Graph-enhanced Large Language Models in Asynchronous Plan Reasoning
2402.02805
0
0
💬
Abstract
Planning is a fundamental property of human intelligence. Reasoning about asynchronous plans is challenging since it requires sequential and parallel planning to optimize time costs. Can large language models (LLMs) succeed at this task? Here, we present the first large-scale study investigating this question. We find that a representative set of closed and open-source LLMs, including GPT-4 and LLaMA-2, behave poorly when not supplied with illustrations about the task-solving process in our benchmark AsyncHow. We propose a novel technique called Plan Like a Graph (PLaG) that combines graphs with natural language prompts and achieves state-of-the-art results. We show that although PLaG can boost model performance, LLMs still suffer from drastic degradation when task complexity increases, highlighting the limits of utilizing LLMs for simulating digital devices. We see our study as an exciting step towards using LLMs as efficient autonomous agents. Our code and data are available at https://github.com/fangru-lin/graph-llm-asynchow-plan.
Create account to get full access
Overview
- This paper explores the ability of large language models (LLMs) to reason about asynchronous plans, which is a challenging task that requires sequential and parallel planning to optimize time costs.
- The researchers conduct a large-scale study to investigate this question, using a benchmark called AsyncHow.
- They find that representative LLMs, including GPT-4 and LLaMA-2, perform poorly when not provided with illustrations about the task-solving process.
- The researchers propose a novel technique called Plan Like a Graph (PLaG) that combines graphs with natural language prompts, achieving state-of-the-art results.
- However, the study also highlights the limits of utilizing LLMs for simulating digital devices, as the models still suffer from drastic degradation as task complexity increases.
Plain English Explanation
Planning is a crucial aspect of human intelligence, allowing us to reason about and coordinate complex tasks over time. Asynchronous planning, where tasks can be executed in parallel or out of sequence, is particularly challenging as it requires carefully balancing time and resource constraints.
The researchers in this paper wanted to understand if large language models (LLMs) - powerful AI systems trained on vast amounts of text data - could succeed at this type of planning task. They created a benchmark called AsyncHow to test the LLMs' abilities.
When the LLMs were not provided with any additional information about how to solve the tasks, they performed quite poorly. The researchers then developed a new technique called Plan Like a Graph (PLaG), which combines natural language prompts with a graphical representation of the planning process. This approach was able to significantly boost the LLMs' performance.
However, even with this new technique, the LLMs still struggled as the planning tasks became more complex. This suggests that while LLMs can be useful for certain types of planning and reasoning, they have significant limitations when it comes to simulating the intricate, real-world dynamics of digital devices and systems.
The researchers see this work as an important step towards using LLMs as efficient autonomous agents that can reason about and coordinate complex, asynchronous tasks. But more research is needed to overcome the current limitations and further develop the planning capabilities of these models.
Technical Explanation
The paper presents a large-scale study investigating the ability of large language models (LLMs) to reason about asynchronous plans. Asynchronous planning is a challenging task that requires both sequential and parallel planning to optimize time costs, a fundamental property of human intelligence.
The researchers use a benchmark called AsyncHow to evaluate the performance of a representative set of closed and open-source LLMs, including GPT-4 and LLaMA-2. They find that these LLMs perform poorly when not supplied with illustrations about the task-solving process.
To address this, the researchers propose a novel technique called Plan Like a Graph (PLaG), which combines graphs with natural language prompts. PLaG achieves state-of-the-art results on the AsyncHow benchmark.
Despite the improvements, the study also reveals that LLMs still suffer from drastic degradation in performance as task complexity increases. This highlights the limits of utilizing LLMs for simulating digital devices and systems, as they struggle to effectively reason about the intricate, real-world dynamics involved.
The researchers see this work as an important step towards using LLMs as efficient autonomous agents that can reason about and coordinate complex, asynchronous tasks. The insights gained from this study could inform the development of more human-like reasoning frameworks and planning-aware techniques to enhance the planning capabilities of large language models.
Critical Analysis
The researchers provide a comprehensive and rigorous evaluation of LLMs' abilities in the challenging domain of asynchronous planning. By using a well-designed benchmark and a diverse set of models, the study offers valuable insights into the current limitations of these systems.
One key limitation highlighted in the paper is the LLMs' poor performance when not provided with visual aids or illustrations about the task-solving process. This suggests that the models struggle to internalize and reason about the complex, sequential and parallel nature of asynchronous planning tasks. While the Plan Like a Graph (PLaG) technique helps to address this, the researchers acknowledge that the models still suffer from significant performance degradation as task complexity increases.
This raises important questions about the fundamental capabilities of LLMs and their ability to effectively reason about structured, graph-like representations of planning and task coordination. Further research may be needed to explore alternative architectural approaches or training regimes that could better equip these models for such complex reasoning tasks.
Overall, the study provides a valuable contribution to the understanding of LLMs' strengths and limitations in the domain of planning and task coordination. The insights gained from this work could inform the development of more human-like reasoning frameworks and planning-aware techniques to enhance the capabilities of these powerful AI systems.
Conclusion
This paper presents a comprehensive study on the ability of large language models (LLMs) to reason about asynchronous plans, a challenging task that requires sequential and parallel planning. The researchers find that representative LLMs, including GPT-4 and LLaMA-2, perform poorly when not provided with illustrations about the task-solving process.
To address this, the researchers propose a novel technique called Plan Like a Graph (PLaG), which combines graphs with natural language prompts. While PLaG can boost model performance, the study also highlights the limits of utilizing LLMs for simulating digital devices, as the models still suffer from drastic degradation as task complexity increases.
This work represents an important step towards using LLMs as efficient autonomous agents that can reason about and coordinate complex, asynchronous tasks. The insights gained from this study could inform the development of more human-like reasoning frameworks and planning-aware techniques to enhance the planning capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
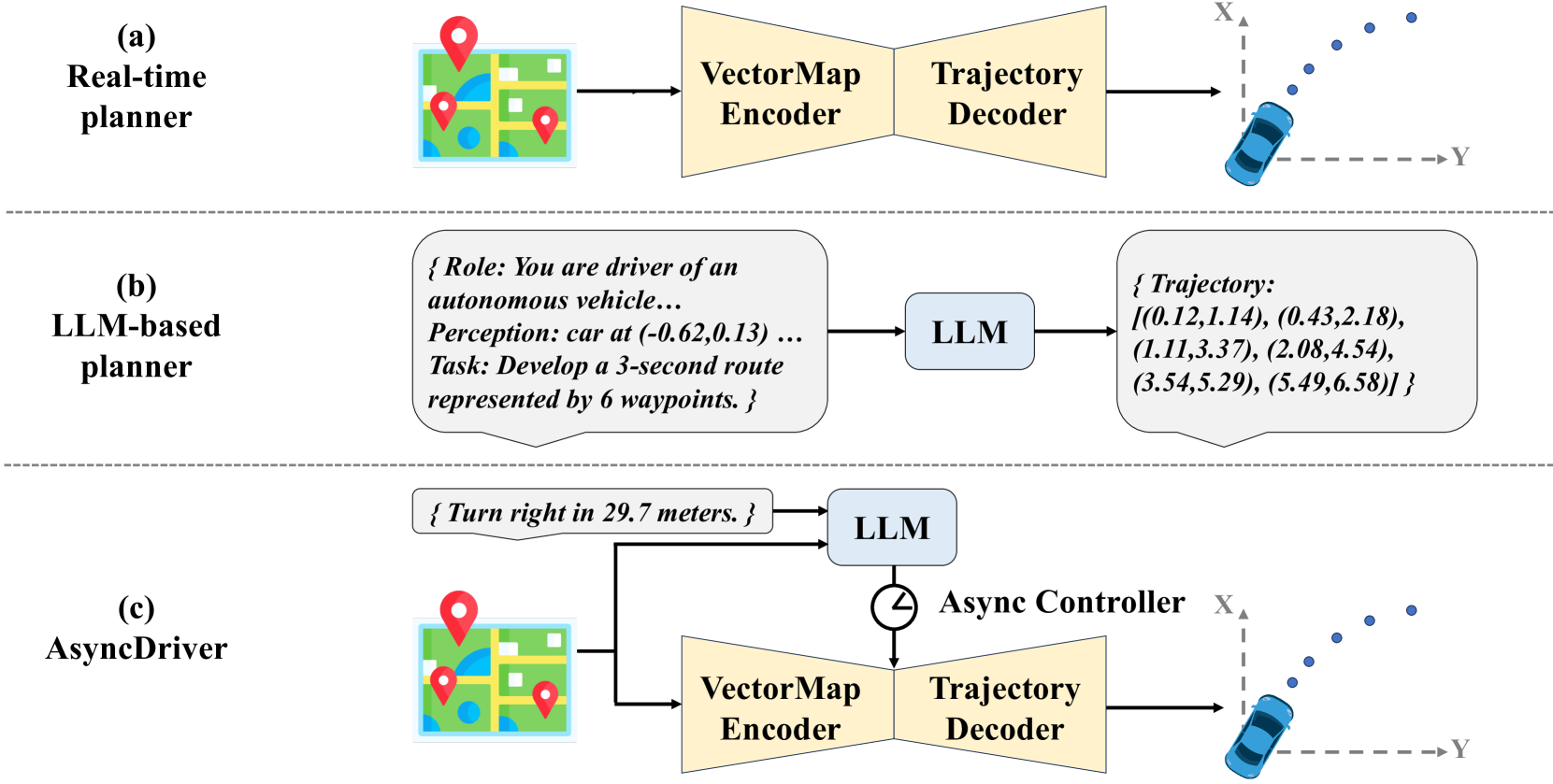
Asynchronous Large Language Model Enhanced Planner for Autonomous Driving
Yuan Chen, Zi-han Ding, Ziqin Wang, Yan Wang, Lijun Zhang, Si Liu
0
0
Despite real-time planners exhibiting remarkable performance in autonomous driving, the growing exploration of Large Language Models (LLMs) has opened avenues for enhancing the interpretability and controllability of motion planning. Nevertheless, LLM-based planners continue to encounter significant challenges, including elevated resource consumption and extended inference times, which pose substantial obstacles to practical deployment. In light of these challenges, we introduce AsyncDriver, a new asynchronous LLM-enhanced closed-loop framework designed to leverage scene-associated instruction features produced by LLM to guide real-time planners in making precise and controllable trajectory predictions. On one hand, our method highlights the prowess of LLMs in comprehending and reasoning with vectorized scene data and a series of routing instructions, demonstrating its effective assistance to real-time planners. On the other hand, the proposed framework decouples the inference processes of the LLM and real-time planners. By capitalizing on the asynchronous nature of their inference frequencies, our approach have successfully reduced the computational cost introduced by LLM, while maintaining comparable performance. Experiments show that our approach achieves superior closed-loop evaluation performance on nuPlan's challenging scenarios.
6/24/2024

Exploring and Benchmarking the Planning Capabilities of Large Language Models
Bernd Bohnet, Azade Nova, Aaron T Parisi, Kevin Swersky, Katayoon Goshvadi, Hanjun Dai, Dale Schuurmans, Noah Fiedel, Hanie Sedghi
0
0
We seek to elevate the planning capabilities of Large Language Models (LLMs)investigating four main directions. First, we construct a comprehensive benchmark suite encompassing both classical planning domains and natural language scenarios. This suite includes algorithms to generate instances with varying levels of difficulty, allowing for rigorous and systematic evaluation of LLM performance. Second, we investigate the use of in-context learning (ICL) to enhance LLM planning, exploring the direct relationship between increased context length and improved planning performance. Third, we demonstrate the positive impact of fine-tuning LLMs on optimal planning paths, as well as the effectiveness of incorporating model-driven search procedures. Finally, we investigate the performance of the proposed methods in out-of-distribution scenarios, assessing the ability to generalize to novel and unseen planning challenges.
6/21/2024
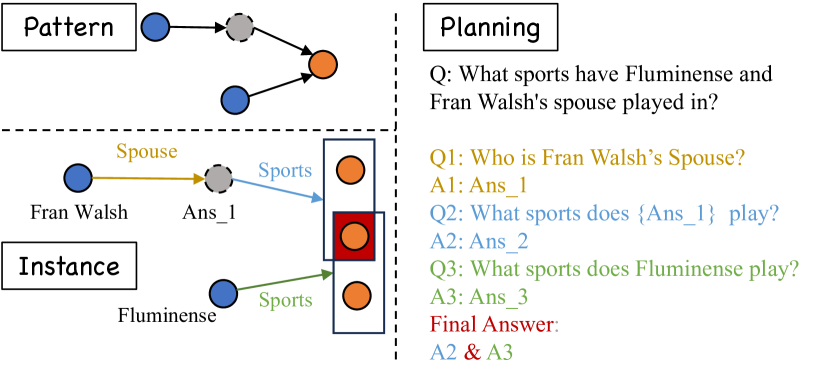
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
0
0
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
6/21/2024
💬
Large Language Models as Planning Domain Generators
James Oswald, Kavitha Srinivas, Harsha Kokel, Junkyu Lee, Michael Katz, Shirin Sohrabi
0
0
Developing domain models is one of the few remaining places that require manual human labor in AI planning. Thus, in order to make planning more accessible, it is desirable to automate the process of domain model generation. To this end, we investigate if large language models (LLMs) can be used to generate planning domain models from simple textual descriptions. Specifically, we introduce a framework for automated evaluation of LLM-generated domains by comparing the sets of plans for domain instances. Finally, we perform an empirical analysis of 7 large language models, including coding and chat models across 9 different planning domains, and under three classes of natural language domain descriptions. Our results indicate that LLMs, particularly those with high parameter counts, exhibit a moderate level of proficiency in generating correct planning domains from natural language descriptions. Our code is available at https://github.com/IBM/NL2PDDL.
5/14/2024