Transferable Reinforcement Learning via Generalized Occupancy Models

0

Sign in to get full access
Overview
- This paper introduces a new approach for transferring reinforcement learning models across different tasks and environments, called Transferable Reinforcement Learning via Generalized Occupancy Models (TRGOM).
- TRGOM uses a generalized occupancy model to capture the state-action visitation patterns, allowing the model to be transferred to new tasks and environments.
- The authors demonstrate the effectiveness of TRGOM on a range of continuous control tasks, showing improved performance compared to existing transfer learning methods.
Plain English Explanation
The paper presents a new way to transfer reinforcement learning models from one task or environment to another. Reinforcement learning is a type of machine learning where an agent learns to make good decisions by interacting with its environment and getting rewards or penalties.
The key idea in this paper is to use a "generalized occupancy model" to capture the patterns of how the agent visits different states and takes different actions during training. This occupancy model can then be transferred to a new task or environment, allowing the agent to quickly learn effective behaviors without having to start from scratch.
The authors show that this TRGOM approach outperforms existing transfer learning methods on a variety of continuous control tasks, like simulated robot locomotion. The occupancy model allows the agent to more effectively reuse what it has learned, rather than having to rebuild everything from the ground up.
This is an important advance, as the ability to transfer learning is crucial for building AI systems that can flexibly adapt to new situations, rather than being narrowly specialized. By capturing the broader patterns of behavior, TRGOM enables more transferable and capable reinforcement learning models.
Technical Explanation
The paper introduces Transferable Reinforcement Learning via Generalized Occupancy Models (TRGOM), a new approach for transferring reinforcement learning agents across different tasks and environments.
TRGOM uses a generalized occupancy model to capture the state-action visitation patterns of the agent during training. This occupancy model represents the probability distribution over state-action pairs, encoding the overall visiting pattern of the agent. By learning this occupancy model, the agent can capture the broader behavioral strategies that are transferable to new settings.
The authors formulate the occupancy model learning as a constrained optimization problem, where the objective is to maximize the cumulative reward while satisfying occupancy-based constraints. This allows the model to learn a general policy that can be deployed in new tasks and environments.
The paper demonstrates the effectiveness of TRGOM on a range of continuous control tasks, including quadrupedal locomotion and manipulator control. The results show that TRGOM outperforms existing transfer learning methods, such as Offline RL via Feature Occupancy Gradient Ascent, OMPO: A Unified Framework for RL under Policy Dynamics, and Multi-Task Reinforcement Learning for Continuous Control with Successor Features.
The authors also present an extension of TRGOM, called Generalist Robotic Model (GERM), which learns a mixture of experts model to handle diverse task distributions. GERM is shown to outperform TRGOM on tasks with greater heterogeneity, as described in the paper GERM: A Generalist Robotic Model for Quadruped Locomotion.
Critical Analysis
The paper presents a promising approach for transfer learning in reinforcement learning, but there are a few potential limitations and areas for further research:
-
Task Similarity: The performance of TRGOM may depend on the similarity between the source and target tasks. The paper does not fully explore the limits of task transfer, and it would be valuable to investigate how TRGOM performs when the tasks are more dissimilar.
-
Sample Efficiency: While TRGOM outperforms existing methods, the overall sample efficiency of the approach is not discussed in depth. It would be helpful to understand how the sample requirements of TRGOM compare to other transfer learning techniques, especially in the context of real-world applications with limited data.
-
Scalability: The paper focuses on relatively simple continuous control tasks. It is not clear how well TRGOM would scale to more complex, high-dimensional environments or tasks with larger state and action spaces.
-
Interpretability: The occupancy model used in TRGOM provides a way to capture transferable behavioral patterns, but the interpretability of this model is not explored. Understanding the internal representations learned by TRGOM could provide valuable insights for improving the approach.
-
Ensemble Successor Representations: The authors mention the Ensemble Successor Representations for Task Generalization in Offline RL paper, which presents an alternative approach to transfer learning. It would be interesting to see a more detailed comparison between TRGOM and this successor representation-based method.
Overall, the TRGOM approach is a promising step forward in enabling more transferable and capable reinforcement learning agents. Further research addressing the limitations and exploring the broader applicability of this technique could lead to significant advancements in the field of transfer learning.
Conclusion
This paper introduces Transferable Reinforcement Learning via Generalized Occupancy Models (TRGOM), a new approach for transferring reinforcement learning agents across different tasks and environments. TRGOM uses a generalized occupancy model to capture the state-action visitation patterns of the agent, which can then be transferred to new settings.
The authors demonstrate the effectiveness of TRGOM on a range of continuous control tasks, showing improved performance compared to existing transfer learning methods. This work represents an important step forward in enabling more flexible and adaptive reinforcement learning agents, which can more effectively reuse their past experiences to tackle new challenges.
While the paper presents a promising approach, there are also some limitations and areas for further research, such as exploring the limits of task transfer, improving sample efficiency, and scaling to more complex environments. Continued advancements in this area could have significant implications for the development of more capable and broadly applicable reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transferable Reinforcement Learning via Generalized Occupancy Models
Chuning Zhu, Xinqi Wang, Tyler Han, Simon S. Du, Abhishek Gupta
Intelligent agents must be generalists, capable of quickly adapting to various tasks. In reinforcement learning (RL), model-based RL learns a dynamics model of the world, in principle enabling transfer to arbitrary reward functions through planning. However, autoregressive model rollouts suffer from compounding error, making model-based RL ineffective for long-horizon problems. Successor features offer an alternative by modeling a policy's long-term state occupancy, reducing policy evaluation under new tasks to linear reward regression. Yet, policy improvement with successor features can be challenging. This work proposes a novel class of models, i.e., generalized occupancy models (GOMs), that learn a distribution of successor features from a stationary dataset, along with a policy that acts to realize different successor features. These models can quickly select the optimal action for arbitrary new tasks. By directly modeling long-term outcomes in the dataset, GOMs avoid compounding error while enabling rapid transfer across reward functions. We present a practical instantiation of GOMs using diffusion models and show their efficacy as a new class of transferable models, both theoretically and empirically across various simulated robotics problems. Videos and code at https://weirdlabuw.github.io/gom/.
Read more5/30/2024
🖼️
0
Offline RL via Feature-Occupancy Gradient Ascent
Gergely Neu, Nneka Okolo
We study offline Reinforcement Learning in large infinite-horizon discounted Markov Decision Processes (MDPs) when the reward and transition models are linearly realizable under a known feature map. Starting from the classic linear-program formulation of the optimal control problem in MDPs, we develop a new algorithm that performs a form of gradient ascent in the space of feature occupancies, defined as the expected feature vectors that can potentially be generated by executing policies in the environment. We show that the resulting simple algorithm satisfies strong computational and sample complexity guarantees, achieved under the least restrictive data coverage assumptions known in the literature. In particular, we show that the sample complexity of our method scales optimally with the desired accuracy level and depends on a weak notion of coverage that only requires the empirical feature covariance matrix to cover a single direction in the feature space (as opposed to covering a full subspace). Additionally, our method is easy to implement and requires no prior knowledge of the coverage ratio (or even an upper bound on it), which altogether make it the strongest known algorithm for this setting to date.
Read more5/24/2024

0
OMPO: A Unified Framework for RL under Policy and Dynamics Shifts
Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
Training reinforcement learning policies using environment interaction data collected from varying policies or dynamics presents a fundamental challenge. Existing works often overlook the distribution discrepancies induced by policy or dynamics shifts, or rely on specialized algorithms with task priors, thus often resulting in suboptimal policy performances and high learning variances. In this paper, we identify a unified strategy for online RL policy learning under diverse settings of policy and dynamics shifts: transition occupancy matching. In light of this, we introduce a surrogate policy learning objective by considering the transition occupancy discrepancies and then cast it into a tractable min-max optimization problem through dual reformulation. Our method, dubbed Occupancy-Matching Policy Optimization (OMPO), features a specialized actor-critic structure equipped with a distribution discriminator and a small-size local buffer. We conduct extensive experiments based on the OpenAI Gym, Meta-World, and Panda Robots environments, encompassing policy shifts under stationary and nonstationary dynamics, as well as domain adaption. The results demonstrate that OMPO outperforms the specialized baselines from different categories in all settings. We also find that OMPO exhibits particularly strong performance when combined with domain randomization, highlighting its potential in RL-based robotics applications
Read more5/30/2024
0
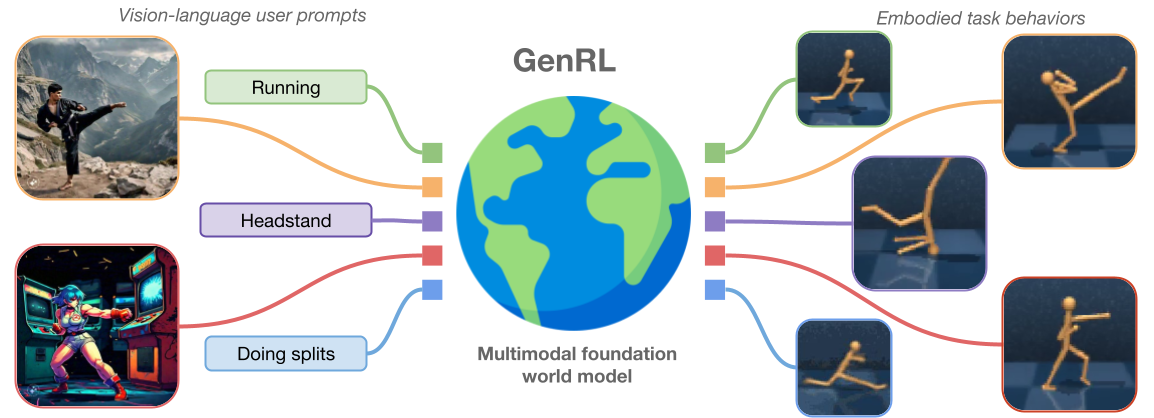
Multimodal foundation world models for generalist embodied agents
Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, Sai Rajeswar
Learning generalist embodied agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning (RL) is hard to scale up as it requires a complex reward design for each task. In contrast, language can specify tasks in a more natural way. Current foundation vision-language models (VLMs) generally require fine-tuning or other adaptations to be functional, due to the significant domain gap. However, the lack of multimodal data in such domains represents an obstacle toward developing foundation models for embodied applications. In this work, we overcome these problems by presenting multimodal foundation world models, able to connect and align the representation of foundation VLMs with the latent space of generative world models for RL, without any language annotations. The resulting agent learning framework, GenRL, allows one to specify tasks through vision and/or language prompts, ground them in the embodied domain's dynamics, and learns the corresponding behaviors in imagination. As assessed through large-scale multi-task benchmarking, GenRL exhibits strong multi-task generalization performance in several locomotion and manipulation domains. Furthermore, by introducing a data-free RL strategy, it lays the groundwork for foundation model-based RL for generalist embodied agents.
Read more6/27/2024