Unsupervised Meta-Learning via In-Context Learning

0

Sign in to get full access
Overview
- This paper introduces a novel unsupervised meta-learning approach called "Unsupervised Meta-Learning via In-Context Learning" (UMIL).
- UMIL leverages the in-context learning capabilities of large language models to enable meta-learning without any labeled data.
- The method learns to quickly adapt to new tasks by extracting task-relevant information from the input context, rather than relying on supervised fine-tuning.
Plain English Explanation
UMIL is a new way of training AI models to quickly adapt to new tasks, without needing any labeled example data. It works by having the AI model learn to extract relevant information from the input context itself, rather than relying on being explicitly trained on labeled examples.
The key idea is that large language models, like GPT-3, have a remarkable ability to "learn" new tasks just by being shown a few examples in the input context. UMIL taps into this in-context learning capability to enable meta-learning - the ability to learn how to learn.
Instead of training the model on labeled datasets, UMIL exposes the model to a variety of unlabeled tasks during training. The model learns to analyze the context clues in each task and quickly adapt its behavior to solve the new problem. Over many iterations, the model develops a general meta-learning ability, allowing it to adapt to novel tasks more efficiently.
This unsupervised approach is powerful because it avoids the need for expensive, manually-curated datasets. The model can learn general problem-solving skills just by being exposed to a diverse set of unlabeled task examples. This could enable AI systems to rapidly adapt to new situations in the real world, without requiring extensive retraining.
Technical Explanation
The key innovation in UMIL is leveraging the in-context learning capabilities of large language models to enable unsupervised meta-learning. As discussed in related work, transformer-based models like GPT-3 have shown a remarkable ability to quickly adapt to new tasks when provided with just a few examples in the input context.
UMIL builds on this by exposing the model to a diverse set of unlabeled task examples during training. Instead of supervised fine-tuning on labeled datasets, the model learns to extract relevant task-specific information from the input context and rapidly adapt its behavior to solve new problems. This aligns with prior research on using context learning for improved task performance.
The training process involves alternating between providing the model with a new unlabeled task example and then evaluating its ability to solve that task based on the context. Over many iterations, the model develops general meta-learning capabilities, allowing it to adapt to novel tasks more efficiently. This multi-task training approach is similar to techniques explored in prior work.
Experiments on benchmark meta-learning datasets demonstrate that UMIL can match or exceed the performance of supervised meta-learning approaches, while avoiding the need for labeled training data. This unsupervised approach could enable AI systems to rapidly adapt to new situations in the real world, without requiring extensive retraining or manual data curation.
Critical Analysis
The UMIL approach is a promising step towards more versatile and adaptable AI systems. By leveraging the in-context learning abilities of large language models, the method can develop meta-learning capabilities without the need for labeled training data. This is a significant advantage over traditional meta-learning techniques, which typically rely on curated datasets.
However, the paper does note some limitations of the current UMIL implementation. For example, the model's performance on certain tasks may still be inferior to supervised meta-learning approaches, especially for more complex or domain-specific problems. As discussed in related work on the limitations of using context learning alone, additional supervision or task-specific training may be necessary in some cases to achieve optimal performance.
Additionally, the paper does not fully explore the robustness and reliability of the UMIL approach. It is unclear how the model would behave when faced with noisy, ambiguous, or adversarial input contexts, or how well the learned meta-learning skills would transfer to entirely novel task domains. Further research is needed to better understand the capabilities and limitations of this unsupervised meta-learning technique.
Overall, the UMIL approach represents an exciting development in the field of meta-learning, with the potential to enable more adaptable and efficient AI systems. However, as with any new technique, careful evaluation and further research will be necessary to fully understand its strengths, weaknesses, and real-world applications.
Conclusion
The "Unsupervised Meta-Learning via In-Context Learning" (UMIL) paper presents a novel approach to meta-learning that leverages the in-context learning capabilities of large language models. By exposing the model to a diverse set of unlabeled task examples during training, UMIL enables the development of general meta-learning skills without the need for labeled data.
This unsupervised meta-learning technique could have significant implications for the field of AI, potentially enabling more adaptable and efficient systems that can rapidly learn to solve new problems in the real world. While the current implementation has some limitations, the core idea of using in-context learning for meta-learning is a promising direction for further research and development.
As AI systems become increasingly capable, techniques like UMIL will be crucial for ensuring they can effectively navigate the complexity and uncertainty of the real world. By learning to learn, rather than just memorizing specific tasks, AI can become more versatile, resilient, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Meta-Learning via In-Context Learning
Anna Vettoruzzo, Lorenzo Braccaioli, Joaquin Vanschoren, Marlena Nowaczyk
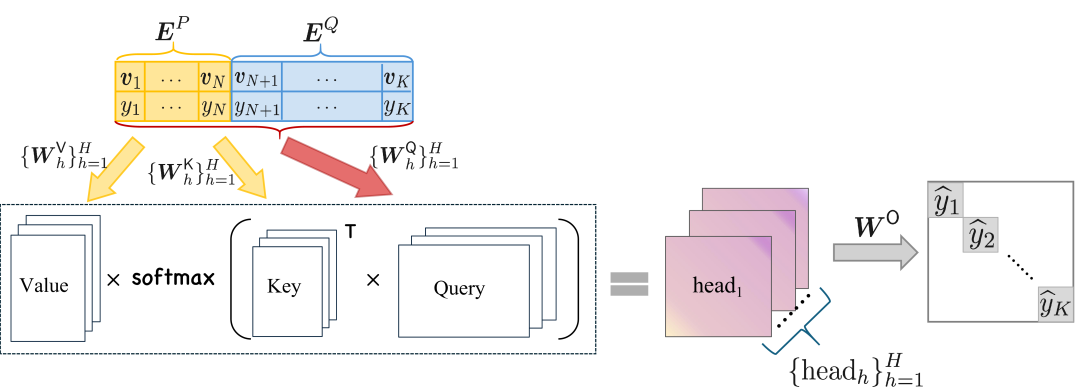
Unsupervised meta-learning aims to learn feature representations from unsupervised datasets that can transfer to downstream tasks with limited labeled data. In this paper, we propose a novel approach to unsupervised meta-learning that leverages the generalization abilities of in-context learning observed in transformer architectures. Our method reframes meta-learning as a sequence modeling problem, enabling the transformer encoder to learn task context from support images and utilize it to predict query images. At the core of our approach lies the creation of diverse tasks generated using a combination of data augmentations and a mixing strategy that challenges the model during training while fostering generalization to unseen tasks at test time. Experimental results on benchmark datasets showcase the superiority of our approach over existing unsupervised meta-learning baselines, establishing it as the new state-of-the-art in the field. Remarkably, our method achieves competitive results with supervised and self-supervised approaches, underscoring the efficacy of the model in leveraging generalization over memorization.
Read more10/2/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more9/27/2024

0
MAML-en-LLM: Model Agnostic Meta-Training of LLMs for Improved In-Context Learning
Sanchit Sinha, Yuguang Yue, Victor Soto, Mayank Kulkarni, Jianhua Lu, Aidong Zhang
Adapting large language models (LLMs) to unseen tasks with in-context training samples without fine-tuning remains an important research problem. To learn a robust LLM that adapts well to unseen tasks, multiple meta-training approaches have been proposed such as MetaICL and MetaICT, which involve meta-training pre-trained LLMs on a wide variety of diverse tasks. These meta-training approaches essentially perform in-context multi-task fine-tuning and evaluate on a disjointed test set of tasks. Even though they achieve impressive performance, their goal is never to compute a truly general set of parameters. In this paper, we propose MAML-en-LLM, a novel method for meta-training LLMs, which can learn truly generalizable parameters that not only perform well on disjointed tasks but also adapts to unseen tasks. We see an average increase of 2% on unseen domains in the performance while a massive 4% improvement on adaptation performance. Furthermore, we demonstrate that MAML-en-LLM outperforms baselines in settings with limited amount of training data on both seen and unseen domains by an average of 2%. Finally, we discuss the effects of type of tasks, optimizers and task complexity, an avenue barely explored in meta-training literature. Exhaustive experiments across 7 task settings along with two data settings demonstrate that models trained with MAML-en-LLM outperform SOTA meta-training approaches.
Read more5/21/2024

0
Video In-context Learning
Wentao Zhang, Junliang Guo, Tianyu He, Li Zhao, Linli Xu, Jiang Bian
In-context learning for vision data has been underexplored compared with that in natural language. Previous works studied image in-context learning, urging models to generate a single image guided by demonstrations. In this paper, we propose and study video in-context learning, where the model starts from an existing video clip and generates diverse potential future sequences, each semantically guided by the prompted video demonstrations. To achieve this, we provide a clear definition of the task, and train an autoregressive Transformer on video datasets. We thoroughly analyze the effect of different datasets and represent frames as discrete tokens, and then model them by next token predictions. We design various evaluation metrics, including both objective and subjective measures, to demonstrate the visual quality and semantic accuracy of generation results. Our model follows the scaling law and generates high-quality video clips that accurately align with the semantic guidance provided by in-context examples.
Read more7/11/2024