Unbiased Kinetic Langevin Monte Carlo with Inexact Gradients
2311.05025
0
0
🤯
Abstract
We present an unbiased method for Bayesian posterior means based on kinetic Langevin dynamics that combines advanced splitting methods with enhanced gradient approximations. Our approach avoids Metropolis correction by coupling Markov chains at different discretization levels in a multilevel Monte Carlo approach. Theoretical analysis demonstrates that our proposed estimator is unbiased, attains finite variance, and satisfies a central limit theorem. It can achieve accuracy $epsilon>0$ for estimating expectations of Lipschitz functions in $d$ dimensions with $mathcal{O}(d^{1/4}epsilon^{-2})$ expected gradient evaluations, without assuming warm start. We exhibit similar bounds using both approximate and stochastic gradients, and our method's computational cost is shown to scale independently of the size of the dataset. The proposed method is tested using a multinomial regression problem on the MNIST dataset and a Poisson regression model for soccer scores. Experiments indicate that the number of gradient evaluations per effective sample is independent of dimension, even when using inexact gradients. For product distributions, we give dimension-independent variance bounds. Our results demonstrate that the unbiased algorithm we present can be much more efficient than the ``gold-standard randomized Hamiltonian Monte Carlo.
Create account to get full access
Overview
- Presents an unbiased method for Bayesian posterior means based on kinetic Langevin dynamics
- Combines advanced splitting methods with enhanced gradient approximations
- Avoids Metropolis correction by coupling Markov chains at different discretization levels in a multilevel Monte Carlo approach
- Theoretical analysis shows the proposed estimator is unbiased, has finite variance, and satisfies a central limit theorem
- Can achieve accurate estimates of expectations of Lipschitz functions in high dimensions with fewer gradient evaluations than previous methods
- Tested on multinomial regression and Poisson regression problems, showing performance independent of dataset size
Plain English Explanation
This paper introduces a new technique for estimating Bayesian posterior means, which are important in Bayesian data analysis. The key idea is to use a special type of Markov Chain Monte Carlo (MCMC) method called Langevin dynamics, combined with some clever mathematical tricks.
The method avoids a common problem in MCMC called the "Metropolis correction," which can slow down convergence. Instead, it couples together Markov chains at different levels of discretization, in a multilevel Monte Carlo approach.
Theoretically, the authors show that their method is unbiased, meaning it gives the right answer on average, and has finite variance, meaning the answers don't vary too much. They also prove a central limit theorem, which tells us the answers are normally distributed around the true value.
Importantly, the method can achieve high accuracy (small error) in estimating expectations of certain functions, using fewer gradient evaluations than previous approaches - even in high dimensions. This is a big practical advantage, as gradient evaluations are often the computational bottleneck.
The authors test their method on two real-world problems: multinomial regression on the MNIST dataset, and Poisson regression for soccer scores. The results show the method's performance is independent of the dataset size, an attractive property.
Technical Explanation
The paper presents a new unbiased estimator for Bayesian posterior means based on kinetic Langevin dynamics. This combines advanced splitting methods for the Langevin dynamics with enhanced gradient approximations.
Crucially, the method avoids the Metropolis correction by coupling Markov chains at different discretization levels in a multilevel Monte Carlo framework. Theoretical analysis shows the proposed estimator is unbiased, has finite variance, and satisfies a central limit theorem.
The authors prove that their method can achieve accuracy ε > 0 for estimating expectations of Lipschitz functions in d dimensions with O(d^(1/4)ε^(-2)) expected gradient evaluations, without assuming warm start. Similar bounds are obtained using both approximate and stochastic gradients, and the computational cost is shown to scale independently of dataset size.
The method is evaluated on a multinomial regression problem using the MNIST dataset and a Poisson regression model for soccer scores. The experiments indicate the number of gradient evaluations per effective sample is independent of dimension, even when using inexact gradients. For product distributions, the authors provide dimension-independent variance bounds.
Critical Analysis
The paper presents a rigorous theoretical analysis of the proposed unbiased Bayesian posterior mean estimation method. However, some caveats and limitations are worth noting:
-
The method assumes the target function satisfies a Lipschitz condition, which may not hold in all practical settings. Further research could explore relaxing this assumption.
-
The experiments are limited to relatively simple regression problems. It would be valuable to see how the method performs on more complex Bayesian modeling tasks, such as Bayesian deep learning.
-
While the method is shown to be computationally efficient in terms of gradient evaluations, the overall runtime performance was not extensively benchmarked against alternative MCMC approaches. Broader empirical comparisons would strengthen the claims.
-
The paper does not discuss potential issues with the stability or robustness of the method, such as sensitivity to hyperparameter choices or behavior with highly multimodal posteriors. Further research could explore these aspects.
Despite these limitations, the paper presents a promising new approach that could significantly improve the efficiency of Bayesian posterior inference, especially in high-dimensional settings. The theoretical guarantees and experimental results are compelling and warrant further investigation by the research community.
Conclusion
This paper introduces a new unbiased method for estimating Bayesian posterior means that combines kinetic Langevin dynamics, advanced splitting techniques, and multilevel Monte Carlo sampling. The method is shown to be theoretically sound, with desirable properties like unbiasedness, finite variance, and a central limit theorem.
Importantly, the method can achieve high accuracy in estimating expectations of Lipschitz functions in high dimensions, using far fewer gradient evaluations than previous approaches. This efficiency advantage is demonstrated on real-world regression problems, with performance that is independent of dataset size.
While the method has some limitations, such as the Lipschitz assumption and the need for further empirical validation, it represents an important step forward in improving the scalability and reliability of Bayesian posterior inference. The novel techniques presented in this work could have wide-ranging implications for Bayesian data analysis and decision-making in fields such as machine learning, statistics, and scientific modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
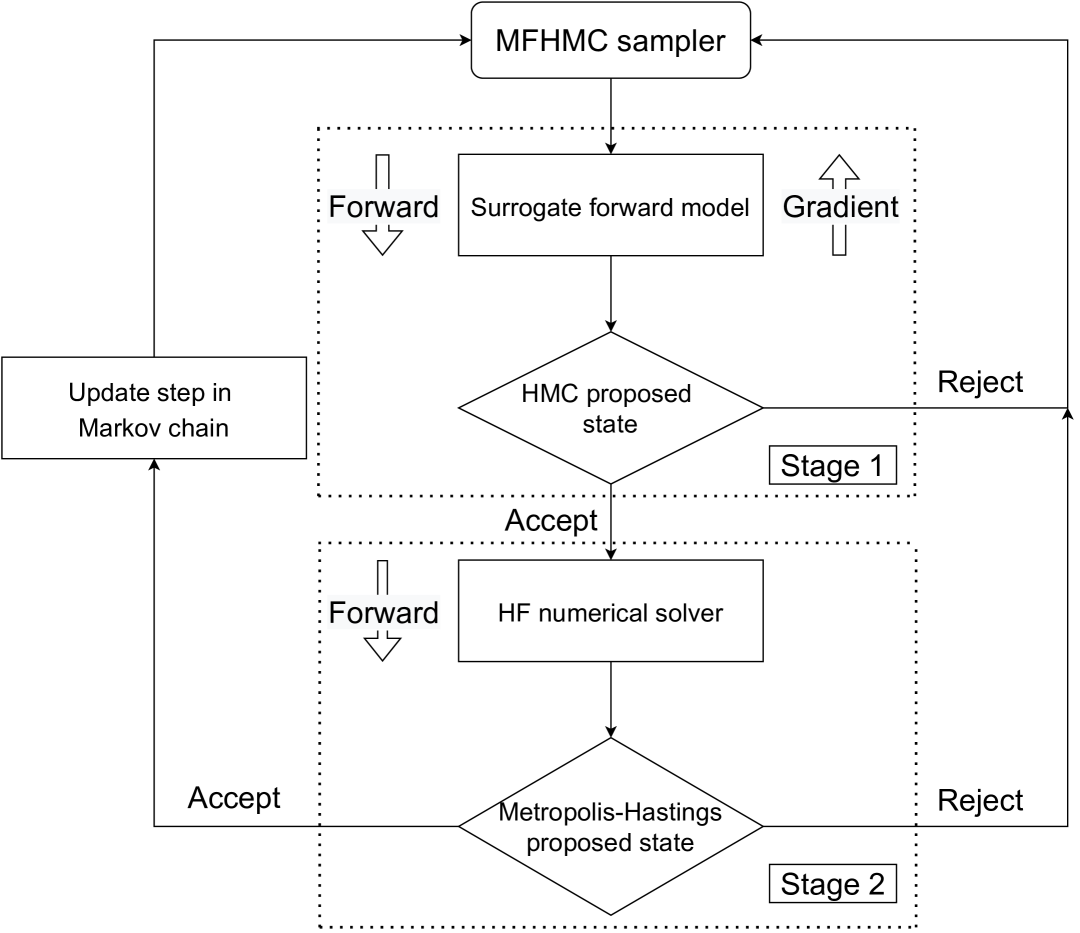
Multi-fidelity Hamiltonian Monte Carlo
Dhruv V. Patel, Jonghyun Lee, Matthew W. Farthing, Peter K. Kitanidis, Eric F. Darve
0
0
Numerous applications in biology, statistics, science, and engineering require generating samples from high-dimensional probability distributions. In recent years, the Hamiltonian Monte Carlo (HMC) method has emerged as a state-of-the-art Markov chain Monte Carlo technique, exploiting the shape of such high-dimensional target distributions to efficiently generate samples. Despite its impressive empirical success and increasing popularity, its wide-scale adoption remains limited due to the high computational cost of gradient calculation. Moreover, applying this method is impossible when the gradient of the posterior cannot be computed (for example, with black-box simulators). To overcome these challenges, we propose a novel two-stage Hamiltonian Monte Carlo algorithm with a surrogate model. In this multi-fidelity algorithm, the acceptance probability is computed in the first stage via a standard HMC proposal using an inexpensive differentiable surrogate model, and if the proposal is accepted, the posterior is evaluated in the second stage using the high-fidelity (HF) numerical solver. Splitting the standard HMC algorithm into these two stages allows for approximating the gradient of the posterior efficiently, while producing accurate posterior samples by using HF numerical solvers in the second stage. We demonstrate the effectiveness of this algorithm for a range of problems, including linear and nonlinear Bayesian inverse problems with in-silico data and experimental data. The proposed algorithm is shown to seamlessly integrate with various low-fidelity and HF models, priors, and datasets. Remarkably, our proposed method outperforms the traditional HMC algorithm in both computational and statistical efficiency by several orders of magnitude, all while retaining or improving the accuracy in computed posterior statistics.
5/9/2024
🏅
Sampling and estimation on manifolds using the Langevin diffusion
Karthik Bharath, Alexander Lewis, Akash Sharma, Michael V Tretyakov
0
0
Error bounds are derived for sampling and estimation using a discretization of an intrinsically defined Langevin diffusion with invariant measure $text{d}mu_phi propto e^{-phi} mathrm{dvol}_g $ on a compact Riemannian manifold. Two estimators of linear functionals of $mu_phi $ based on the discretized Markov process are considered: a time-averaging estimator based on a single trajectory and an ensemble-averaging estimator based on multiple independent trajectories. Imposing no restrictions beyond a nominal level of smoothness on $phi$, first-order error bounds, in discretization step size, on the bias and variance/mean-square error of both estimators are derived. The order of error matches the optimal rate in Euclidean and flat spaces, and leads to a first-order bound on distance between the invariant measure $mu_phi$ and a stationary measure of the discretized Markov process. This order is preserved even upon using retractions when exponential maps are unavailable in closed form, thus enhancing practicality of the proposed algorithms. Generality of the proof techniques, which exploit links between two partial differential equations and the semigroup of operators corresponding to the Langevin diffusion, renders them amenable for the study of a more general class of sampling algorithms related to the Langevin diffusion. Conditions for extending analysis to the case of non-compact manifolds are discussed. Numerical illustrations with distributions, log-concave and otherwise, on the manifolds of positive and negative curvature elucidate on the derived bounds and demonstrate practical utility of the sampling algorithm.
6/18/2024
🌀
Accelerating Approximate Thompson Sampling with Underdamped Langevin Monte Carlo
Haoyang Zheng, Wei Deng, Christian Moya, Guang Lin
0
0
Approximate Thompson sampling with Langevin Monte Carlo broadens its reach from Gaussian posterior sampling to encompass more general smooth posteriors. However, it still encounters scalability issues in high-dimensional problems when demanding high accuracy. To address this, we propose an approximate Thompson sampling strategy, utilizing underdamped Langevin Monte Carlo, where the latter is the go-to workhorse for simulations of high-dimensional posteriors. Based on the standard smoothness and log-concavity conditions, we study the accelerated posterior concentration and sampling using a specific potential function. This design improves the sample complexity for realizing logarithmic regrets from $mathcal{tilde O}(d)$ to $mathcal{tilde O}(sqrt{d})$. The scalability and robustness of our algorithm are also empirically validated through synthetic experiments in high-dimensional bandit problems.
6/24/2024
↗️
New!Unbiased least squares regression via averaged stochastic gradient descent
Nabil Kahal'e
0
0
We consider an on-line least squares regression problem with optimal solution $theta^*$ and Hessian matrix H, and study a time-average stochastic gradient descent estimator of $theta^*$. For $kge2$, we provide an unbiased estimator of $theta^*$ that is a modification of the time-average estimator, runs with an expected number of time-steps of order k, with O(1/k) expected excess risk. The constant behind the O notation depends on parameters of the regression and is a poly-logarithmic function of the smallest eigenvalue of H. We provide both a biased and unbiased estimator of the expected excess risk of the time-average estimator and of its unbiased counterpart, without requiring knowledge of either H or $theta^*$. We describe an average-start version of our estimators with similar properties. Our approach is based on randomized multilevel Monte Carlo. Our numerical experiments confirm our theoretical findings.
6/28/2024