A tunable binaural audio telepresence system capable of balancing immersive and enhanced modes

0
🔄
Sign in to get full access
Overview
- Binaural Audio Telepresence (BAT) aims to capture the acoustic scene at one location and reproduce it for a user at another location.
- BAT can operate in two modes: Immersive BAT (I-BAT) and Enhanced BAT (E-BAT).
- I-BAT preserves the full ambience as if the user was at the remote location, while E-BAT enhances the remote conversation with improved speech quality and intelligibility.
- This paper presents a tunable BAT system that can balance between these two modes based on the desired application.
Plain English Explanation
The goal of Binaural Audio Telepresence (BAT) is to capture the sounds of a remote location and reproduce them for a user in a way that immerses them in the environment. This can be useful for applications like remote meetings, virtual events, or even just capturing the feel of a faraway place.
There are two main ways BAT can work. In the Immersive BAT (I-BAT) mode, the goal is to preserve the full ambience and atmosphere of the remote location, so it feels like the user is actually there. In the Enhanced BAT (E-BAT) mode, the focus is on improving the quality and clarity of the speech, making the remote conversation easier to understand.
This paper presents a BAT system that can be tuned to balance these two approaches, depending on the specific needs of the application. For example, if the goal is to capture the full experience of a concert hall, I-BAT would be more important. But if the goal is to have a clear, high-quality conversation with someone in a noisy environment, E-BAT would be the better choice.
The key innovation in this paper is a way to represent the spatial information of the acoustic scene, which helps the system adapt to different microphone setups and deliver consistent performance.
Technical Explanation
The proposed BAT system takes microphone signals from the remote location and converts them into binaural signals for the user. This allows the user to experience the full spatial and auditory environment as if they were physically present.
The system can operate in two modes: Immersive BAT (I-BAT) and Enhanced BAT (E-BAT). In I-BAT, the goal is to preserve the full ambience and acoustic characteristics of the remote location. In E-BAT, the focus is on enhancing the speech quality and intelligibility, even in noisy environments.
To achieve this tunable behavior, the system uses a novel Spatial COherence REpresentation (SCORE) as an input feature for model training. This spatial representation allows the system to adapt to different microphone array configurations without retraining, ensuring robust performance across a variety of setups.
Experimental results demonstrate the superior performance of the proposed BAT system, even when the array configurations were not included in the training phase. This shows the flexibility and adaptability of the approach.
Critical Analysis
The paper presents a well-designed and comprehensive BAT system that can balance the tradeoffs between immersive ambience and enhanced speech quality. The use of the SCORE feature is a clever way to make the system more robust to different microphone setups, which is an important practical consideration.
However, the paper does not address some potential limitations of the approach. For example, it's not clear how the system would handle rapidly changing acoustic environments or how it would perform in extremely noisy or reverberant spaces. Additionally, the paper does not provide much insight into the computational complexity or latency of the system, which could be important factors for real-time applications.
It would also be interesting to see how the BAT system compares to other speech enhancement or spatial audio techniques in terms of performance and user experience. A more thorough evaluation and comparison to existing approaches could help highlight the unique strengths and weaknesses of the proposed system.
Conclusion
The Binaural Audio Telepresence (BAT) system presented in this paper offers a flexible and robust solution for capturing and reproducing remote acoustic environments. By allowing the system to balance between immersive ambience and enhanced speech quality, it can be tailored to a wide range of applications, from virtual conferences to remote entertainment experiences.
The key innovation of the SCORE feature enables the system to adapt to different microphone setups, improving its practicality and real-world applicability. While the paper does not address all potential limitations, it represents a significant advancement in the field of spatial audio and telepresence technology, with promising implications for the future of remote collaboration, entertainment, and communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
A tunable binaural audio telepresence system capable of balancing immersive and enhanced modes
Yicheng Hsu, Mingsian R. Bai
Binaural Audio Telepresence (BAT) aims to encode the acoustic scene at the far end into binaural signals for the user at the near end. BAT encompasses an immense range of applications that can vary between two extreme modes of Immersive BAT (I-BAT) and Enhanced BAT (E-BAT). With I-BAT, our goal is to preserve the full ambience as if we were at the far end, while with E-BAT, our goal is to enhance the far-end conversation with significantly improved speech quality and intelligibility. To this end, this paper presents a tunable BAT system to vary between these two AT modes with a desired application-specific balance. Microphone signals are converted into binaural signals with prescribed ambience factor. A novel Spatial COherence REpresentation (SCORE) is proposed as an input feature for model training so that the network remains robust to different array setups. Experimental results demonstrated the superior performance of the proposed BAT, even when the array configurations were not included in the training phase.
Read more5/15/2024

0
A Lightweight and Real-Time Binaural Speech Enhancement Model with Spatial Cues Preservation
Jingyuan Wang, Jie Zhang, Shihao Chen, Miao Sun
Binaural speech enhancement (BSE) aims to jointly improve the speech quality and intelligibility of noisy signals received by hearing devices and preserve the spatial cues of the target for natural listening. Existing methods often suffer from the compromise between noise reduction (NR) capacity and spatial cues preservation (SCP) accuracy and a high computational demand in complex acoustic scenes. In this work, we present a learning-based lightweight binaural complex convolutional network (LBCCN), which excels in NR by filtering low-frequency bands and keeping the rest. Additionally, our approach explicitly incorporates the estimation of interchannel relative acoustic transfer function to ensure the spatial cues fidelity and speech clarity. Results show that the proposed LBCCN can achieve a comparable NR performance to state-of-the-art methods under various noise conditions, but with a much lower computational cost and a better SCP. The reproducible code and audio examples are available at https://github.com/jywanng/LBCCN.
Read more9/20/2024
💬
0
BAT: Learning to Reason about Spatial Sounds with Large Language Models
Zhisheng Zheng, Puyuan Peng, Ziyang Ma, Xie Chen, Eunsol Choi, David Harwath
Spatial sound reasoning is a fundamental human skill, enabling us to navigate and interpret our surroundings based on sound. In this paper we present BAT, which combines the spatial sound perception ability of a binaural acoustic scene analysis model with the natural language reasoning capabilities of a large language model (LLM) to replicate this innate ability. To address the lack of existing datasets of in-the-wild spatial sounds, we synthesized a binaural audio dataset using AudioSet and SoundSpaces 2.0. Next, we developed SpatialSoundQA, a spatial sound-based question-answering dataset, offering a range of QA tasks that train BAT in various aspects of spatial sound perception and reasoning. The acoustic front end encoder of BAT is a novel spatial audio encoder named Spatial Audio Spectrogram Transformer, or Spatial-AST, which by itself achieves strong performance across sound event detection, spatial localization, and distance estimation. By integrating Spatial-AST with LLaMA-2 7B model, BAT transcends standard Sound Event Localization and Detection (SELD) tasks, enabling the model to reason about the relationships between the sounds in its environment. Our experiments demonstrate BAT's superior performance on both spatial sound perception and reasoning, showcasing the immense potential of LLMs in navigating and interpreting complex spatial audio environments.
Read more5/28/2024
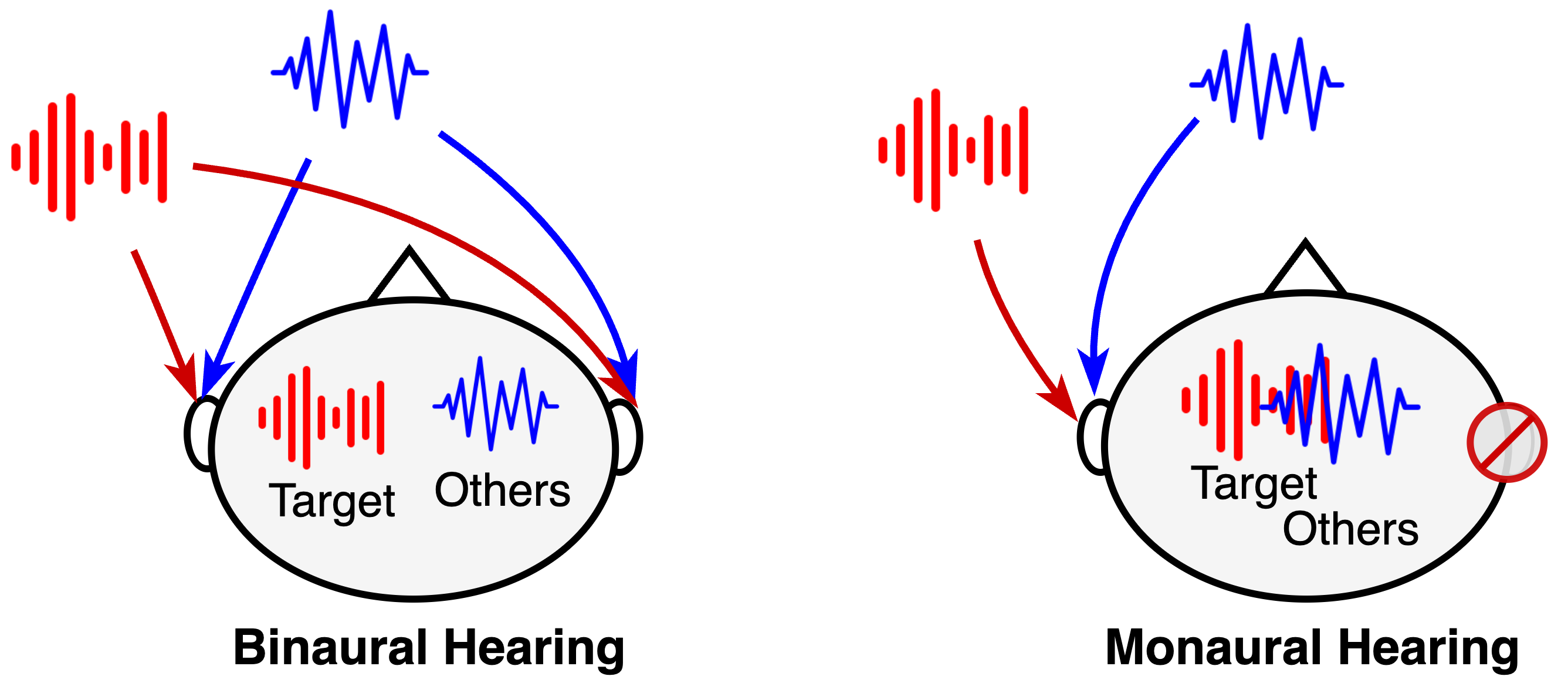
0
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024