On the Uniqueness of Solution for the Bellman Equation of LTL Objectives

0
📊
Sign in to get full access
Overview
- This paper explores the uniqueness of solutions to the Bellman equation for Markov Decision Processes (MDPs) with Linear Temporal Logic (LTL) objectives.
- The Bellman equation is a fundamental tool in reinforcement learning and dynamic programming, which is used to compute optimal policies for decision-making problems.
- The authors investigate the conditions under which the solution to the Bellman equation for MDPs with LTL objectives is unique.
Plain English Explanation
The paper focuses on a mathematical problem related to reinforcement learning and Markov Decision Processes (MDPs). Specifically, it looks at the Bellman equation, which is a key tool used to find the best decision-making strategy for an MDP.
The Bellman equation is a way to calculate the ideal actions to take in an MDP by considering both the immediate reward and the expected future rewards. This is important for reinforcement learning algorithms that aim to learn the optimal policy for an MDP.
In this paper, the authors examine what happens when the objectives for the MDP are defined using Linear Temporal Logic (LTL). They investigate whether the solution to the Bellman equation is always unique - in other words, is there only one best way to solve the decision-making problem, or could there be multiple equally good solutions?
The key finding is that under certain conditions, the solution to the Bellman equation for MDPs with LTL objectives is indeed unique. This is an important result, as it helps to ensure that reinforcement learning algorithms will converge to a single optimal policy when dealing with complex temporal logic objectives.
Technical Explanation
The paper studies the uniqueness of the solution to the Bellman equation for Markov Decision Processes (MDPs) with Linear Temporal Logic (LTL) objectives. The Bellman equation is a fundamental tool in reinforcement learning and dynamic programming, which is used to compute optimal policies for decision-making problems.
The authors consider labeled MDPs, where the states are associated with atomic propositions that describe the properties of the environment. They define the LTL objectives as a set of LTL formulas over these atomic propositions. The goal is to find a policy that maximizes the probability of satisfying the given LTL objectives.
The key technical result is that under certain conditions, the solution to the Bellman equation for MDPs with LTL objectives is unique. Specifically, the authors show that if the MDP is absorbing (i.e., every state can reach an absorbing state with probability 1) and the LTL objectives are safety and reachability objectives, then the solution to the Bellman equation is unique.
The authors also provide conditions for the uniqueness of the solution when the LTL objectives include more complex formulas, such as those involving temporal operators like "eventually" and "until". These results help to ensure that reinforcement learning algorithms will converge to a single optimal policy when dealing with complex temporal logic objectives.
Critical Analysis
The paper provides a rigorous mathematical analysis of the uniqueness of the solution to the Bellman equation for MDPs with LTL objectives. This is an important result, as it helps to establish the theoretical foundations for using reinforcement learning and dynamic programming techniques in problems with complex temporal logic specifications.
One potential limitation of the research is that it focuses on a specific class of LTL objectives, namely safety and reachability objectives. While these are important in many practical applications, there may be other types of LTL objectives that are also relevant and worth investigating.
Additionally, the authors' analysis assumes that the MDP is absorbing, which may not always be the case in real-world scenarios. It would be interesting to see if the uniqueness results can be extended to more general classes of MDPs.
Finally, the paper does not provide any experimental results or case studies demonstrating the practical implications of the theoretical findings. It would be valuable to see how the uniqueness of the Bellman equation solution can be leveraged in the design of reinforcement learning algorithms for problems with LTL objectives.
Conclusion
This paper makes an important contribution to the understanding of the Bellman equation for Markov Decision Processes with Linear Temporal Logic objectives. The key finding is that under certain conditions, the solution to the Bellman equation is unique, which has significant implications for the design of reinforcement learning algorithms that aim to optimize for complex temporal logic specifications.
The results in this paper lay the groundwork for further research in this area, such as exploring the uniqueness of solutions for a broader class of LTL objectives and investigating the practical applications of these theoretical insights. Overall, this work represents a valuable step forward in the field of reinforcement learning with temporal logic constraints.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
On the Uniqueness of Solution for the Bellman Equation of LTL Objectives
Zetong Xuan, Alper Kamil Bozkurt, Miroslav Pajic, Yu Wang
Surrogate rewards for linear temporal logic (LTL) objectives are commonly utilized in planning problems for LTL objectives. In a widely-adopted surrogate reward approach, two discount factors are used to ensure that the expected return approximates the satisfaction probability of the LTL objective. The expected return then can be estimated by methods using the Bellman updates such as reinforcement learning. However, the uniqueness of the solution to the Bellman equation with two discount factors has not been explicitly discussed. We demonstrate with an example that when one of the discount factors is set to one, as allowed in many previous works, the Bellman equation may have multiple solutions, leading to inaccurate evaluation of the expected return. We then propose a condition for the Bellman equation to have the expected return as the unique solution, requiring the solutions for states inside a rejecting bottom strongly connected component (BSCC) to be 0. We prove this condition is sufficient by showing that the solutions for the states with discounting can be separated from those for the states without discounting under this condition
Read more4/9/2024
0
Convergence Guarantee of Dynamic Programming for LTL Surrogate Reward
Zetong Xuan, Yu Wang
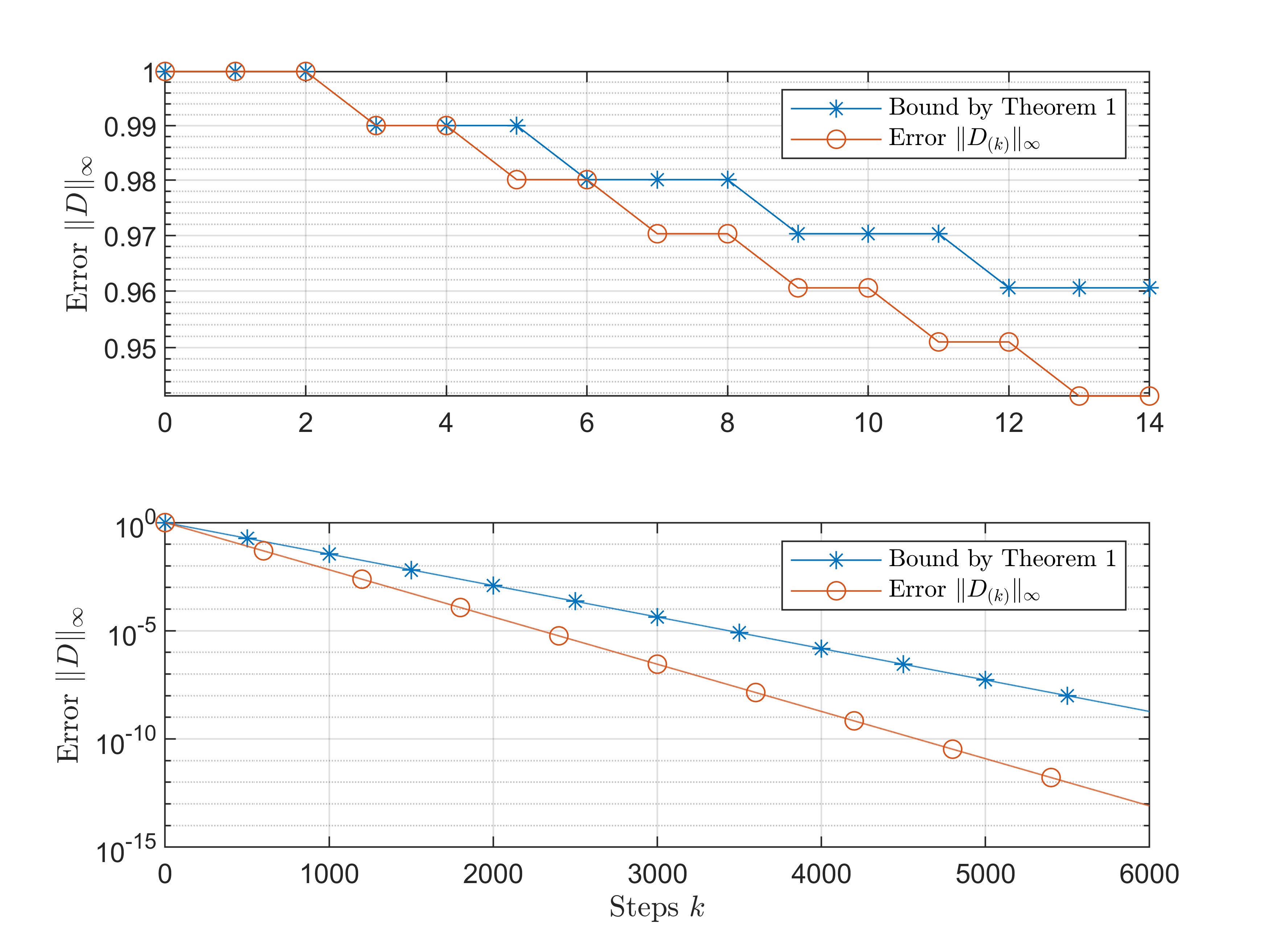
Linear Temporal Logic (LTL) is a formal way of specifying complex objectives for planning problems modeled as Markov Decision Processes (MDPs). The planning problem aims to find the optimal policy that maximizes the satisfaction probability of the LTL objective. One way to solve the planning problem is to use the surrogate reward with two discount factors and dynamic programming, which bypasses the graph analysis used in traditional model-checking. The surrogate reward is designed such that its value function represents the satisfaction probability. However, in some cases where one of the discount factors is set to $1$ for higher accuracy, the computation of the value function using dynamic programming is not guaranteed. This work shows that a multi-step contraction always exists during dynamic programming updates, guaranteeing that the approximate value function will converge exponentially to the true value function. Thus, the computation of satisfaction probability is guaranteed.
Read more8/13/2024
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
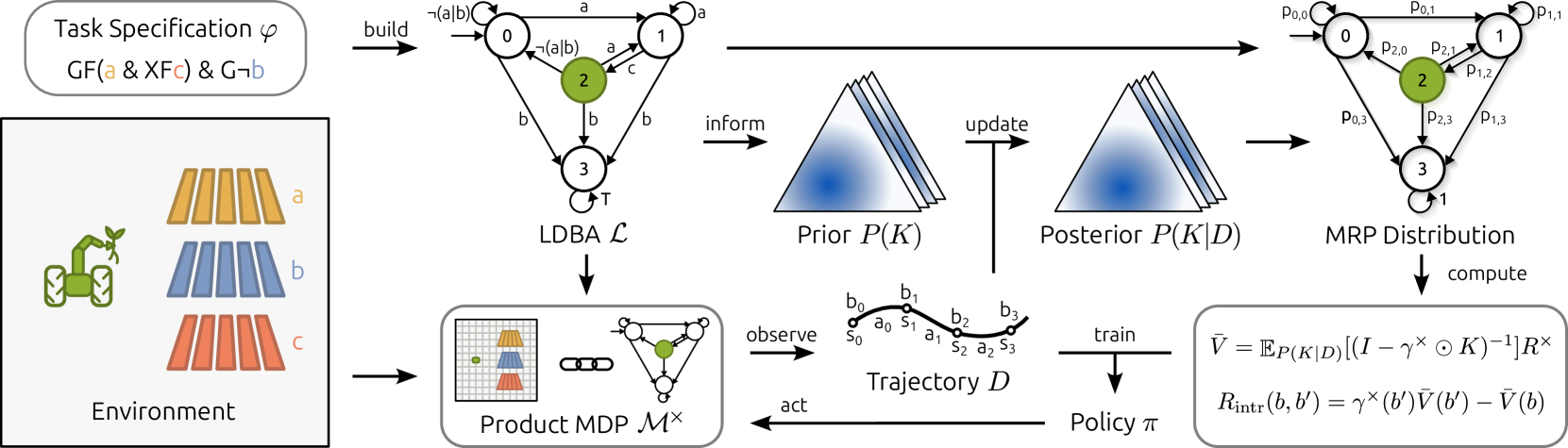
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024

0
On Bellman equations for continuous-time policy evaluation I: discretization and approximation
Wenlong Mou, Yuhua Zhu
We study the problem of computing the value function from a discretely-observed trajectory of a continuous-time diffusion process. We develop a new class of algorithms based on easily implementable numerical schemes that are compatible with discrete-time reinforcement learning (RL) with function approximation. We establish high-order numerical accuracy as well as the approximation error guarantees for the proposed approach. In contrast to discrete-time RL problems where the approximation factor depends on the effective horizon, we obtain a bounded approximation factor using the underlying elliptic structures, even if the effective horizon diverges to infinity.
Read more7/9/2024