Untargeted Adversarial Attack on Knowledge Graph Embeddings

0

Sign in to get full access
Overview
- This paper explores the vulnerability of knowledge graph embeddings to untargeted adversarial attacks.
- Knowledge graph embeddings are a way of representing the entities and relationships in a knowledge graph as numerical vectors, which can be used for tasks like knowledge graph completion.
- The researchers designed an attack method that can generate adversarial perturbations to the input knowledge graph, causing the downstream knowledge graph embedding model to make incorrect predictions.
- This work highlights the potential security issues with relying on knowledge graph embeddings, and the need for more robust approaches to knowledge graph modeling.
Plain English Explanation
In this paper, the researchers looked at how easy it is to trick knowledge graph embedding models. Knowledge graph embeddings are a way of representing the information in a knowledge graph (a database of facts about the world) as numbers that a computer can understand. These numerical representations are very useful for tasks like predicting missing facts in the knowledge graph.
The researchers developed a technique that can make small, imperceptible changes to the knowledge graph, causing the embedding model to make mistakes. For example, they could add or remove a single fact from the knowledge graph, and the model would then fail to correctly predict other facts. This shows that these knowledge graph embedding models are quite fragile and vulnerable to adversarial attacks.
The significance of this work is that it highlights the need for more robust and secure approaches to knowledge graph modeling. If these models can be easily fooled, they may not be suitable for critical applications like network intrusion detection where reliability is paramount.
Technical Explanation
The researchers propose an untargeted adversarial attack method for perturbing knowledge graph embeddings. Their approach leverages gradient-based optimization to find small changes to the input knowledge graph that can significantly degrade the performance of downstream embedding models.
Specifically, they formulate the attack as an optimization problem, where the goal is to find perturbations that maximize the reconstruction error of the knowledge graph embeddings. They use a gradient-based approach to efficiently search the space of possible perturbations and identify the most impactful ones.
The researchers evaluate their attack method on several popular knowledge graph embedding models, including TransE, DistMult, and ComplEx, across multiple datasets. Their results demonstrate that the proposed attack can achieve high success rates in fooling the target models, even with very small perturbations to the input knowledge graph.
Furthermore, the researchers analyze the properties of the identified adversarial perturbations, showing that they tend to target specific types of relationships and entities that are more vulnerable to the attack. This provides valuable insights into the weaknesses of current knowledge graph embedding models and suggests directions for developing more robust approaches.
Critical Analysis
The key strength of this work is its comprehensive evaluation of the vulnerability of knowledge graph embeddings to adversarial attacks. The researchers demonstrate the feasibility of their attack method across multiple models and datasets, highlighting the widespread nature of this security issue.
However, one potential limitation of the study is the lack of investigation into defense mechanisms against such attacks. While the paper identifies the problem, it does not propose or evaluate any strategies for improving the robustness of knowledge graph embedding models. Addressing this gap would be an important next step for the research community.
Additionally, the paper does not explore the potential real-world implications of these attacks. It would be valuable to understand how these vulnerabilities could be exploited in practical applications, such as knowledge graph-powered recommendation systems or network intrusion detection. Investigating these use cases could help prioritize the development of more secure knowledge graph embedding techniques.
Overall, this work makes a significant contribution to the understanding of the robustness issues in knowledge graph embeddings. While more research is needed to address the limitations, the findings presented in this paper highlight the importance of developing adversarially robust models for knowledge graph-based applications.
Conclusion
This paper explores the vulnerability of knowledge graph embeddings to untargeted adversarial attacks. The researchers develop a gradient-based optimization technique that can generate small perturbations to the input knowledge graph, causing downstream embedding models to make incorrect predictions. Their results demonstrate the widespread fragility of these models, which raises important security and reliability concerns for knowledge graph-based applications.
The findings of this work underscore the need for more robust and secure approaches to knowledge graph modeling. As these embeddings become increasingly prevalent in real-world systems, it is crucial to address their susceptibility to adversarial attacks to ensure the reliability and trustworthiness of the resulting applications. Further research into defense mechanisms and the practical implications of these vulnerabilities will be valuable next steps for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Untargeted Adversarial Attack on Knowledge Graph Embeddings
Tianzhe Zhao, Jiaoyan Chen, Yanchi Ru, Qika Lin, Yuxia Geng, Jun Liu
Knowledge graph embedding (KGE) methods have achieved great success in handling various knowledge graph (KG) downstream tasks. However, KGE methods may learn biased representations on low-quality KGs that are prevalent in the real world. Some recent studies propose adversarial attacks to investigate the vulnerabilities of KGE methods, but their attackers are target-oriented with the KGE method and the target triples to predict are given in advance, which lacks practicability. In this work, we explore untargeted attacks with the aim of reducing the global performances of KGE methods over a set of unknown test triples and conducting systematic analyses on KGE robustness. Considering logic rules can effectively summarize the global structure of a KG, we develop rule-based attack strategies to enhance the attack efficiency. In particular,we consider adversarial deletion which learns rules, applying the rules to score triple importance and delete important triples, and adversarial addition which corrupts the learned rules and applies them for negative triples as perturbations. Extensive experiments on two datasets over three representative classes of KGE methods demonstrate the effectiveness of our proposed untargeted attacks in diminishing the link prediction results. And we also find that different KGE methods exhibit different robustness to untargeted attacks. For example, the robustness of methods engaged with graph neural networks and logic rules depends on the density of the graph. But rule-based methods like NCRL are easily affected by adversarial addition attacks to capture negative rules
Read more5/21/2024

0
Performance Evaluation of Knowledge Graph Embedding Approaches under Non-adversarial Attacks
Sourabh Kapoor, Arnab Sharma, Michael Roder, Caglar Demir, Axel-Cyrille Ngonga Ngomo
Knowledge Graph Embedding (KGE) transforms a discrete Knowledge Graph (KG) into a continuous vector space facilitating its use in various AI-driven applications like Semantic Search, Question Answering, or Recommenders. While KGE approaches are effective in these applications, most existing approaches assume that all information in the given KG is correct. This enables attackers to influence the output of these approaches, e.g., by perturbing the input. Consequently, the robustness of such KGE approaches has to be addressed. Recent work focused on adversarial attacks. However, non-adversarial attacks on all attack surfaces of these approaches have not been thoroughly examined. We close this gap by evaluating the impact of non-adversarial attacks on the performance of 5 state-of-the-art KGE algorithms on 5 datasets with respect to attacks on 3 attack surfaces-graph, parameter, and label perturbation. Our evaluation results suggest that label perturbation has a strong effect on the KGE performance, followed by parameter perturbation with a moderate and graph with a low effect.
Read more7/10/2024
0
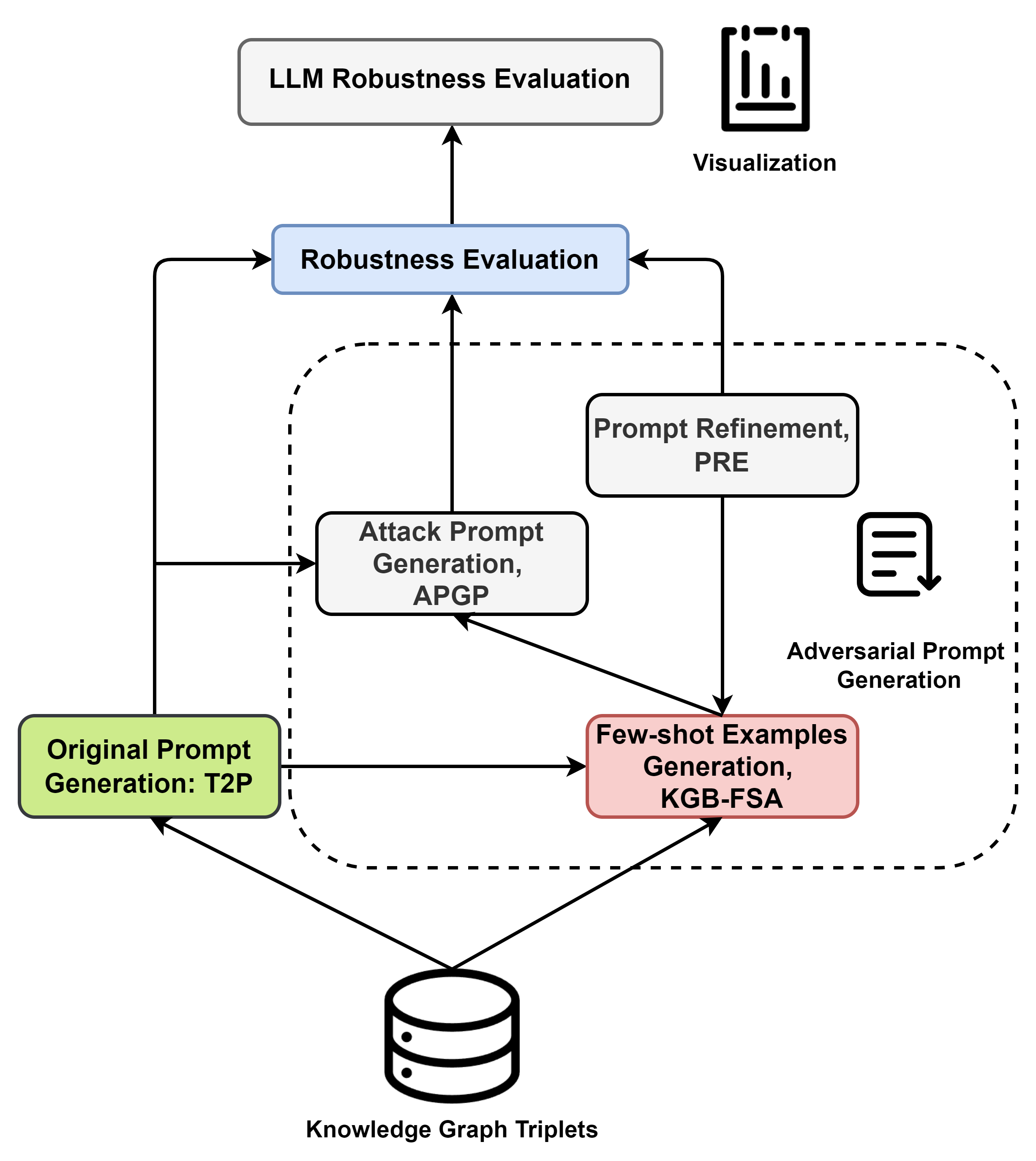
KGPA: Robustness Evaluation for Large Language Models via Cross-Domain Knowledge Graphs
Aihua Pei (Waseda University), Zehua Yang (Waseda University), Shunan Zhu (Waseda University), Ruoxi Cheng (Southeast University), Ju Jia (Southeast University), Lina Wang (Wuhan University)
Existing frameworks for assessing robustness of large language models (LLMs) overly depend on specific benchmarks, increasing costs and failing to evaluate performance of LLMs in professional domains due to dataset limitations. This paper proposes a framework that systematically evaluates the robustness of LLMs under adversarial attack scenarios by leveraging knowledge graphs (KGs). Our framework generates original prompts from the triplets of knowledge graphs and creates adversarial prompts by poisoning, assessing the robustness of LLMs through the results of these adversarial attacks. We systematically evaluate the effectiveness of this framework and its modules. Experiments show that adversarial robustness of the ChatGPT family ranks as GPT-4-turbo > GPT-4o > GPT-3.5-turbo, and the robustness of large language models is influenced by the professional domains in which they operate.
Read more6/18/2024
💬
0
BiasKG: Adversarial Knowledge Graphs to Induce Bias in Large Language Models
Chu Fei Luo, Ahmad Ghawanmeh, Xiaodan Zhu, Faiza Khan Khattak
Modern large language models (LLMs) have a significant amount of world knowledge, which enables strong performance in commonsense reasoning and knowledge-intensive tasks when harnessed properly. The language model can also learn social biases, which has a significant potential for societal harm. There have been many mitigation strategies proposed for LLM safety, but it is unclear how effective they are for eliminating social biases. In this work, we propose a new methodology for attacking language models with knowledge graph augmented generation. We refactor natural language stereotypes into a knowledge graph, and use adversarial attacking strategies to induce biased responses from several open- and closed-source language models. We find our method increases bias in all models, even those trained with safety guardrails. This demonstrates the need for further research in AI safety, and further work in this new adversarial space.
Read more5/9/2024