Unifying Multimodal Retrieval via Document Screenshot Embedding

0

Sign in to get full access
Overview
- This paper presents a novel approach for unifying multimodal retrieval by leveraging document screenshots as a common representation.
- The authors propose a Document Screenshot Embedding (DocSE) model that can jointly encode text, images, and document layouts to enable cross-modal retrieval.
- The DocSE model is trained on a large-scale dataset of document screenshots and demonstrates strong performance on various multimodal retrieval tasks.
Plain English Explanation
The paper introduces a new way to search for information across different types of data, like text, images, and documents. The key idea is to use screenshots of documents as a common representation that can connect these different modalities.
The researchers developed a model called Document Screenshot Embedding (DocSE) that can understand the content and layout of document screenshots. This allows the model to search for relevant information, even if it's in a different format than what the user is looking for. For example, you could search for a specific chart or diagram, and the model would find relevant documents that contain that visual information.
The DocSE model is trained on a large dataset of document screenshots, which helps it learn how to effectively represent and connect the different types of information found in documents. This allows the model to perform well on a variety of multimodal retrieval tasks, where users can search for information across text, images, and document layouts.
By using document screenshots as a unifying representation, this approach can make it easier for people to find the information they need, regardless of how it's presented. This could be especially useful in fields like research, education, or business, where people often need to work with a mix of textual, visual, and document-based information.
Technical Explanation
The key innovation in this paper is the Document Screenshot Embedding (DocSE) model, which can jointly encode text, images, and document layouts into a shared embedding space. This allows the model to perform cross-modal retrieval, where users can search for relevant information regardless of its format.
The DocSE model is based on a transformer-based architecture that takes a document screenshot as input and learns to predict the corresponding textual content, visual elements, and document structure. The model is trained on a large-scale dataset of document screenshots collected from the web, which helps it learn robust representations of the different modalities.
The learned embeddings from the DocSE model can then be used for various multimodal retrieval tasks, such as:
- Searching for relevant documents based on a text query
- Finding documents that contain a specific visual element
- Retrieving documents that match a user-provided document screenshot
The authors evaluate the DocSE model on several benchmark datasets and show that it outperforms existing approaches for multimodal retrieval. The strong performance of the DocSE model demonstrates the effectiveness of using document screenshots as a common representation to unify different modalities.
Critical Analysis
One potential limitation of the DocSE model is that it relies on the availability of high-quality document screenshots, which may not always be easy to obtain. The model's performance could be affected by factors like image quality, document layout complexity, and the diversity of the training dataset.
Additionally, the paper does not provide much insight into the model's robustness to various types of document formats or layouts. It would be valuable to understand how well the model performs on documents with different structures, such as forms, tables, or handwritten notes.
Another area for further research could be to investigate ways to incorporate additional modalities, such as audio or video, into the unified retrieval framework. This could further enhance the model's ability to handle diverse types of information found in modern documents and data sources.
Conclusion
The Unifying Multimodal Retrieval via Document Screenshot Embedding paper presents a novel approach for bridging the gap between different data modalities in information retrieval. By leveraging document screenshots as a common representation, the proposed DocSE model can effectively connect and search across text, images, and document layouts.
The strong performance of the DocSE model on various multimodal retrieval tasks suggests that this approach could have significant practical applications in fields where users need to work with a diverse range of information sources. Further research to address the identified limitations and expand the model's capabilities could lead to even more powerful and versatile multimodal retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unifying Multimodal Retrieval via Document Screenshot Embedding
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, Jimmy Lin
In the real world, documents are organized in different formats and varied modalities. Traditional retrieval pipelines require tailored document parsing techniques and content extraction modules to prepare input for indexing. This process is tedious, prone to errors, and has information loss. To this end, we propose Document Screenshot Embedding} (DSE), a novel retrieval paradigm that regards document screenshots as a unified input format, which does not require any content extraction preprocess and preserves all the information in a document (e.g., text, image and layout). DSE leverages a large vision-language model to directly encode document screenshots into dense representations for retrieval. To evaluate our method, we first craft the dataset of Wiki-SS, a 1.3M Wikipedia web page screenshots as the corpus to answer the questions from the Natural Questions dataset. In such a text-intensive document retrieval setting, DSE shows competitive effectiveness compared to other text retrieval methods relying on parsing. For example, DSE outperforms BM25 by 17 points in top-1 retrieval accuracy. Additionally, in a mixed-modality task of slide retrieval, DSE significantly outperforms OCR text retrieval methods by over 15 points in nDCG@10. These experiments show that DSE is an effective document retrieval paradigm for diverse types of documents. Model checkpoints, code, and Wiki-SS collection will be released.
Read more6/18/2024

0
READoc: A Unified Benchmark for Realistic Document Structured Extraction
Zichao Li, Aizier Abulaiti, Yaojie Lu, Xuanang Chen, Jia Zheng, Hongyu Lin, Xianpei Han, Le Sun
Document Structured Extraction (DSE) aims to extract structured content from raw documents. Despite the emergence of numerous DSE systems, their unified evaluation remains inadequate, significantly hindering the field's advancement. This problem is largely attributed to existing benchmark paradigms, which exhibit fragmented and localized characteristics. To address these limitations and offer a thorough evaluation of DSE systems, we introduce a novel benchmark named READoc, which defines DSE as a realistic task of converting unstructured PDFs into semantically rich Markdown. The READoc dataset is derived from 2,233 diverse and real-world documents from arXiv and GitHub. In addition, we develop a DSE Evaluation S$^3$uite comprising Standardization, Segmentation and Scoring modules, to conduct a unified evaluation of state-of-the-art DSE approaches. By evaluating a range of pipeline tools, expert visual models, and general VLMs, we identify the gap between current work and the unified, realistic DSE objective for the first time. We aspire that READoc will catalyze future research in DSE, fostering more comprehensive and practical solutions.
Read more9/10/2024
🧪
0
MARVEL: Unlocking the Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
Tianshuo Zhou, Sen Mei, Xinze Li, Zhenghao Liu, Chenyan Xiong, Zhiyuan Liu, Yu Gu, Ge Yu
This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL), which learns an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of the well-trained dense retriever, T5-ANCE, by incorporating the visual module's encoded image features as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and extracts the related text and image documents from anchor-linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. MARVEL provides an opportunity to broaden the advantages of text retrieval to the multi-modal scenario. Besides, we also illustrate that the language model has the ability to extract image semantics and partly map the image features to the input word embedding space. All codes are available at https://github.com/OpenMatch/MARVEL.
Read more6/18/2024
0
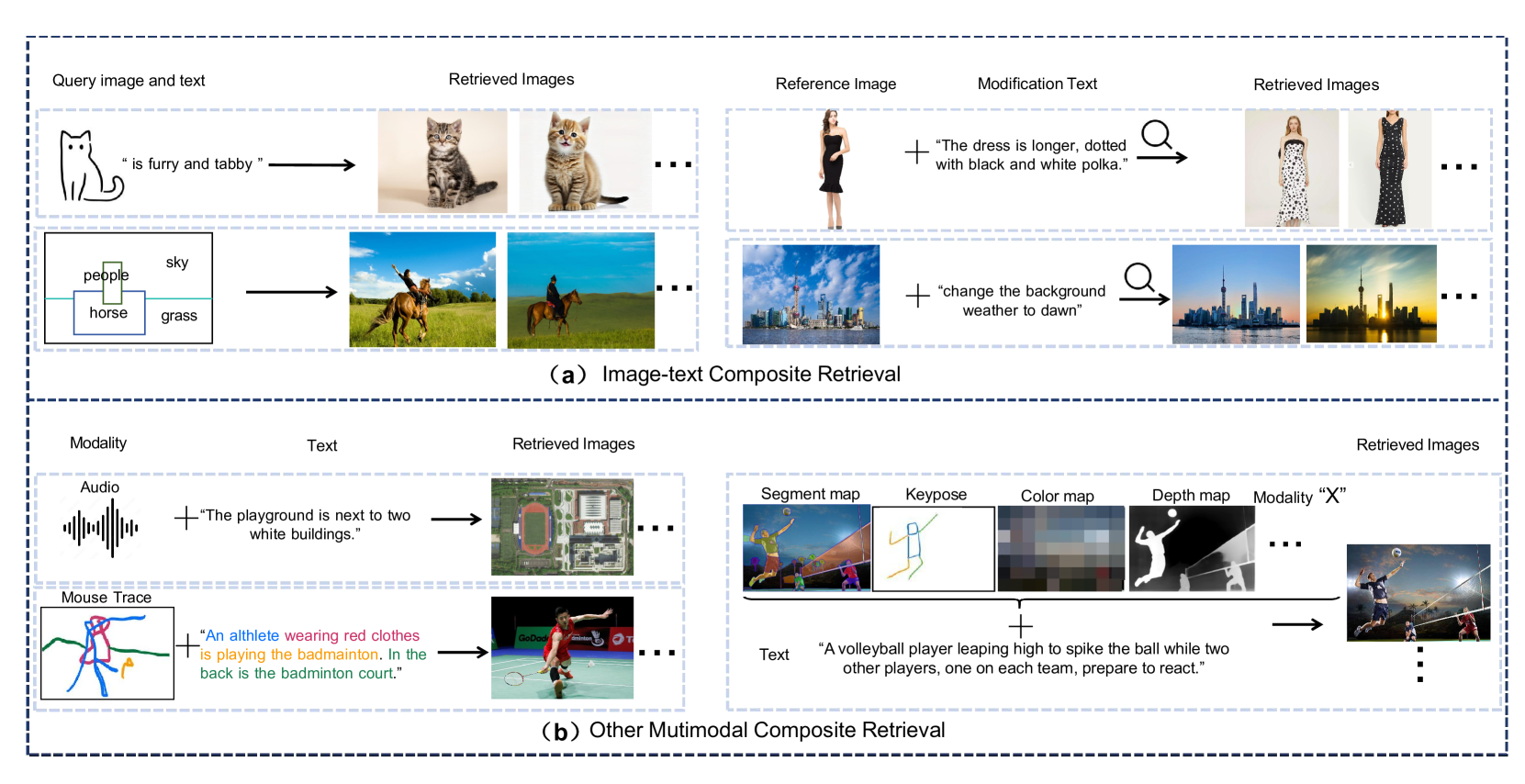
A Survey of Multimodal Composite Editing and Retrieval
Suyan Li, Fuxiang Huang, Lei Zhang
In the real world, where information is abundant and diverse across different modalities, understanding and utilizing various data types to improve retrieval systems is a key focus of research. Multimodal composite retrieval integrates diverse modalities such as text, image and audio, etc. to provide more accurate, personalized, and contextually relevant results. To facilitate a deeper understanding of this promising direction, this survey explores multimodal composite editing and retrieval in depth, covering image-text composite editing, image-text composite retrieval, and other multimodal composite retrieval. In this survey, we systematically organize the application scenarios, methods, benchmarks, experiments, and future directions. Multimodal learning is a hot topic in large model era, and have also witnessed some surveys in multimodal learning and vision-language models with transformers published in the PAMI journal. To the best of our knowledge, this survey is the first comprehensive review of the literature on multimodal composite retrieval, which is a timely complement of multimodal fusion to existing reviews. To help readers' quickly track this field, we build the project page for this survey, which can be found at https://github.com/fuxianghuang1/Multimodal-Composite-Editing-and-Retrieval.
Read more9/12/2024