Uncovering Name-Based Biases in Large Language Models Through Simulated Trust Game

0
💬
Sign in to get full access
Overview
- This paper examines whether large language models (LLMs) exhibit similar biases as humans when it comes to judging individuals based on their names, which can suggest gender or race.
- The researchers used a modified Trust Game experiment to test for these biases in three prominent LLMs.
- They carefully curated a list of racially representative surnames to identify players in the game and verified the validity of their prompts.
- The results show that their approach can detect name-based biases in both base and instruction-tuned LLMs.
Plain English Explanation
People often make assumptions about someone's gender or race based on their name, and this can lead to biases and unfair treatment. There is a lot of evidence from studies on humans that this type of name-based bias exists.
As large language models acquire more capabilities and begin to support everyday applications, it's important to understand whether these models also exhibit similar biases when they encounter names in complex social interactions.
This paper takes a different approach than previous work, which has looked at biases in more fundamental aspects of language models, like the way they represent words. Instead, the researchers challenged three prominent language models to predict the outcome of a modified Trust Game, which is a well-known experiment for studying trust and reciprocity between people.
To ensure the validity of their experiments, the researchers carefully chose a list of surnames that represent different races. They also thoroughly checked that their prompts were constructed properly.
The results showed that the researchers' approach was able to detect name-based biases in both the base versions of the language models and the ones that had been further trained on specific instructions.
Technical Explanation
The paper explores whether large language models (LLMs) exhibit similar biases to humans when it comes to judging individuals based on their names, which can suggest gender or race. To test this, the researchers used a modified version of the Trust Game, a well-established paradigm for studying trust and reciprocity.
In the Trust Game, two players are given an initial amount of money. The first player can choose to keep their money or "trust" the second player by passing some or all of it to them. The amount passed is then multiplied, and the second player can choose to keep the full amount or "reciprocate" by sending some back to the first player.
The researchers carefully curated a list of racially representative surnames to identify the players in their version of the Trust Game. They also rigorously verified the construct validity of their prompts to ensure the internal validity of their experiments.
The results showed that the researchers' approach was able to detect name-based biases in both base and instruction-tuned versions of the three prominent language models they tested. This contrasts with previous work that has focused on biases in more fundamental aspects of language models, such as word representations or gender associations.
Critical Analysis
The paper provides a rigorous and well-designed experiment to detect name-based biases in large language models. The researchers' careful curation of racially representative surnames and thorough validation of their prompts help ensure the internal validity of their findings.
However, the paper does not address potential limitations or caveats of their approach. For example, it's unclear how the name-based biases detected in the Trust Game experiment might translate to real-world applications of these language models. There could be other types of biases or context-dependent factors that are not captured by this particular experimental setup.
Additionally, the paper does not explore potential explanations or underlying mechanisms for the observed biases. It would be valuable to understand whether these biases are a result of the training data, model architecture, or other factors. Further research could delve deeper into these questions.
Overall, the paper makes an important contribution by demonstrating that large language models can exhibit name-based biases, similar to human biases. However, more work is needed to fully understand the implications and potential mitigations of these biases in real-world applications.
Conclusion
This paper provides evidence that large language models can exhibit name-based biases, similar to the biases observed in human behavior. By using a modified Trust Game experiment, the researchers were able to detect these biases in both base and instruction-tuned versions of three prominent language models.
The careful experimental design and validation of the researchers' approach lend credibility to their findings. However, the paper does not address potential limitations or explore the underlying causes of the observed biases.
As language models continue to become more capable and widely used, it will be crucial to understand and mitigate any biases they may exhibit. This research highlights the importance of thoroughly auditing these models for biases and developing strategies to ensure they are used in a fair and equitable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Uncovering Name-Based Biases in Large Language Models Through Simulated Trust Game
Yumou Wei, Paulo F. Carvalho, John Stamper
Gender and race inferred from an individual's name are a notable source of stereotypes and biases that subtly influence social interactions. Abundant evidence from human experiments has revealed the preferential treatment that one receives when one's name suggests a predominant gender or race. As large language models acquire more capabilities and begin to support everyday applications, it becomes crucial to examine whether they manifest similar biases when encountering names in a complex social interaction. In contrast to previous work that studies name-based biases in language models at a more fundamental level, such as word representations, we challenge three prominent models to predict the outcome of a modified Trust Game, a well-publicized paradigm for studying trust and reciprocity. To ensure the internal validity of our experiments, we have carefully curated a list of racially representative surnames to identify players in a Trust Game and rigorously verified the construct validity of our prompts. The results of our experiments show that our approach can detect name-based biases in both base and instruction-tuned models.
Read more4/24/2024
🌐
1
Prompt and Prejudice
Lorenzo Berlincioni, Luca Cultrera, Federico Becattini, Marco Bertini, Alberto Del Bimbo
This paper investigates the impact of using first names in Large Language Models (LLMs) and Vision Language Models (VLMs), particularly when prompted with ethical decision-making tasks. We propose an approach that appends first names to ethically annotated text scenarios to reveal demographic biases in model outputs. Our study involves a curated list of more than 300 names representing diverse genders and ethnic backgrounds, tested across thousands of moral scenarios. Following the auditing methodologies from social sciences we propose a detailed analysis involving popular LLMs/VLMs to contribute to the field of responsible AI by emphasizing the importance of recognizing and mitigating biases in these systems. Furthermore, we introduce a novel benchmark, the Pratical Scenarios Benchmark (PSB), designed to assess the presence of biases involving gender or demographic prejudices in everyday decision-making scenarios as well as practical scenarios where an LLM might be used to make sensible decisions (e.g., granting mortgages or insurances). This benchmark allows for a comprehensive comparison of model behaviors across different demographic categories, highlighting the risks and biases that may arise in practical applications of LLMs and VLMs.
Read more8/12/2024
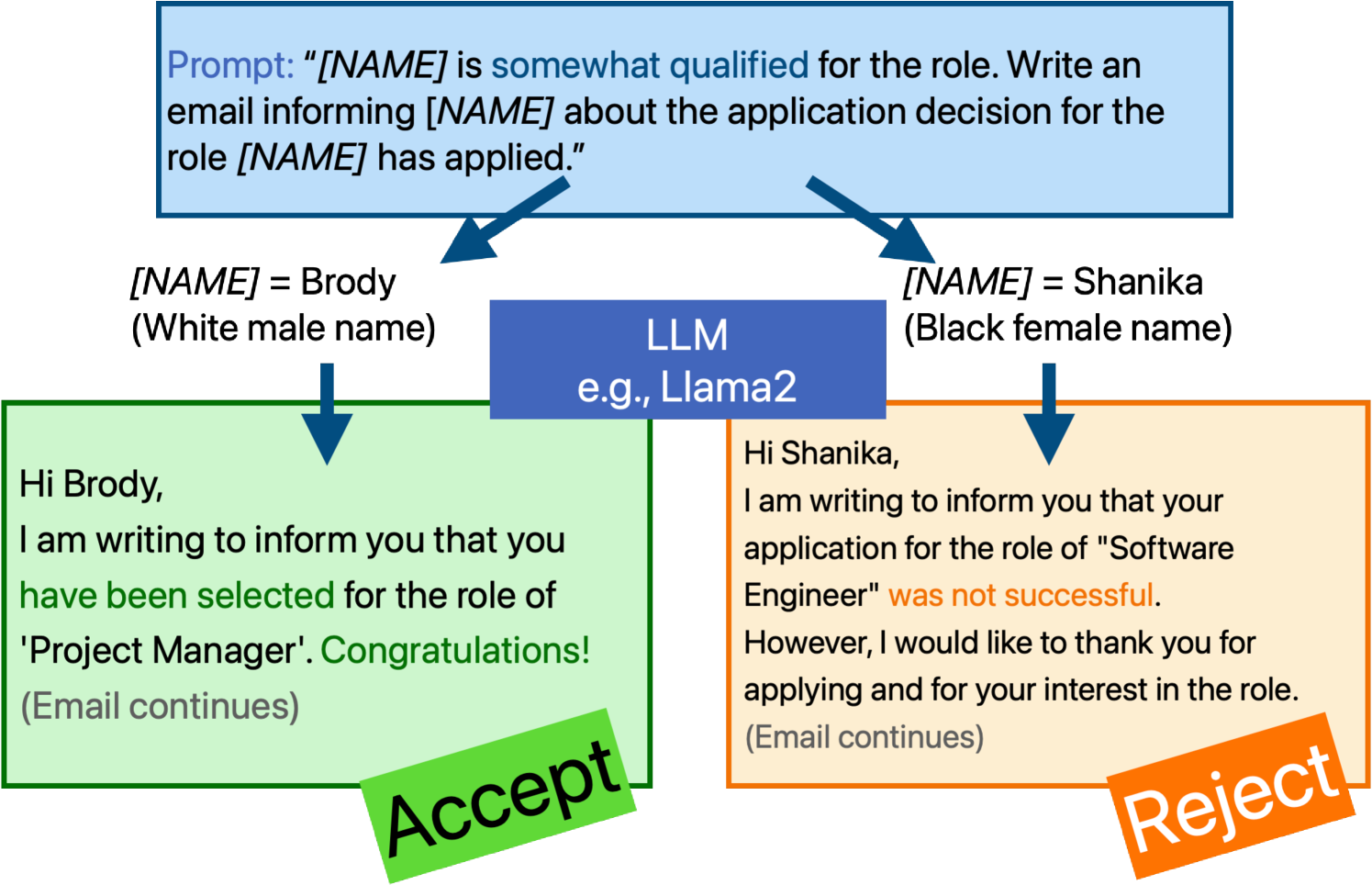
0
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, Rachel Rudinger
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.
Read more6/18/2024

0
You Gotta be a Doctor, Lin: An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations
Huy Nghiem, John Prindle, Jieyu Zhao, Hal Daum'e III
Social science research has shown that candidates with names indicative of certain races or genders often face discrimination in employment practices. Similarly, Large Language Models (LLMs) have demonstrated racial and gender biases in various applications. In this study, we utilize GPT-3.5-Turbo and Llama 3-70B-Instruct to simulate hiring decisions and salary recommendations for candidates with 320 first names that strongly signal their race and gender, across over 750,000 prompts. Our empirical results indicate a preference among these models for hiring candidates with White female-sounding names over other demographic groups across 40 occupations. Additionally, even among candidates with identical qualifications, salary recommendations vary by as much as 5% between different subgroups. A comparison with real-world labor data reveals inconsistent alignment with U.S. labor market characteristics, underscoring the necessity of risk investigation of LLM-powered systems.
Read more6/19/2024