Understanding the Performance and Estimating the Cost of LLM Fine-Tuning

0
Sign in to get full access
Overview
- This paper examines the performance and cost of fine-tuning large language models (LLMs) on different tasks.
- The researchers investigate the tradeoffs between model accuracy, inference time, and computational cost for fine-tuning.
- They provide insights to help practitioners make informed decisions when deploying LLMs in real-world applications.
Plain English Explanation
The paper looks at the process of fine-tuning - where you take a powerful, pre-trained language model and adapt it to work well on a specific task. This is an important technique for getting high-performing AI models without having to train everything from scratch.
The researchers explored how the fine-tuning process affects a few key things:
- Model Accuracy: How well the fine-tuned model performs on the target task.
- Inference Time: How quickly the model can generate outputs when deployed.
- Computational Cost: The resources (like GPU time and energy) needed to fine-tune the model.
They wanted to understand the tradeoffs between these factors - for example, a fine-tuned model might be very accurate, but take a long time to generate outputs, or require a lot of expensive computing power to train. This information can help AI practitioners make smart choices when deploying LLMs in real-world applications.
Technical Explanation
The paper examines the performance and cost of fine-tuning large language models (LLMs) on different tasks. The researchers investigate the tradeoffs between model accuracy, inference time, and computational cost when fine-tuning LLMs.
They conduct experiments on several popular LLMs, including GPT-3, Megatron-LM, and PaLM, fine-tuning them on a range of downstream tasks. Their analysis provides insights into the performance characteristics and resource requirements of fine-tuned LLMs.
Key findings include:
- Fine-tuning can significantly improve model accuracy on specific tasks, but this comes at the cost of increased inference time and computational resources.
- There are ways to mitigate the performance/cost tradeoff, such as using efficient mixture-of-experts architectures or sparsity-inducing techniques.
- The optimal fine-tuning strategy depends on the specific use case and requirements, and the researchers provide guidance to help practitioners make informed decisions.
Critical Analysis
The paper provides a comprehensive analysis of the performance and cost tradeoffs in fine-tuning LLMs, which is a crucial practical consideration for deploying these models in real-world applications.
However, the analysis is limited to a specific set of LLMs and tasks, and the researchers acknowledge that the results may not generalize to all possible fine-tuning scenarios. Additionally, the paper does not explore the potential for further optimizations, such as using specialized hardware or exploring alternative fine-tuning techniques.
It would also be valuable for the paper to delve deeper into the implications of the fine-tuning tradeoffs for different application domains. For example, the requirements for a high-accuracy, low-latency model in a safety-critical system may differ significantly from the needs of a more casual language-based application.
Overall, the paper provides a solid foundation for understanding the performance and cost considerations of LLM fine-tuning, but there is room for further research to expand the scope and applicability of the insights.
Conclusion
This paper offers valuable insights into the practical considerations of fine-tuning large language models for specific tasks. By exploring the tradeoffs between model accuracy, inference time, and computational cost, the researchers provide guidance to help AI practitioners make informed decisions when deploying LLMs in real-world applications.
The findings highlight the importance of carefully balancing performance and efficiency requirements, and the researchers suggest several techniques that can help mitigate the inherent tradeoffs. While the analysis is limited in scope, the paper lays the groundwork for further research to expand our understanding of fine-tuning LLMs and optimize their deployment in a wide range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding the Performance and Estimating the Cost of LLM Fine-Tuning
Yuchen Xia (Callie), Jiho Kim (Callie), Yuhan Chen (Callie), Haojie Ye (Callie), Souvik Kundu (Callie), Cong (Callie), Hao, Nishil Talati
Due to the cost-prohibitive nature of training Large Language Models (LLMs), fine-tuning has emerged as an attractive alternative for specializing LLMs for specific tasks using limited compute resources in a cost-effective manner. In this paper, we characterize sparse Mixture of Experts (MoE) based LLM fine-tuning to understand their accuracy and runtime performance on a single GPU. Our evaluation provides unique insights into the training efficacy of sparse and dense versions of MoE models, as well as their runtime characteristics, including maximum batch size, execution time breakdown, end-to-end throughput, GPU hardware utilization, and load distribution. Our study identifies the optimization of the MoE layer as crucial for further improving the performance of LLM fine-tuning. Using our profiling results, we also develop and validate an analytical model to estimate the cost of LLM fine-tuning on the cloud. This model, based on parameters of the model and GPU architecture, estimates LLM throughput and the cost of training, aiding practitioners in industry and academia to budget the cost of fine-tuning a specific model.
Read more8/12/2024
0
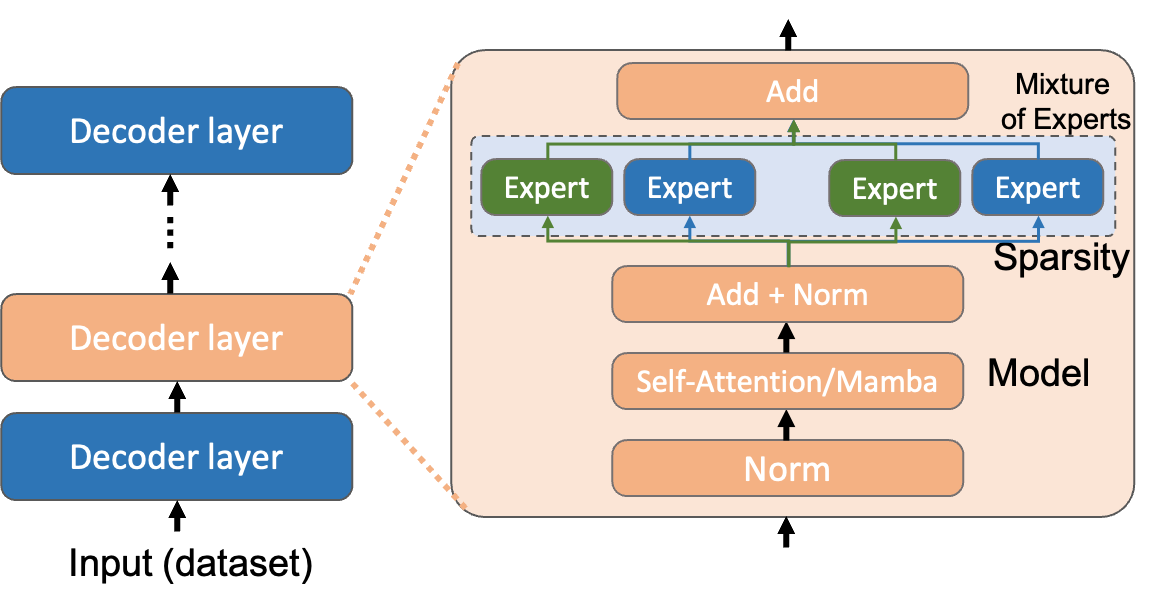
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
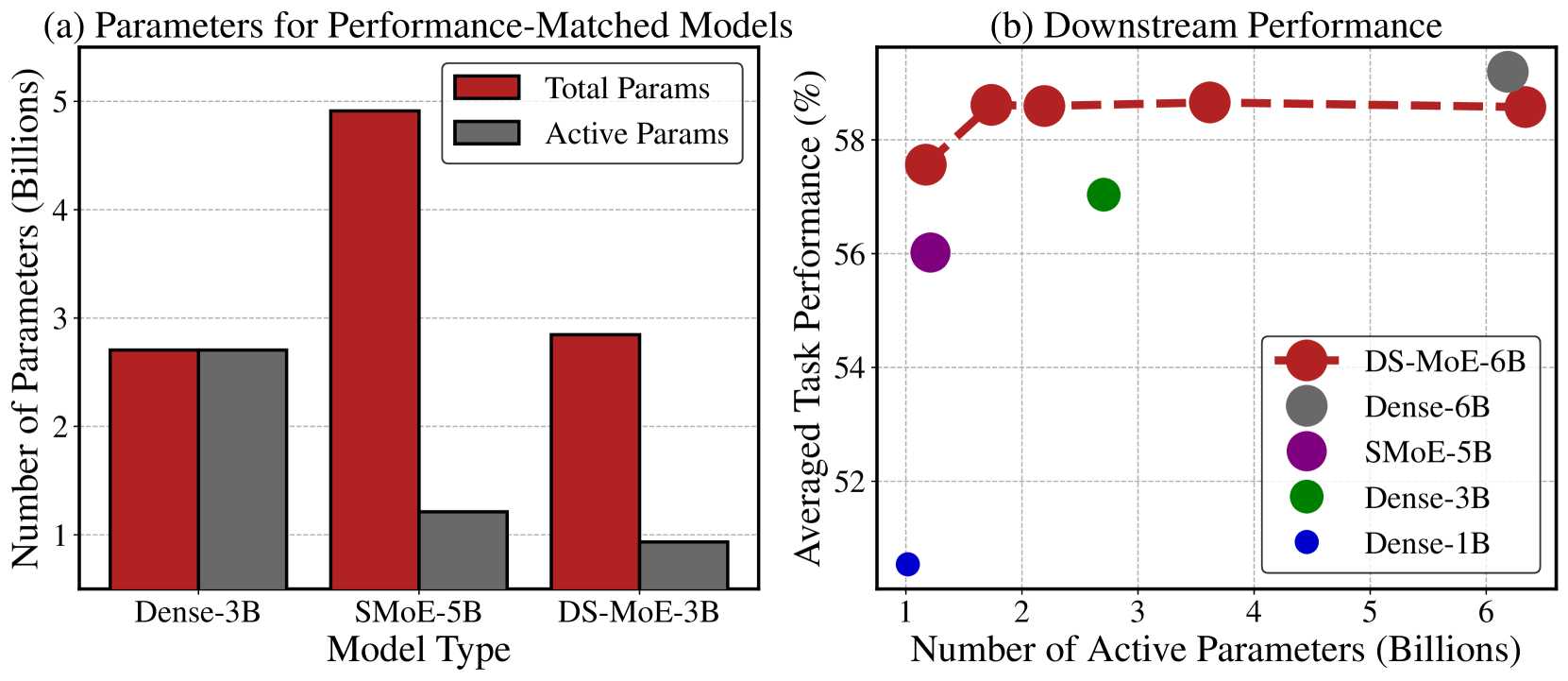
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Read more4/9/2024
0
Toward Inference-optimal Mixture-of-Expert Large Language Models
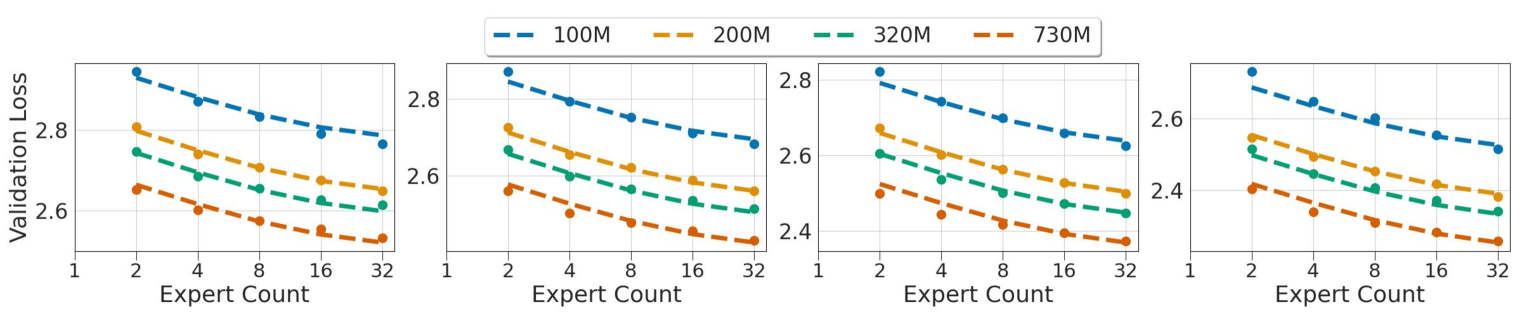
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
Read more4/4/2024

0
Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training
Xianzhi Du, Tom Gunter, Xiang Kong, Mark Lee, Zirui Wang, Aonan Zhang, Nan Du, Ruoming Pang
Mixture-of-Experts (MoE) enjoys performance gain by increasing model capacity while keeping computation cost constant. When comparing MoE to dense models, prior work typically adopt the following setting: 1) use FLOPs or activated parameters as a measure of model complexity; 2) train all models to the same number of tokens. We argue that this setting favors MoE as FLOPs and activated parameters do not accurately measure the communication overhead in sparse layers, leading to a larger actual training budget for MoE. In this work, we revisit the settings by adopting step time as a more accurate measure of model complexity, and by determining the total compute budget under the Chinchilla compute-optimal settings. To efficiently run MoE on modern accelerators, we adopt a 3D sharding method that keeps the dense-to-MoE step time increase within a healthy range. We evaluate MoE and dense LLMs on a set of nine 0-shot and two 1-shot English tasks, as well as MMLU 5-shot and GSM8K 8-shot across three model scales at 6.4B, 12.6B, and 29.6B. Experimental results show that even under these settings, MoE consistently outperform dense LLMs on the speed-accuracy trade-off curve with meaningful gaps. Our full model implementation and sharding strategy has been released at~url{https://github.com/apple/axlearn}
Read more7/2/2024