Turbo your multi-modal classification with contrastive learning

0
Sign in to get full access
Overview
- Explores using contrastive learning to improve multi-modal classification
- Proposes a "turbo" technique to enhance the performance of multi-modal models
- Demonstrates strong results on several benchmarks
Plain English Explanation
This paper investigates how contrastive learning can be used to enhance the performance of multi-modal classification models. The core idea is to leverage the power of contrastive learning to better align the representations from different modalities, such as text and images.
The authors introduce a "turbo" technique that builds on top of existing multi-modal architectures. This "turbo" approach aims to further boost the model's classification accuracy by improving the interaction and integration of the multi-modal features. Experiments on several benchmark datasets demonstrate that this technique can lead to significant performance gains compared to standard multi-modal approaches.
Technical Explanation
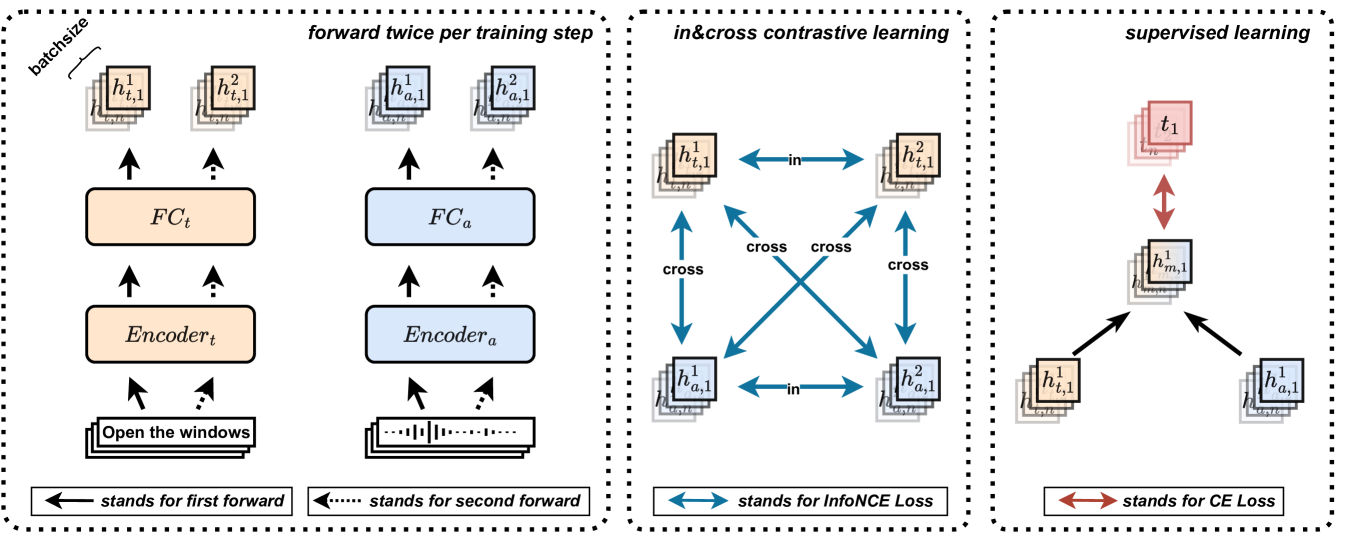
The paper proposes a novel multi-modal classification framework that combines the strengths of contrastive learning and traditional supervised learning. The model architecture consists of separate encoders for each modality (e.g., text and image), which are trained using a combination of classification and contrastive loss functions.
The key innovation is the "turbo" technique, which introduces an additional contrastive loss term to the training objective. This contrastive loss encourages the model to learn more discriminative and aligned representations between the different modalities, leading to improved multi-modal integration and classification performance.
The authors evaluate their approach on several multi-label and multi-class classification benchmarks, including fine-grained image recognition and multi-modal sentiment analysis tasks. The results demonstrate that the "turbo" technique consistently outperforms standard multi-modal baselines, highlighting the benefits of leveraging contrastive learning for multi-modal classification.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed "turbo" technique for multi-modal classification. The authors acknowledge that their approach relies on the availability of paired multi-modal data, which may not always be the case in real-world scenarios.
Additionally, the paper does not explore the performance of the "turbo" technique in the presence of noisy or missing modalities, which is a common challenge in practical multi-modal applications. Further research could investigate the robustness of the method to such situations.
Another potential limitation is the computational overhead introduced by the additional contrastive loss term, which may impact the training efficiency of the model. The authors could have discussed strategies to mitigate this, such as exploring more efficient contrastive learning approaches.
Conclusion
This paper demonstrates the effectiveness of incorporating contrastive learning into multi-modal classification models. The proposed "turbo" technique leverages the power of contrastive learning to improve the alignment and integration of multi-modal representations, leading to significant performance gains on various benchmarks.
The findings of this research suggest that contrastive learning can be a valuable tool for enhancing the capabilities of multi-modal systems, with potential applications in areas such as visual-language understanding, multi-modal sentiment analysis, and multimodal content retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Turbo your multi-modal classification with contrastive learning
Zhiyu Zhang, Da Liu, Shengqiang Liu, Anna Wang, Jie Gao, Yali Li
Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.
Read more9/17/2024

0
What to align in multimodal contrastive learning?
Benoit Dufumier, Javiera Castillo-Navarro, Devis Tuia, Jean-Philippe Thiran
Humans perceive the world through multisensory integration, blending the information of different modalities to adapt their behavior. Contrastive learning offers an appealing solution for multimodal self-supervised learning. Indeed, by considering each modality as a different view of the same entity, it learns to align features of different modalities in a shared representation space. However, this approach is intrinsically limited as it only learns shared or redundant information between modalities, while multimodal interactions can arise in other ways. In this work, we introduce CoMM, a Contrastive MultiModal learning strategy that enables the communication between modalities in a single multimodal space. Instead of imposing cross- or intra- modality constraints, we propose to align multimodal representations by maximizing the mutual information between augmented versions of these multimodal features. Our theoretical analysis shows that shared, synergistic and unique terms of information naturally emerge from this formulation, allowing us to estimate multimodal interactions beyond redundancy. We test CoMM both in a controlled and in a series of real-world settings: in the former, we demonstrate that CoMM effectively captures redundant, unique and synergistic information between modalities. In the latter, CoMM learns complex multimodal interactions and achieves state-of-the-art results on the six multimodal benchmarks.
Read more9/12/2024
📈
0
Improving Multimodal Learning with Multi-Loss Gradient Modulation
Konstantinos Kontras, Christos Chatzichristos, Matthew Blaschko, Maarten De Vos
Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
Read more5/14/2024
0
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Alexandre Audibert, Aur'elien Gauffre, Massih-Reza Amini
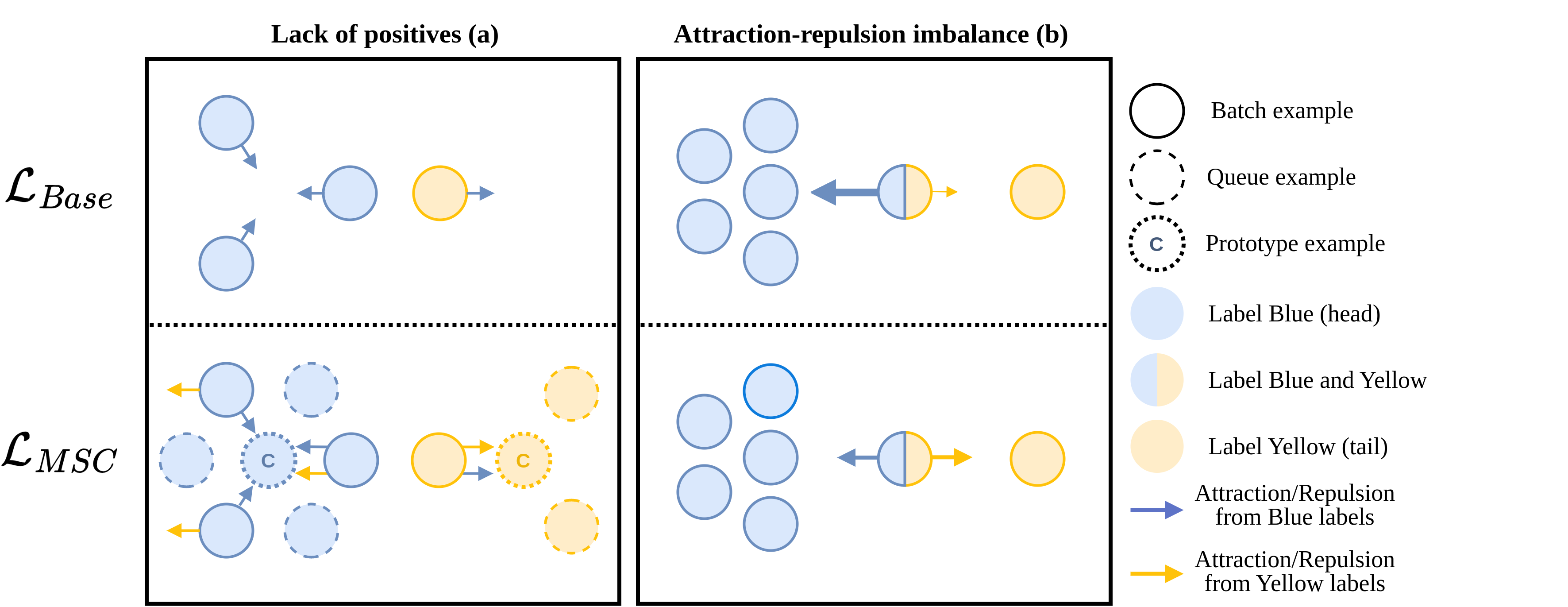
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
Read more4/16/2024