Improved Content Understanding With Effective Use of Multi-task Contrastive Learning

0
🤔
Sign in to get full access
Overview
- This paper addresses the challenge of improving the semantic understanding capabilities of LinkedIn's core content recommendation models.
- The researchers leverage multi-task learning, a method that has shown promise in various domains, to fine-tune a pre-trained, transformer-based large language model (LLM).
- The model is trained using multi-task contrastive learning on a diverse set of semantic labeling tasks, leading to positive transfer and superior performance across all tasks compared to training independently on each.
- The specialized content embeddings produced by the model outperform generalized embeddings from OpenAI on LinkedIn dataset and tasks.
Plain English Explanation
Content recommendation is a crucial feature of social media platforms like LinkedIn, helping users discover relevant and engaging content. However, improving the semantic understanding capabilities of these recommendation models is a significant challenge. This paper addresses this problem by using a technique called multi-task learning.
Multi-task learning involves training a single model to perform multiple related tasks simultaneously. The idea is that the model can learn more efficiently by sharing knowledge and insights across these tasks, rather than learning each one independently. In this case, the researchers fine-tuned a pre-trained language model using multi-task contrastive learning, which means the model was trained to identify similarities and differences between different pieces of content.
The model was trained on a diverse set of semantic labeling tasks, which involved classifying the meaning and context of various texts. By learning these tasks together, the model was able to develop a stronger understanding of language and content, leading to better performance on all the tasks compared to training on each one separately.
The resulting model produced specialized content embeddings, which are numerical representations of the meaning and context of the content. These specialized embeddings outperformed more general embeddings from OpenAI when applied to LinkedIn's dataset and tasks, suggesting the model has a deeper understanding of the specific content and context on the LinkedIn platform.
Technical Explanation
The researchers fine-tuned a pre-trained, transformer-based large language model (LLM) using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. This approach leverages the power of multi-task learning to improve the model's semantic understanding capabilities, which is a key challenge for LinkedIn's core content recommendation models.
The multi-task learning setup involved training the model to perform multiple related tasks simultaneously, including text classification, named entity recognition, and relation extraction. By sharing knowledge and insights across these tasks, the model was able to learn more efficiently and develop a stronger understanding of language and content, as evidenced by positive transfer leading to superior performance across all tasks compared to training independently on each.
The specialized content embeddings produced by the model outperformed the more generalized embeddings offered by OpenAI when applied to LinkedIn's dataset and tasks. This suggests the model has developed a deeper understanding of the specific content and context on the LinkedIn platform, making it a more suitable foundation for customization and fine-tuning by vertical teams across the organization.
Critical Analysis
The paper provides a robust and well-designed approach to improving the semantic understanding capabilities of LinkedIn's content recommendation models. The use of multi-task learning is a well-established technique that has shown promise in various domains, and the researchers have successfully applied it to this specific challenge.
However, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to understand the impact of the model's improved semantic understanding on user engagement and satisfaction with the content recommendations. Additionally, the researchers could explore the transferability of the model to other platforms or domains beyond LinkedIn, as the specialized content embeddings may have broader applications.
Another potential area for further investigation is the interpretability of the model's decision-making process. As these models become more sophisticated, it will be important to ensure they are transparent and accountable, particularly in high-stakes applications like content recommendation.
Overall, this research provides a solid foundation for enhancing the core content recommendation models at LinkedIn, and the insights and best practices offered in the paper could be valuable for the broader field of natural language processing and recommendation systems.
Conclusion
This paper presents a novel approach to improving the semantic understanding capabilities of LinkedIn's core content recommendation models. By leveraging multi-task learning to fine-tune a pre-trained language model, the researchers were able to develop a model with superior performance across a range of semantic labeling tasks.
The specialized content embeddings produced by the model outperformed more generalized embeddings on LinkedIn's dataset and tasks, highlighting the potential for this approach to be tailored and customized for specific applications and verticals. This work offers a robust foundation for teams across LinkedIn to further refine and deploy the model, as well as insights and best practices that could benefit the broader field of natural language processing and recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Improved Content Understanding With Effective Use of Multi-task Contrastive Learning
Akanksha Bindal, Sudarshan Ramanujam, Dave Golland, TJ Hazen, Tina Jiang, Fengyu Zhang, Peng Yan
In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
Read more7/16/2024
0
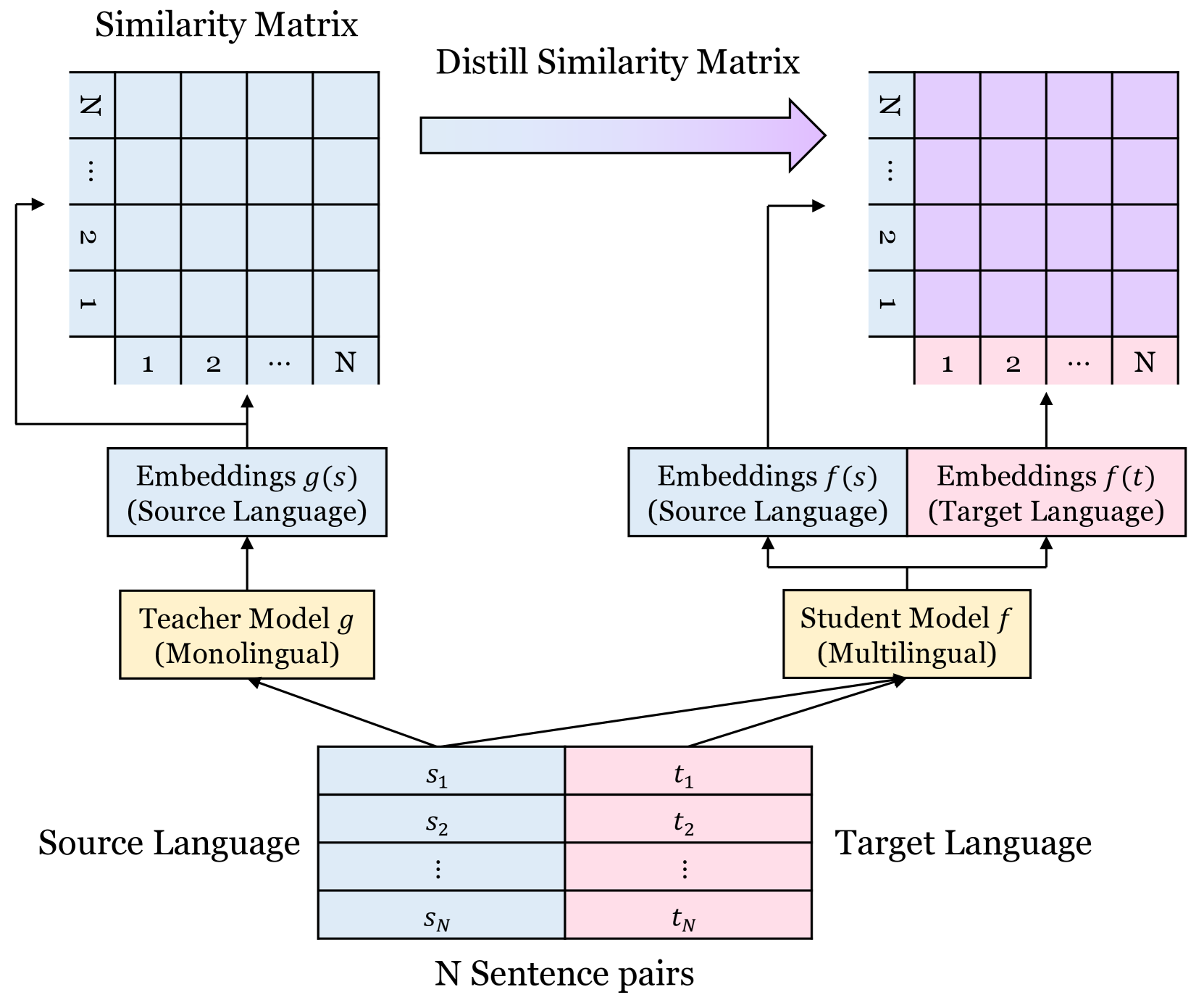
Improving Multi-lingual Alignment Through Soft Contrastive Learning
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Read more5/29/2024
💬
0
Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
Huiming Wang, Zhaodonghui Li, Liying Cheng, Soh De Wen, Lidong Bing
Recently, large language models (LLMs) have emerged as a groundbreaking technology and their unparalleled text generation capabilities have sparked interest in their application to the fundamental sentence representation learning task. Existing methods have explored utilizing LLMs as data annotators to generate synthesized data for training contrastive learning based sentence embedding models such as SimCSE. However, since contrastive learning models are sensitive to the quality of sentence pairs, the effectiveness of these methods is largely influenced by the content generated from LLMs, highlighting the need for more refined generation in the context of sentence representation learning. Building upon this premise, we propose MultiCSR, a multi-level contrastive sentence representation learning framework that decomposes the process of prompting LLMs to generate a corpus for training base sentence embedding models into three stages (i.e., sentence generation, sentence pair construction, in-batch training) and refines the generated content at these three distinct stages, ensuring only high-quality sentence pairs are utilized to train a base contrastive learning model. Our extensive experiments reveal that MultiCSR enables a less advanced LLM to surpass the performance of ChatGPT, while applying it to ChatGPT achieves better state-of-the-art results. Comprehensive analyses further underscore the potential of our framework in various application scenarios and achieving better sentence representation learning with LLMs.
Read more5/20/2024
0
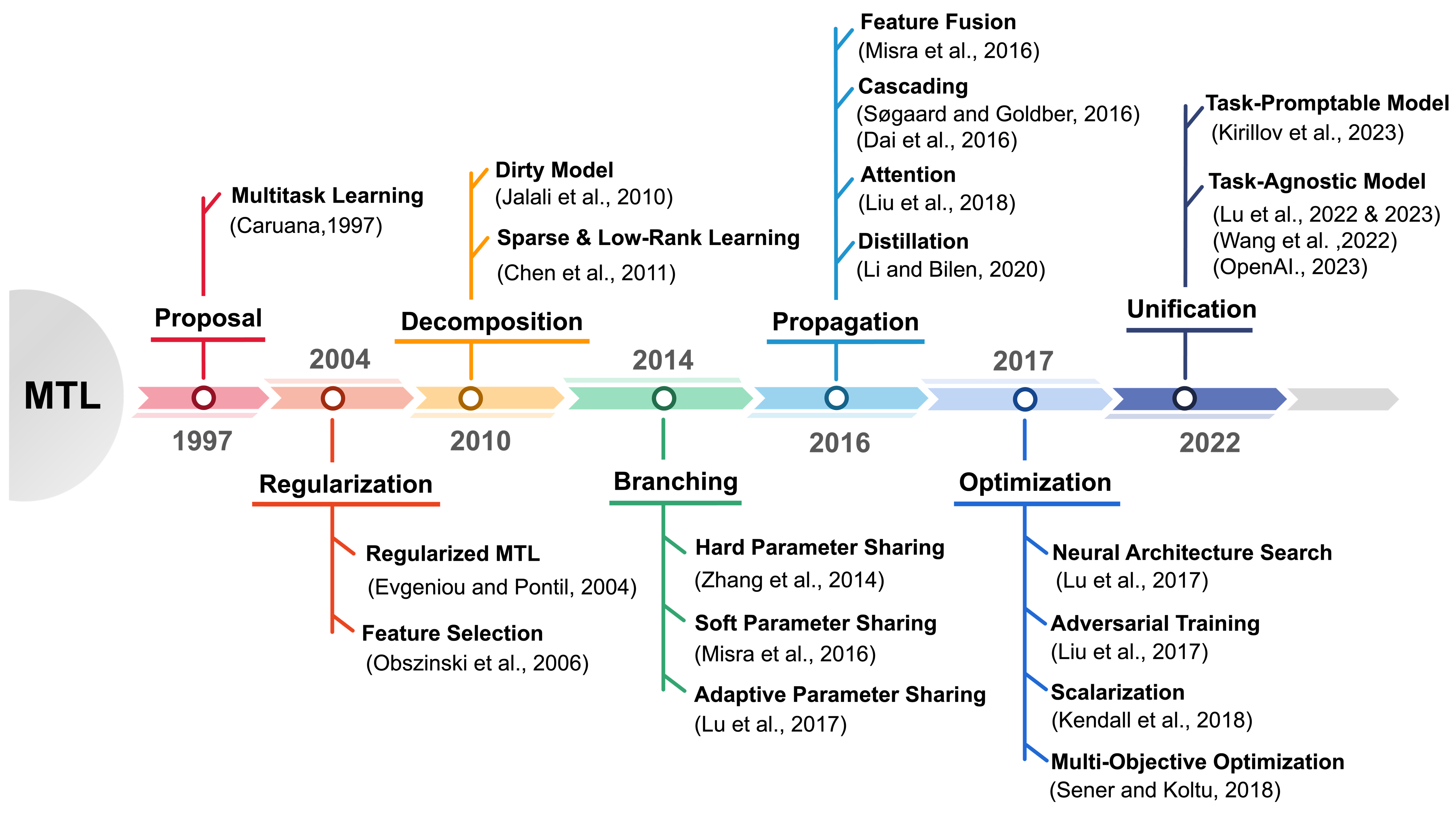
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Read more5/1/2024