Real-time multichannel deep speech enhancement in hearing aids: Comparing monaural and binaural processing in complex acoustic scenarios
2405.01967
0
0
🤿
Abstract
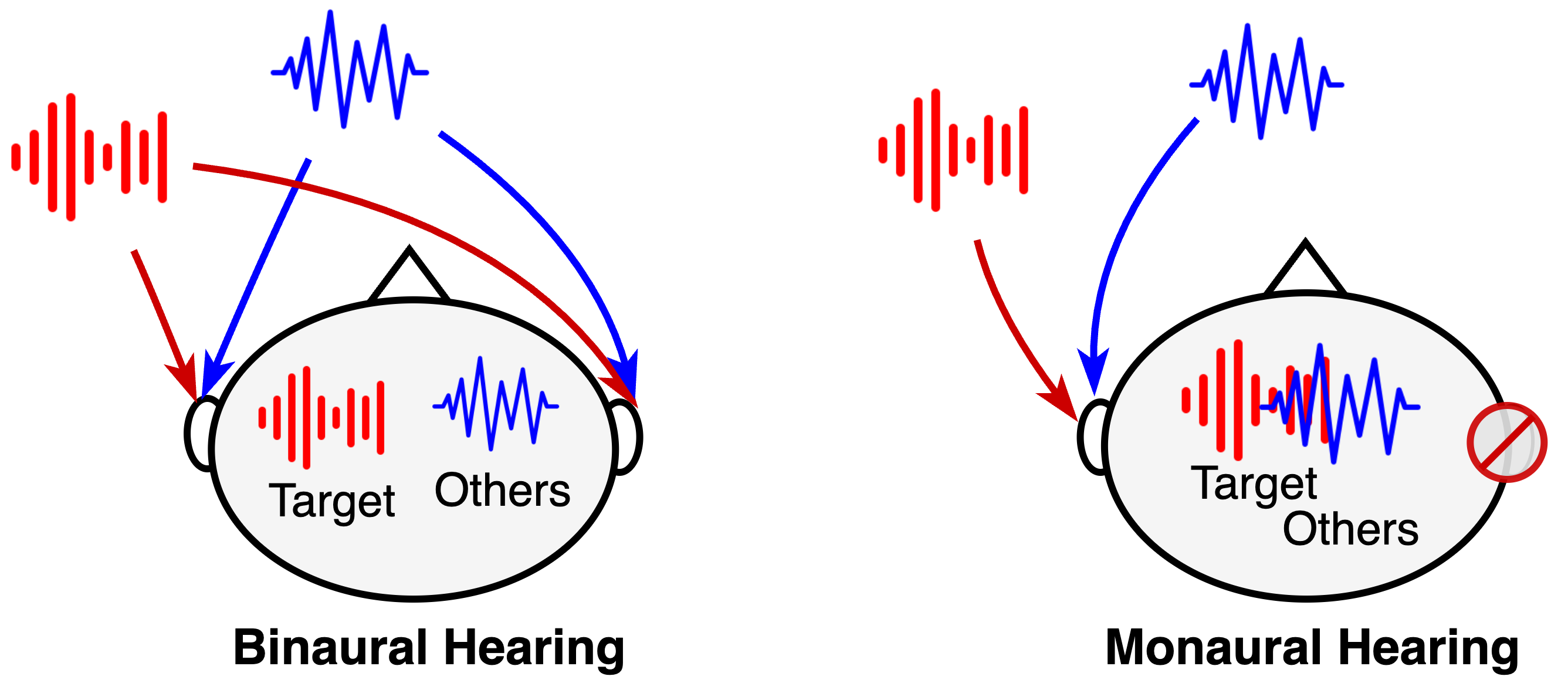
Deep learning has the potential to enhance speech signals and increase their intelligibility for users of hearing aids. Deep models suited for real-world application should feature a low computational complexity and low processing delay of only a few milliseconds. In this paper, we explore deep speech enhancement that matches these requirements and contrast monaural and binaural processing algorithms in two complex acoustic scenes. Both algorithms are evaluated with objective metrics and in experiments with hearing-impaired listeners performing a speech-in-noise test. Results are compared to two traditional enhancement strategies, i.e., adaptive differential microphone processing and binaural beamforming. While in diffuse noise, all algorithms perform similarly, the binaural deep learning approach performs best in the presence of spatial interferers. Through a post-analysis, this can be attributed to improvements at low SNRs and to precise spatial filtering.
Create account to get full access
Overview
- Deep learning has the potential to enhance speech signals and increase their intelligibility for users of hearing aids.
- Deep models suited for real-world application should feature low computational complexity and low processing delay of only a few milliseconds.
- This paper explores deep speech enhancement that matches these requirements and contrasts monaural and binaural processing algorithms in two complex acoustic scenes.
Plain English Explanation
Deep learning, a type of artificial intelligence, could help improve the quality of speech signals for people who use hearing aids. To be useful in the real world, these deep learning models need to be able to do this processing quickly and efficiently, with low delays of just a few milliseconds.
This research paper looks at two different deep learning approaches to enhancing speech - one that uses information from just one microphone (monaural) and one that uses information from two microphones (binaural). They tested these approaches in two complex listening environments to see how well they work.
Technical Explanation
The researchers evaluated the monaural and binaural deep learning algorithms for speech enhancement using objective metrics and experiments with hearing-impaired listeners. They compared the performance of these deep learning approaches to two traditional enhancement strategies: adaptive differential microphone processing and binaural beamforming.
In environments with diffuse noise, all the algorithms performed similarly. However, the binaural deep learning approach outperformed the others when there were competing sounds coming from specific spatial locations (spatial interferers). A further analysis showed this was due to the binaural model's ability to precisely filter out the unwanted sounds and improve intelligibility, especially in low signal-to-noise ratio conditions.
Critical Analysis
The paper demonstrates the potential of deep learning techniques to enhance speech signals for hearing aid users in challenging real-world environments. However, it's important to note that the research was conducted in simulated acoustic scenes, and further testing would be needed to validate the performance in actual usage scenarios.
Additionally, the paper does not provide much detail on the specific deep learning architectures used or the training data and procedures. More information on these technical aspects would be helpful for others interested in replicating or building upon this research.
Conclusion
This research demonstrates that deep learning can be an effective approach for improving speech intelligibility for hearing aid users, particularly in situations with competing spatial sound sources. The binaural deep learning model showed promising results, outperforming traditional enhancement strategies. With further development and real-world testing, this technology could lead to significant improvements in the quality of life for those with hearing impairments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
0
0
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
6/19/2024
📈
Exploring the Potential of Data-Driven Spatial Audio Enhancement Using a Single-Channel Model
Arthur N. dos Santos, Bruno S. Masiero, T'ulio C. L. Mateus
0
0
One key aspect differentiating data-driven single- and multi-channel speech enhancement and dereverberation methods is that both the problem formulation and complexity of the solutions are considerably more challenging in the latter case. Additionally, with limited computational resources, it is cumbersome to train models that require the management of larger datasets or those with more complex designs. In this scenario, an unverified hypothesis that single-channel methods can be adapted to multi-channel scenarios simply by processing each channel independently holds significant implications, boosting compatibility between sound scene capture and system input-output formats, while also allowing modern research to focus on other challenging aspects, such as full-bandwidth audio enhancement, competitive noise suppression, and unsupervised learning. This study verifies this hypothesis by comparing the enhancement promoted by a basic single-channel speech enhancement and dereverberation model with two other multi-channel models tailored to separate clean speech from noisy 3D mixes. A direction of arrival estimation model was used to objectively evaluate its capacity to preserve spatial information by comparing the output signals with ground-truth coordinate values. Consequently, a trade-off arises between preserving spatial information with a more straightforward single-channel solution at the cost of obtaining lower gains in intelligibility scores.
4/24/2024
🔄
A tunable binaural audio telepresence system capable of balancing immersive and enhanced modes
Yicheng Hsu, Mingsian R. Bai
0
0
Binaural Audio Telepresence (BAT) aims to encode the acoustic scene at the far end into binaural signals for the user at the near end. BAT encompasses an immense range of applications that can vary between two extreme modes of Immersive BAT (I-BAT) and Enhanced BAT (E-BAT). With I-BAT, our goal is to preserve the full ambience as if we were at the far end, while with E-BAT, our goal is to enhance the far-end conversation with significantly improved speech quality and intelligibility. To this end, this paper presents a tunable BAT system to vary between these two AT modes with a desired application-specific balance. Microphone signals are converted into binaural signals with prescribed ambience factor. A novel Spatial COherence REpresentation (SCORE) is proposed as an input feature for model training so that the network remains robust to different array setups. Experimental results demonstrated the superior performance of the proposed BAT, even when the array configurations were not included in the training phase.
5/15/2024
🤿
Deep low-latency joint speech transmission and enhancement over a gaussian channel
Mohammad Bokaei, Jesper Jensen, Simon Doclo, Jan {O}stergaard
0
0
Ensuring intelligible speech communication for hearing assistive devices in low-latency scenarios presents significant challenges in terms of speech enhancement, coding and transmission. In this paper, we propose novel solutions for low-latency joint speech transmission and enhancement, leveraging deep neural networks (DNNs). Our approach integrates two state-of-the-art DNN architectures for low-latency speech enhancement and low-latency analog joint source-channel-based transmission, creating a combined low-latency system and jointly training both systems in an end-to-end approach. Due to the computational demands of the enhancement system, this order is suitable when high computational power is unavailable in the decoder, like hearing assistive devices. The proposed system enables the configuration of total latency, achieving high performance even at latencies as low as 3 ms, which is typically challenging to attain. The simulation results provide compelling evidence that a joint enhancement and transmission system is superior to a simple concatenation system in diverse settings, encompassing various wireless channel conditions, latencies, and background noise scenarios.
5/1/2024