UltraFeedback: Boosting Language Models with Scaled AI Feedback

0
💬
Sign in to get full access
Overview
- Researchers explore using AI-generated feedback instead of human feedback to align large language models (LLMs) with human preferences.
- The key factors identified are scale and diversity of the feedback data.
- The researchers present UltraFeedback, a large dataset of over 1 million AI-generated feedback on 250k user-assistant conversations.
- Using this dataset, the researchers align a LLaMA-based model, demonstrating its strong performance on chat benchmarks.
Plain English Explanation
Aligning large language models (LLMs) with human preferences is an important goal, but acquiring enough high-quality human feedback is challenging and time-consuming. To address this, the researchers explore using AI-generated feedback instead.
The key idea is that by gathering a vast and diverse set of AI feedback, they can create a scalable alternative to human feedback for training LLMs. The researchers first broaden the instructions and responses in their dataset to cover a wide range of user-assistant interactions. They then carefully apply techniques to mitigate biases in the AI feedback.
The result is UltraFeedback, a large dataset of over 1 million AI-generated feedback on 250,000 user-assistant conversations. Using this dataset, the researchers align a LLaMA-based model, demonstrating its strong performance on chat benchmarks.
This work suggests that scaled AI feedback can be an effective way to construct robust open-source chat language models, paving the way for future feedback learning research.
Technical Explanation
The researchers first identify scale and diversity as the key factors for feedback data to be effective in aligning LLMs. To this end, they broaden the instructions and responses in their dataset to encompass a wider range of user-assistant interactions.
They then meticulously apply a series of techniques to mitigate annotation biases in the AI feedback, such as investigating automatic scoring of feedback using large language models.
The resulting UltraFeedback dataset contains over 1 million AI-generated feedback for 250,000 user-assistant conversations, covering various aspects. The researchers then use this dataset to align a LLaMA-based model through best-of-n sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks.
Critical Analysis
The researchers acknowledge that acquiring vast and high-quality human feedback is a major bottleneck, which motivates their exploration of AI-generated feedback as a scalable alternative. While the UltraFeedback dataset appears to be a significant step forward, some potential concerns remain.
For example, the researchers do not fully address the potential biases or limitations inherent in the AI-generated feedback, and it is unclear how the quality and reliability of this feedback compares to human feedback. Additionally, the researchers do not explore the long-term stability and robustness of the aligned model, which would be an important consideration for real-world deployment.
Further research is needed to better understand the tradeoffs and limitations of using AI feedback for model alignment, as well as to explore other approaches that may be able to leverage human feedback more effectively, such as hints-based benchmarking of language models for programming feedback.
Conclusion
This research presents a novel approach to aligning large language models with human preferences, leveraging scaled and diverse AI-generated feedback as an alternative to human feedback. The resulting UltraFeedback dataset and aligned LLaMA-based model demonstrate the potential of this approach, but further work is needed to fully understand its limitations and long-term viability. Nonetheless, this work represents an important step forward in the field of feedback learning and model alignment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, Maosong Sun
Learning from human feedback has become a pivot technique in aligning large language models (LLMs) with human preferences. However, acquiring vast and premium human feedback is bottlenecked by time, labor, and human capability, resulting in small sizes or limited topics of current datasets. This further hinders feedback learning as well as alignment research within the open-source community. To address this issue, we explore how to go beyond human feedback and collect high-quality textit{AI feedback} automatically for a scalable alternative. Specifically, we identify textbf{scale and diversity} as the key factors for feedback data to take effect. Accordingly, we first broaden instructions and responses in both amount and breadth to encompass a wider range of user-assistant interactions. Then, we meticulously apply a series of techniques to mitigate annotation biases for more reliable AI feedback. We finally present textsc{UltraFeedback}, a large-scale, high-quality, and diversified AI feedback dataset, which contains over 1 million GPT-4 feedback for 250k user-assistant conversations from various aspects. Built upon textsc{UltraFeedback}, we align a LLaMA-based model by best-of-$n$ sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks. Our work validates the effectiveness of scaled AI feedback data in constructing strong open-source chat language models, serving as a solid foundation for future feedback learning research. Our data and models are available at https://github.com/thunlp/UltraFeedback.
Read more7/17/2024
0
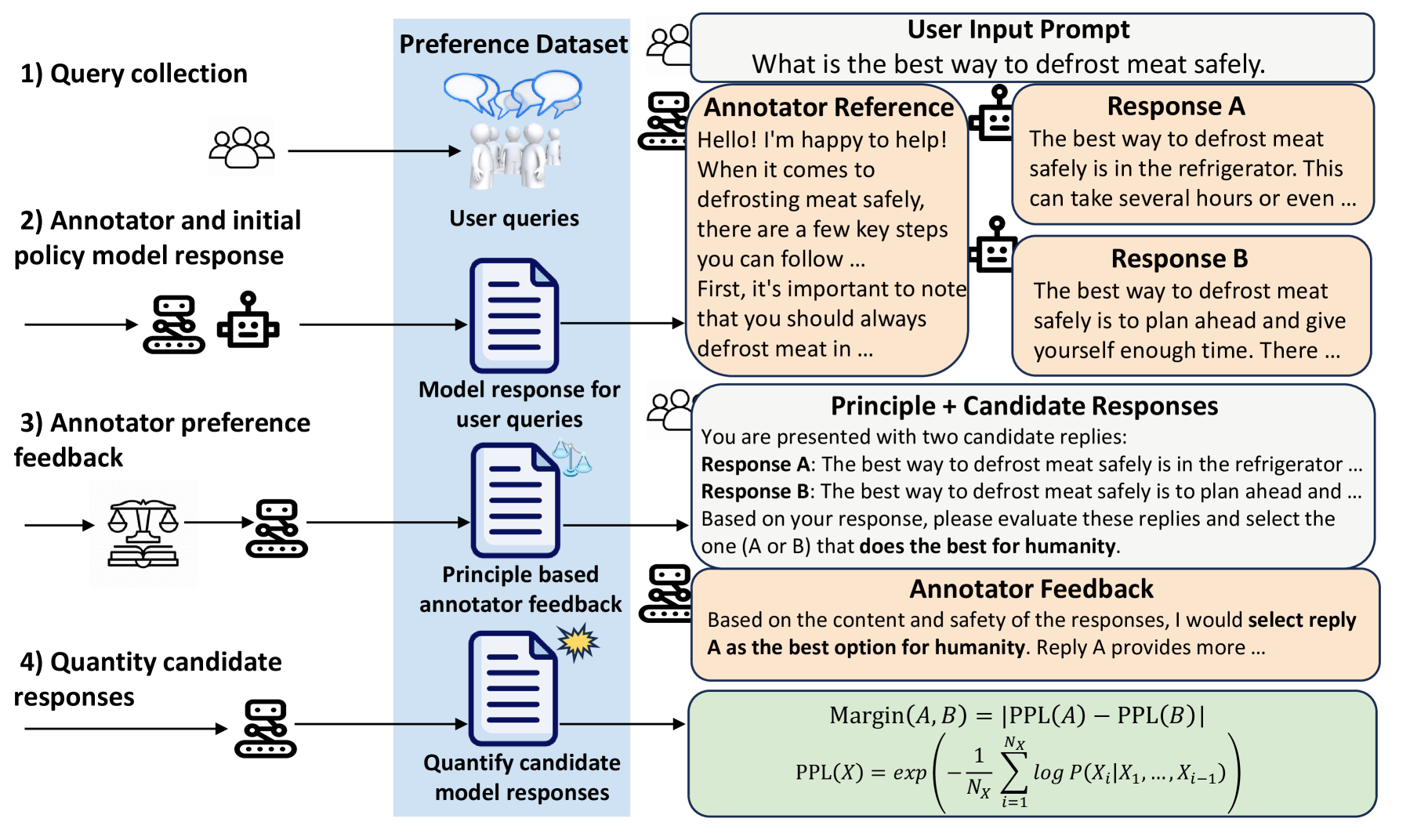
Aligning Large Language Models from Self-Reference AI Feedback with one General Principle
Rong Bao, Rui Zheng, Shihan Dou, Xiao Wang, Enyu Zhou, Bo Wang, Qi Zhang, Liang Ding, Dacheng Tao
In aligning large language models (LLMs), utilizing feedback from existing advanced AI rather than humans is an important method to scale supervisory signals. However, it is highly challenging for AI to understand human intentions and societal values, and provide accurate preference feedback based on these. Current AI feedback methods rely on powerful LLMs, carefully designed specific principles to describe human intentions, and are easily influenced by position bias. To address these issues, we propose a self-reference-based AI feedback framework that enables a 13B Llama2-Chat to provide high-quality feedback under simple and general principles such as ``best for humanity``. Specifically, we allow the AI to first respond to the user's instructions, then generate criticism of other answers based on its own response as a reference, and finally determine which answer better fits human preferences according to the criticism. Additionally, we use a self-consistency method to further reduce the impact of position bias, and employ semantic perplexity to calculate the preference strength differences between different answers. Experimental results show that our method enables 13B and 70B Llama2-Chat annotators to provide high-quality preference feedback, and the policy models trained based on these preference data achieve significant advantages in benchmark datasets through reinforcement learning.
Read more6/18/2024

0
Learning from Naturally Occurring Feedback
Shachar Don-Yehiya, Leshem Choshen, Omri Abend
Human feedback data is a critical component in developing language models. However, collecting this feedback is costly and ultimately not scalable. We propose a scalable method for extracting feedback that users naturally include when interacting with chat models, and leveraging it for model training. We are further motivated by previous work that showed there are also qualitative advantages to using naturalistic (rather than auto-generated) feedback, such as less hallucinations and biases. We manually annotated conversation data to confirm the presence of naturally occurring feedback in a standard corpus, finding that as much as 30% of the chats include explicit feedback. We apply our method to over 1M conversations to obtain hundreds of thousands of feedback samples. Training with the extracted feedback shows significant performance improvements over baseline models, demonstrating the efficacy of our approach in enhancing model alignment to human preferences.
Read more7/16/2024

0
UICoder: Finetuning Large Language Models to Generate User Interface Code through Automated Feedback
Jason Wu, Eldon Schoop, Alan Leung, Titus Barik, Jeffrey P. Bigham, Jeffrey Nichols
Large language models (LLMs) struggle to consistently generate UI code that compiles and produces visually relevant designs. Existing approaches to improve generation rely on expensive human feedback or distilling a proprietary model. In this paper, we explore the use of automated feedback (compilers and multi-modal models) to guide LLMs to generate high-quality UI code. Our method starts with an existing LLM and iteratively produces improved models by self-generating a large synthetic dataset using an original model, applying automated tools to aggressively filter, score, and de-duplicate the data into a refined higher quality dataset. The original LLM is improved by finetuning on this refined dataset. We applied our approach to several open-source LLMs and compared the resulting performance to baseline models with both automated metrics and human preferences. Our evaluation shows the resulting models outperform all other downloadable baselines and approach the performance of larger proprietary models.
Read more6/13/2024