Unintended Impacts of LLM Alignment on Global Representation

0
Sign in to get full access
Overview
- This paper examines the unintended impacts of large language model (LLM) alignment on global representation and diversity.
- The researchers explore how efforts to align LLMs with human preferences can lead to the marginalization of certain groups and perspectives.
- They present a framework for analyzing these issues and suggest potential mitigation strategies.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text. As these models become more advanced, there are growing efforts to align them with human values and preferences. This involves training the models to produce outputs that match what humans want.
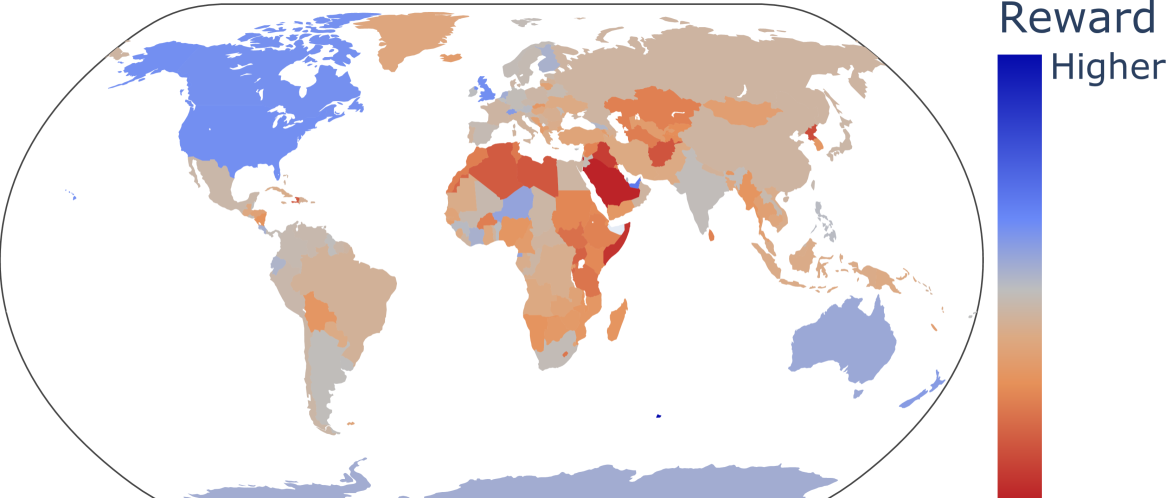
However, this paper argues that the process of alignment can have unintended consequences. By optimizing the models to match a specific set of preferences, the diversity of viewpoints and perspectives represented in the model's outputs may be reduced. This could lead to the marginalization of certain groups or ideas.
The authors propose a framework for understanding and analyzing these issues. They suggest that the global representation of a language model can be thought of as a "landscape" - a multidimensional space of possible outputs. Alignment efforts may flatten or distort this landscape, reducing the overall diversity.
The paper also discusses potential mitigation strategies, such as incorporating more diverse training data or using reinforcement learning techniques that can preserve diversity while still aligning the model with human preferences.
Overall, this research highlights an important but often overlooked issue in the development of advanced AI systems. As we strive to make these models more useful and aligned with human values, we must be mindful of the potential unintended consequences and work to maintain a rich diversity of perspectives.
Technical Explanation
The paper begins by outlining the concept of global representation in the context of large language models (LLMs). The authors argue that the outputs of these models can be thought of as occupying a multidimensional "landscape" of possible text, with different regions representing different styles, topics, and viewpoints.
The researchers then explore how efforts to align LLMs with human preferences can inadvertently distort or flatten this landscape. By optimizing the models to generate outputs that match a specific set of human-approved examples, the diversity of perspectives and ideas represented in the model's outputs may be reduced.
To analyze this phenomenon, the authors present a framework that decomposes the global representation of an LLM into two key components: fidelity (the accuracy with which the model matches the training data) and diversity (the breadth of perspectives and ideas covered).
Using this framework, the researchers demonstrate through experiments how different alignment strategies can impact these two components in different ways. For example, they show that linear alignment techniques can preserve diversity but may reduce fidelity, while other methods may prioritize fidelity at the expense of diversity.
The paper also discusses potential mitigation strategies, such as incorporating more diverse training data or using reinforcement learning techniques that can balance the trade-off between fidelity and diversity.
Overall, the technical contributions of this paper include the development of a framework for analyzing global representation in LLMs, the empirical demonstration of the unintended impacts of alignment on diversity, and the exploration of potential mitigation strategies.
Critical Analysis
The paper raises an important issue that is often overlooked in the development of large language models. While the goal of aligning these models with human preferences is understandable, the authors rightly point out that this process can have unintended consequences for the diversity of perspectives represented.
One potential limitation of the research is the specific metrics and experimental setup used to measure diversity. The authors acknowledge that their framework is just one way of conceptualizing and quantifying global representation, and there may be other valid approaches.
Additionally, the paper focuses primarily on the alignment process itself, without delving deeply into the broader societal implications of reduced diversity in language model outputs. Further research could explore how these issues intersect with questions of fairness, inclusivity, and the equitable representation of marginalized groups.
Despite these potential areas for further exploration, the paper makes a valuable contribution by drawing attention to an important issue that deserves more attention in the AI research community. As we continue to develop increasingly powerful language models, it will be crucial to carefully consider the potential unintended impacts on global representation and work to mitigate any negative consequences.
Conclusion
This paper highlights a critical but often overlooked issue in the development of large language models: the unintended impacts of alignment efforts on global representation and diversity.
The researchers present a framework for analyzing these issues, demonstrating how the process of aligning LLMs with human preferences can inadvertently distort the "landscape" of possible model outputs, reducing the diversity of perspectives and ideas represented.
By raising awareness of this problem and proposing potential mitigation strategies, the paper encourages AI researchers and developers to think more holistically about the societal implications of their work. As these powerful language models become increasingly prevalent, it will be essential to ensure that their outputs reflect the rich diversity of human experiences and viewpoints, rather than reinforcing the marginalization of certain groups or ideas.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unintended Impacts of LLM Alignment on Global Representation
Michael J. Ryan, William Held, Diyi Yang
Before being deployed for user-facing applications, developers align Large Language Models (LLMs) to user preferences through a variety of procedures, such as Reinforcement Learning From Human Feedback (RLHF) and Direct Preference Optimization (DPO). Current evaluations of these procedures focus on benchmarks of instruction following, reasoning, and truthfulness. However, human preferences are not universal, and aligning to specific preference sets may have unintended effects. We explore how alignment impacts performance along three axes of global representation: English dialects, multilingualism, and opinions from and about countries worldwide. Our results show that current alignment procedures create disparities between English dialects and global opinions. We find alignment improves capabilities in several languages. We conclude by discussing design decisions that led to these unintended impacts and recommendations for more equitable preference tuning. We make our code and data publicly available on Github.
Read more6/10/2024

0
Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
Read more8/9/2024

0
Investigating Cultural Alignment of Large Language Models
Badr AlKhamissi, Muhammad ElNokrashy, Mai AlKhamissi, Mona Diab
The intricate relationship between language and culture has long been a subject of exploration within the realm of linguistic anthropology. Large Language Models (LLMs), promoted as repositories of collective human knowledge, raise a pivotal question: do these models genuinely encapsulate the diverse knowledge adopted by different cultures? Our study reveals that these models demonstrate greater cultural alignment along two dimensions -- firstly, when prompted with the dominant language of a specific culture, and secondly, when pretrained with a refined mixture of languages employed by that culture. We quantify cultural alignment by simulating sociological surveys, comparing model responses to those of actual survey participants as references. Specifically, we replicate a survey conducted in various regions of Egypt and the United States through prompting LLMs with different pretraining data mixtures in both Arabic and English with the personas of the real respondents and the survey questions. Further analysis reveals that misalignment becomes more pronounced for underrepresented personas and for culturally sensitive topics, such as those probing social values. Finally, we introduce Anthropological Prompting, a novel method leveraging anthropological reasoning to enhance cultural alignment. Our study emphasizes the necessity for a more balanced multilingual pretraining dataset to better represent the diversity of human experience and the plurality of different cultures with many implications on the topic of cross-lingual transfer.
Read more7/9/2024
💬
0
Aligning language models with human preferences
Tomasz Korbak
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
Read more4/19/2024