What to align in multimodal contrastive learning?

0

Sign in to get full access
Overview
- The paper examines what should be aligned in multimodal contrastive learning
- It quantifies multimodal interactions and evaluates different alignment strategies
- The findings provide insights for designing effective multimodal contrastive learning systems
Plain English Explanation
Multimodal contrastive learning is a technique that aims to learn representations that capture the relationships between different types of data, such as images and text. The key idea is to learn representations where similar data points from different modalities are pulled together, while dissimilar data points are pushed apart.
In multimodal contrastive learning, what should be aligned? This paper explores this question by quantifying the interactions between different modalities and evaluating different strategies for aligning the representations.
The researchers found that simply aligning the representations of individual data points from different modalities may not be the most effective approach. Instead, they show that aligning the interactions between the modalities, such as the correlations between visual and textual features, can lead to better performance on downstream tasks.
This suggests that the goal of multimodal contrastive learning should be to capture the complex relationships between the different modalities, rather than just forcing individual data points to be close together. By focusing on the interactions between modalities, the learned representations can better capture the rich semantic connections that exist in multimodal data.
Technical Explanation
The paper first proposes a framework for quantifying the interactions between different modalities in a multimodal dataset. This involves computing the mutual information between the representations of the modalities, as well as the correlations between the different feature dimensions.
The researchers then evaluate different strategies for aligning the representations in a multimodal contrastive learning setup. They compare approaches that align individual data points across modalities, with those that align the interactions between modalities, such as the correlations between visual and textual features.
Their experiments on several multimodal benchmarks show that aligning the interactions between modalities leads to better performance on downstream tasks, such as image-text retrieval and zero-shot classification. This suggests that the goal of multimodal contrastive learning should be to capture the complex relationships between the modalities, rather than just forcing individual data points to be close together.
The paper provides insights into the importance of modeling multimodal interactions in contrastive learning, which can lead to more effective multimodal representations. This has implications for a wide range of applications that rely on learning from multimodal data, such as medical imaging, language and vision, and multimodal dialogue systems.
Critical Analysis
The paper provides a valuable contribution to the understanding of multimodal contrastive learning. However, there are a few potential limitations and areas for further research:
-
The experiments are conducted on a limited set of datasets and tasks. It would be important to validate the findings on a broader range of multimodal applications to ensure the generalizability of the insights.
-
The paper focuses on pairwise interactions between modalities, but in many real-world scenarios, there may be more complex, higher-order interactions that could be important to model.
-
The proposed methods for quantifying multimodal interactions rely on relatively simple statistics like mutual information and correlation. More sophisticated techniques for capturing complex dependencies between modalities could potentially lead to further improvements.
-
The paper does not explore the use of additional techniques, such as attention mechanisms or cross-modal fusion, that could potentially enhance the ability to model multimodal interactions in contrastive learning.
Despite these potential limitations, the paper makes a compelling case for the importance of aligning multimodal interactions in contrastive learning, rather than just individual data points. This opens up interesting avenues for future research in this area.
Conclusion
This paper highlights the importance of aligning multimodal interactions, rather than just individual data points, in multimodal contrastive learning. By quantifying the interactions between modalities and evaluating different alignment strategies, the researchers show that capturing the complex relationships between modalities can lead to more effective multimodal representations.
These insights have important implications for a wide range of applications that rely on learning from multimodal data, such as medical imaging, language and vision, and multimodal dialogue systems. The paper provides a valuable foundation for further research in this area, with the potential to drive progress in the field of multimodal machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What to align in multimodal contrastive learning?
Benoit Dufumier, Javiera Castillo-Navarro, Devis Tuia, Jean-Philippe Thiran
Humans perceive the world through multisensory integration, blending the information of different modalities to adapt their behavior. Contrastive learning offers an appealing solution for multimodal self-supervised learning. Indeed, by considering each modality as a different view of the same entity, it learns to align features of different modalities in a shared representation space. However, this approach is intrinsically limited as it only learns shared or redundant information between modalities, while multimodal interactions can arise in other ways. In this work, we introduce CoMM, a Contrastive MultiModal learning strategy that enables the communication between modalities in a single multimodal space. Instead of imposing cross- or intra- modality constraints, we propose to align multimodal representations by maximizing the mutual information between augmented versions of these multimodal features. Our theoretical analysis shows that shared, synergistic and unique terms of information naturally emerge from this formulation, allowing us to estimate multimodal interactions beyond redundancy. We test CoMM both in a controlled and in a series of real-world settings: in the former, we demonstrate that CoMM effectively captures redundant, unique and synergistic information between modalities. In the latter, CoMM learns complex multimodal interactions and achieves state-of-the-art results on the six multimodal benchmarks.
Read more9/12/2024
🔄
0
Beyond Unimodal Learning: The Importance of Integrating Multiple Modalities for Lifelong Learning
Fahad Sarfraz, Bahram Zonooz, Elahe Arani
While humans excel at continual learning (CL), deep neural networks (DNNs) exhibit catastrophic forgetting. A salient feature of the brain that allows effective CL is that it utilizes multiple modalities for learning and inference, which is underexplored in DNNs. Therefore, we study the role and interactions of multiple modalities in mitigating forgetting and introduce a benchmark for multimodal continual learning. Our findings demonstrate that leveraging multiple views and complementary information from multiple modalities enables the model to learn more accurate and robust representations. This makes the model less vulnerable to modality-specific regularities and considerably mitigates forgetting. Furthermore, we observe that individual modalities exhibit varying degrees of robustness to distribution shift. Finally, we propose a method for integrating and aligning the information from different modalities by utilizing the relational structural similarities between the data points in each modality. Our method sets a strong baseline that enables both single- and multimodal inference. Our study provides a promising case for further exploring the role of multiple modalities in enabling CL and provides a standard benchmark for future research.
Read more5/7/2024
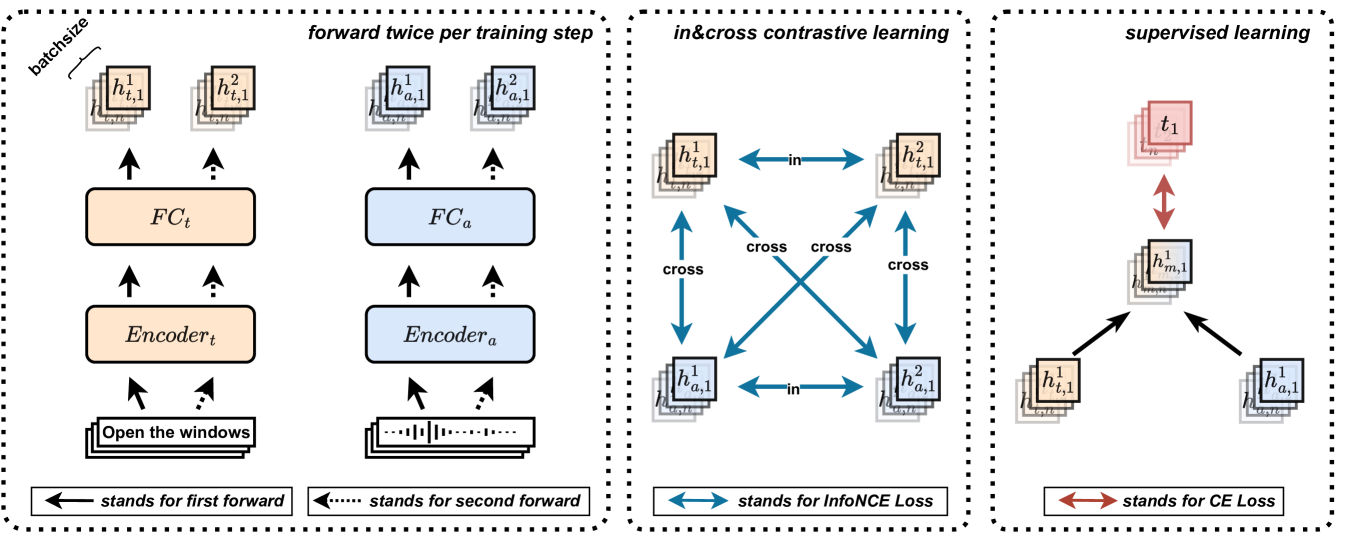
0
New!Turbo your multi-modal classification with contrastive learning
Zhiyu Zhang, Da Liu, Shengqiang Liu, Anna Wang, Jie Gao, Yali Li
Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.
Read more9/17/2024

0
Complementary Information Mutual Learning for Multimodality Medical Image Segmentation
Chuyun Shen, Wenhao Li, Haoqing Chen, Xiaoling Wang, Fengping Zhu, Yuxin Li, Xiangfeng Wang, Bo Jin
Radiologists must utilize multiple modal images for tumor segmentation and diagnosis due to the limitations of medical imaging and the diversity of tumor signals. This leads to the development of multimodal learning in segmentation. However, the redundancy among modalities creates challenges for existing subtraction-based joint learning methods, such as misjudging the importance of modalities, ignoring specific modal information, and increasing cognitive load. These thorny issues ultimately decrease segmentation accuracy and increase the risk of overfitting. This paper presents the complementary information mutual learning (CIML) framework, which can mathematically model and address the negative impact of inter-modal redundant information. CIML adopts the idea of addition and removes inter-modal redundant information through inductive bias-driven task decomposition and message passing-based redundancy filtering. CIML first decomposes the multimodal segmentation task into multiple subtasks based on expert prior knowledge, minimizing the information dependence between modalities. Furthermore, CIML introduces a scheme in which each modality can extract information from other modalities additively through message passing. To achieve non-redundancy of extracted information, the redundant filtering is transformed into complementary information learning inspired by the variational information bottleneck. The complementary information learning procedure can be efficiently solved by variational inference and cross-modal spatial attention. Numerical results from the verification task and standard benchmarks indicate that CIML efficiently removes redundant information between modalities, outperforming SOTA methods regarding validation accuracy and segmentation effect.
Read more7/11/2024