A Unified Approach to Multi-task Legged Navigation: Temporal Logic Meets Reinforcement Learning

0

Sign in to get full access
Related Work
This paper builds upon previous research in the fields of legged navigation, reinforcement learning, and temporal logic. The authors note that while prior work has explored the use of temporal logic for robot control and task planning, there has been limited research on integrating temporal logic with reinforcement learning for multi-task legged navigation.
One relevant line of research is Reactive Temporal Logic-Based Planning and Control for Interactive Robots, which used temporal logic to specify robot behaviors and combined it with model predictive control. Another related area is Decomposition-Based Hierarchical Task Allocation and Planning for Multi-Robot Systems, which developed a hierarchical planning framework for multi-robot systems.
The authors also highlight research on Logical Specifications Guided Dynamic Task Sampling for Reinforcement Learning, which used temporal logic to guide the exploration process in reinforcement learning, and Prioritize Team Actions for Multi-Agent Temporal Logic Planning, which focused on multi-agent temporal logic planning.
Additionally, the paper draws inspiration from work on Fast Adaptive Multi-Agent Planning under Collaborative Temporal Logic Constraints, which developed a decentralized planning algorithm for multi-agent systems subject to temporal logic constraints.
Overview
The paper presents a unified approach to multi-task legged navigation that combines temporal logic and reinforcement learning. The key idea is to use temporal logic to specify high-level navigation tasks and then leverage reinforcement learning to learn low-level control policies that can accomplish these tasks.
Plain English Explanation
The researchers wanted to create a system that could handle multiple navigation tasks for legged robots, such as navigating through obstacles, reaching specific locations, or avoiding hazards. To do this, they combined two powerful techniques: temporal logic and reinforcement learning.
Temporal logic is a way of specifying high-level tasks or behaviors that the robot should follow, like "go to the red marker and then the blue marker, while avoiding the obstacles." Reinforcement learning is a machine learning technique that allows the robot to learn low-level control policies, like how to move its legs to actually accomplish those tasks.
By combining these two approaches, the researchers developed a system that can take high-level temporal logic specifications and use reinforcement learning to automatically learn the best way for the legged robot to carry out those tasks. This allows the robot to handle complex, multi-part navigation challenges in a flexible and adaptive way.
Technical Explanation
The paper proposes a framework that integrates temporal logic and reinforcement learning for multi-task legged navigation. The high-level navigation tasks are specified using temporal logic, which provides a formal language for describing the desired robot behaviors, such as reaching specific locations, avoiding obstacles, or sequencing multiple sub-tasks.
The authors then leverage reinforcement learning to automatically learn low-level control policies that can accomplish these temporal logic specifications. Specifically, they use a deep reinforcement learning algorithm to train a neural network-based policy that maps the robot's state (e.g., joint angles, velocities, and sensor readings) to appropriate actions (e.g., joint torques) to execute the specified tasks.
The key innovation is that the reinforcement learning process is guided by the temporal logic specifications, which inform the reward function and the exploration strategy. This enables the robot to efficiently learn control policies that satisfy the high-level task requirements, even in complex, multi-task scenarios.
The authors demonstrate the effectiveness of their approach through simulation experiments on a quadrupedal robot navigating various environments with obstacles and multiple waypoints to reach. The results show that the integrated temporal logic and reinforcement learning framework can successfully accomplish complex navigation tasks that would be challenging for conventional control approaches.
Critical Analysis
The paper presents a promising approach for combining temporal logic and reinforcement learning for multi-task legged navigation. The authors convincingly demonstrate the value of this integration, as the temporal logic specifications provide a clear and intuitive way to express the desired robot behaviors, while the reinforcement learning component enables the robot to learn the low-level control policies needed to execute those behaviors.
One potential limitation of the work is that it has only been evaluated in simulation, and it remains to be seen how well the approach would translate to real-world legged robots, which may have additional complexities and uncertainties not captured in the simulated environments.
Additionally, the paper does not explore the scalability of the approach as the complexity of the navigation tasks or the number of robots increases. Further research may be needed to understand how the framework would handle more challenging, large-scale multi-robot scenarios.
Another area for potential improvement is the integration of the temporal logic and reinforcement learning components. While the authors have demonstrated the benefits of this integration, there may be opportunities to further refine the interaction between the two components, such as by allowing the reinforcement learning process to provide feedback to refine the temporal logic specifications or by exploring more sophisticated ways of guiding the exploration and learning process.
Conclusion
This paper presents a novel and promising approach to multi-task legged navigation that combines the strengths of temporal logic and reinforcement learning. By using temporal logic to specify high-level navigation tasks and reinforcement learning to automatically learn the low-level control policies, the researchers have developed a flexible and adaptive system that can handle complex, multi-part navigation challenges.
The key contributions of this work are the integration of these two powerful techniques and the demonstration of their effectiveness in simulation. While further research is needed to fully understand the scalability and real-world applicability of the approach, this paper represents an important step forward in the field of legged robotics and autonomous navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Approach to Multi-task Legged Navigation: Temporal Logic Meets Reinforcement Learning
Jesse Jiang, Samuel Coogan, Ye Zhao
This study examines the problem of hopping robot navigation planning to achieve simultaneous goal-directed and environment exploration tasks. We consider a scenario in which the robot has mandatory goal-directed tasks defined using Linear Temporal Logic (LTL) specifications as well as optional exploration tasks represented using a reward function. Additionally, there exists uncertainty in the robot dynamics which results in motion perturbation. We first propose an abstraction of 3D hopping robot dynamics which enables high-level planning and a neural-network-based optimization for low-level control. We then introduce a Multi-task Product IMDP (MT-PIMDP) model of the system and tasks. We propose a unified control policy synthesis algorithm which enables both task-directed goal-reaching behaviors as well as task-agnostic exploration to learn perturbations and reward. We provide a formal proof of the trade-off induced by prioritizing either LTL or RL actions. We demonstrate our methods with simulation case studies in a 2D world navigation environment.
Read more7/10/2024
🛸
0
Simultaneous Task Allocation and Planning for Multi-Robots under Hierarchical Temporal Logic Specifications
Xusheng Luo, Changliu Liu
Research in robotic planning with temporal logic specifications, such as syntactically co-safe Linear Temporal Logic (sc-LTL), has relied on single formulas. However, as task complexity increases, sc-LTL formulas become lengthy, making them difficult to interpret and generate, and straining the computational capacities of planners. To address this, we introduce a hierarchical structure to sc-LTL specifications with both syntax and semantics, proving it to be more expressive than flat counterparts. We conducted a user study that compared the flat sc-LTL with our hierarchical version and found that users could more easily comprehend complex tasks using the hierarchical structure. We develop a search-based approach to synthesize plans for multi-robot systems, achieving simultaneous task allocation and planning. This method approximates the search space by loosely interconnected sub-spaces, each corresponding to an sc-LTL specification. The search primarily focuses on a single sub-space, transitioning to another under conditions determined by the decomposition of automatons. We develop multiple heuristics to significantly expedite the search. Our theoretical analysis, conducted under mild assumptions, addresses completeness and optimality. Compared to existing methods used in various simulators for service tasks, our approach improves planning times while maintaining comparable solution quality.
Read more8/16/2024
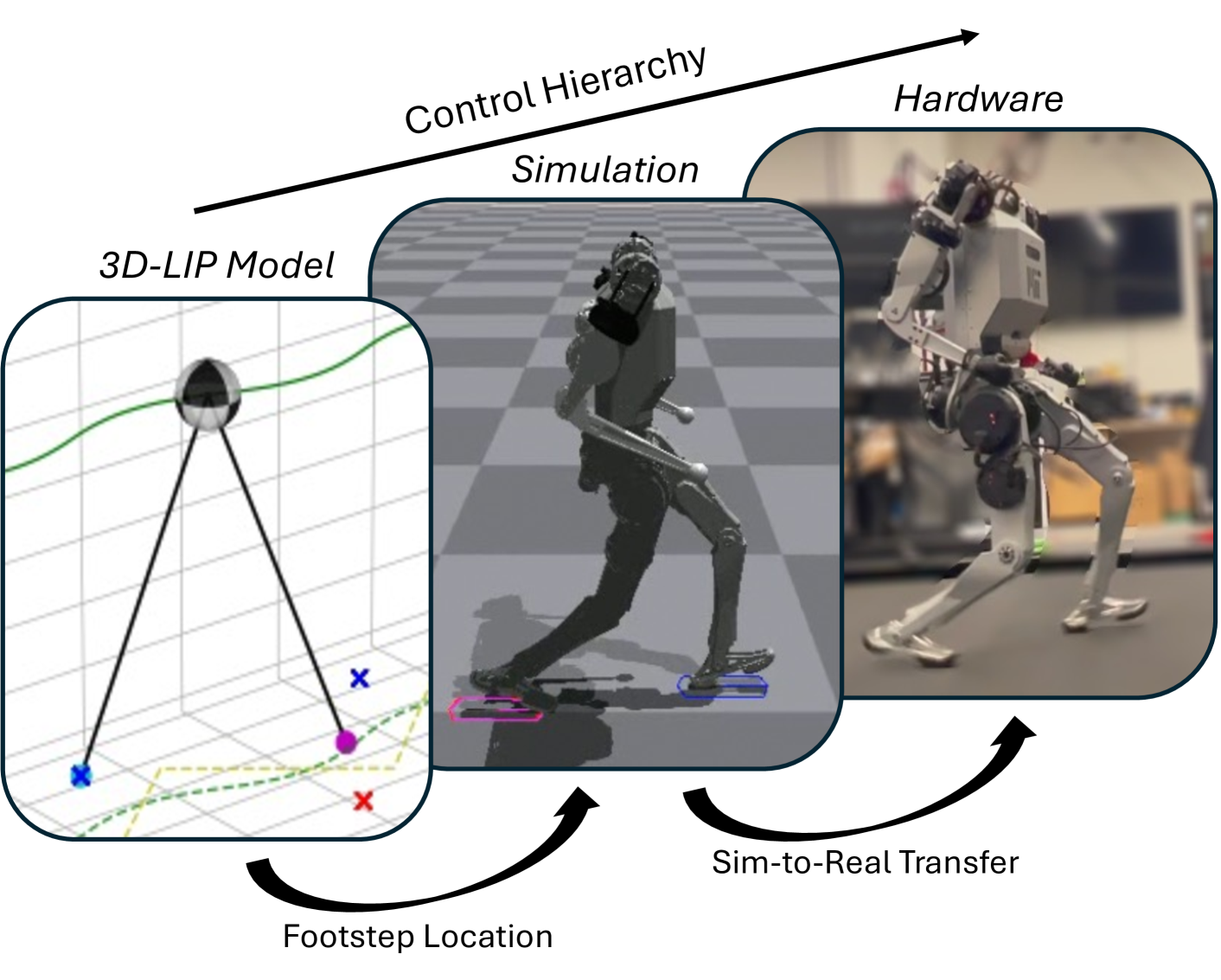
0
Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion
Ho Jae Lee, Seungwoo Hong, Sangbae Kim
In this work, we introduce a control framework that combines model-based footstep planning with Reinforcement Learning (RL), leveraging desired footstep patterns derived from the Linear Inverted Pendulum (LIP) dynamics. Utilizing the LIP model, our method forward predicts robot states and determines the desired foot placement given the velocity commands. We then train an RL policy to track the foot placements without following the full reference motions derived from the LIP model. This partial guidance from the physics model allows the RL policy to integrate the predictive capabilities of the physics-informed dynamics and the adaptability characteristics of the RL controller without overfitting the policy to the template model. Our approach is validated on the MIT Humanoid, demonstrating that our policy can achieve stable yet dynamic locomotion for walking and turning. We further validate the adaptability and generalizability of our policy by extending the locomotion task to unseen, uneven terrain. During the hardware deployment, we have achieved forward walking speeds of up to 1.5 m/s on a treadmill and have successfully performed dynamic locomotion maneuvers such as 90-degree and 180-degree turns.
Read more8/6/2024
➖
0
Reactive Temporal Logic-based Planning and Control for Interactive Robotic Tasks
Farhad Nawaz, Shaoting Peng, Lars Lindemann, Nadia Figueroa, Nikolai Matni
Robots interacting with humans must be safe, reactive and adapt online to unforeseen environmental and task changes. Achieving these requirements concurrently is a challenge as interactive planners lack formal safety guarantees, while safe motion planners lack flexibility to adapt. To tackle this, we propose a modular control architecture that generates both safe and reactive motion plans for human-robot interaction by integrating temporal logic-based discrete task level plans with continuous Dynamical System (DS)-based motion plans. We formulate a reactive temporal logic formula that enables users to define task specifications through structured language, and propose a planning algorithm at the task level that generates a sequence of desired robot behaviors while being adaptive to environmental changes. At the motion level, we incorporate control Lyapunov functions and control barrier functions to compute stable and safe continuous motion plans for two types of robot behaviors: (i) complex, possibly periodic motions given by autonomous DS and (ii) time-critical tasks specified by Signal Temporal Logic~(STL). Our methodology is demonstrated on the Franka robot arm performing wiping tasks on a whiteboard and a mannequin that is compliant to human interactions and adaptive to environmental changes.
Read more5/1/2024