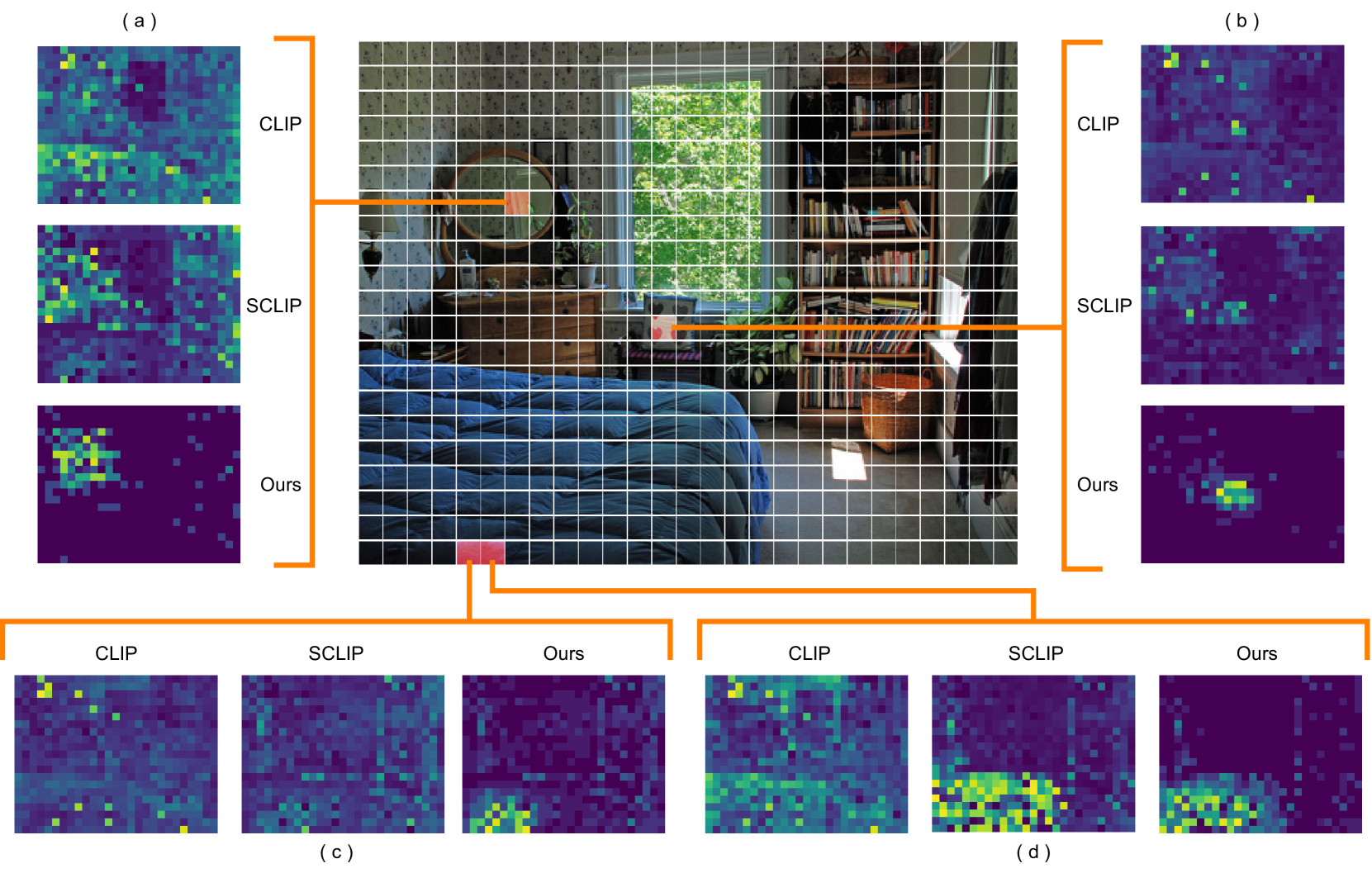
Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation
Sina Hajimiri, Ismail Ben Ayed, Jose Dolz
0
0
Despite the significant progress in deep learning for dense visual recognition problems, such as semantic segmentation, traditional methods are constrained by fixed class sets. Meanwhile, vision-language foundation models, such as CLIP, have showcased remarkable effectiveness in numerous zero-shot image-level tasks, owing to their robust generalizability. Recently, a body of work has investigated utilizing these models in open-vocabulary semantic segmentation (OVSS). However, existing approaches often rely on impractical supervised pre-training or access to additional pre-trained networks. In this work, we propose a strong baseline for training-free OVSS, termed Neighbour-Aware CLIP (NACLIP), representing a straightforward adaptation of CLIP tailored for this scenario. Our method enforces localization of patches in the self-attention of CLIP's vision transformer which, despite being crucial for dense prediction tasks, has been overlooked in the OVSS literature. By incorporating design choices favouring segmentation, our approach significantly improves performance without requiring additional data, auxiliary pre-trained networks, or extensive hyperparameter tuning, making it highly practical for real-world applications. Experiments are performed on 8 popular semantic segmentation benchmarks, yielding state-of-the-art performance on most scenarios. Our code is publicly available at https://github.com/sinahmr/NACLIP .
4/15/2024