Detoxifying Large Language Models via Knowledge Editing
2403.14472
0
0
💬
Abstract
This paper investigates using knowledge editing techniques to detoxify Large Language Models (LLMs). We construct a benchmark, SafeEdit, which covers nine unsafe categories with various powerful attack prompts and equips comprehensive metrics for systematic evaluation. We conduct experiments with several knowledge editing approaches, indicating that knowledge editing has the potential to detoxify LLMs with a limited impact on general performance efficiently. Then, we propose a simple yet effective baseline, dubbed Detoxifying with Intraoperative Neural Monitoring (DINM), to diminish the toxicity of LLMs within a few tuning steps via only one instance. We further provide an in-depth analysis of the internal mechanism for various detoxifying approaches, demonstrating that previous methods like SFT and DPO may merely suppress the activations of toxic parameters, while DINM mitigates the toxicity of the toxic parameters to a certain extent, making permanent adjustments. We hope that these insights could shed light on future work of developing detoxifying approaches and the underlying knowledge mechanisms of LLMs. Code and benchmark are available at https://github.com/zjunlp/EasyEdit.
Create account to get full access
Overview
- This paper explores using knowledge editing techniques to reduce toxicity in Large Language Models (LLMs).
- The authors construct a benchmark called SafeEdit to systematically evaluate LLM detoxification efforts.
- They experiment with several knowledge editing approaches and propose a new method called Detoxifying with Intraoperative Neural Monitoring (DINM) that can efficiently detoxify LLMs with limited impact on overall performance.
- The paper provides an in-depth analysis of the internal mechanisms behind different detoxifying approaches.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at language tasks, but they can also generate toxic and harmful content. This paper looks at ways to "detoxify" these LLMs using knowledge editing techniques.
The researchers first built a benchmark called SafeEdit that tests an LLM's ability to avoid generating unsafe content across different categories, like hate speech or explicit violence. They used this benchmark to evaluate several approaches for reducing toxicity in LLMs.
One approach they tried is called Detoxifying with Intraoperative Neural Monitoring (DINM). The idea is to fine-tune the LLM on a small amount of data to reduce its tendency to generate toxic content, without significantly impacting its overall performance. DINM was able to make the LLM much less toxic, while still preserving its general language abilities.
The paper also provides a deeper look at how different detoxification methods work under the hood. For example, some previous approaches like SFT and DPO may just suppress the activations of toxic parameters in the LLM, while DINM actually changes the model to be less toxic in a more fundamental way.
Overall, this research shows promising ways to make large language models safer and more ethical, which could be crucial as these models become more widely used. The insights into the inner workings of detoxification could also help guide future work in this area.
Technical Explanation
The paper investigates using knowledge editing techniques to "detoxify" Large Language Models (LLMs). The authors construct a benchmark called SafeEdit that covers 9 unsafe content categories and uses powerful attack prompts to systematically evaluate an LLM's toxicity.
Through experiments with various knowledge editing approaches, the researchers find that these techniques have the potential to efficiently detoxify LLMs with limited impact on general performance. They then propose a new method called Detoxifying with Intraoperative Neural Monitoring (DINM), which can diminish toxicity within just a few fine-tuning steps using only a small amount of data.
The paper provides an in-depth analysis of the internal mechanisms behind different detoxifying approaches. It suggests that previous methods like SFT and DPO may only suppress the activations of toxic parameters, while DINM actually mitigates the toxicity of those parameters to a greater extent, making more permanent adjustments to the model.
Critical Analysis
The paper presents a compelling approach to addressing the toxicity issues often found in large language models. The use of the SafeEdit benchmark to systematically evaluate detoxification efforts is a strength, as it provides a rigorous and comprehensive way to measure progress.
However, the paper does not deeply explore the potential limitations or failure modes of the DINM method. For example, it's unclear how well DINM would scale to larger or more complex language models, or how it might perform on more nuanced or context-dependent forms of toxicity.
Additionally, while the analysis of the internal mechanisms behind different detoxification methods is insightful, the paper could benefit from a more critical examination of the broader implications and ethical considerations of this work. As language models become increasingly powerful and ubiquitous, the need to ensure their safety and societal impact must be carefully considered.
Further research could explore the generalizability of these findings, the long-term stability of the detoxified models, and the potential trade-offs or unintended consequences that may arise from deploying such techniques in the real world.
Conclusion
This paper presents a significant step forward in the quest to make large language models more ethical and safe. By developing the SafeEdit benchmark and proposing the DINM method, the authors have contributed valuable insights and tools for the field of LLM detoxification.
The ability to efficiently reduce toxicity in LLMs while preserving their overall capabilities is a crucial advancement, as these models become increasingly ubiquitous and influential. The in-depth analysis of the internal mechanisms behind different detoxification approaches also sheds light on the complex dynamics at play within LLMs, which could inform future work in this area.
Overall, this research represents an important contribution to the ongoing effort to develop more responsible and trustworthy artificial intelligence systems that can positively impact society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, Yun-Nung Chen
0
0
Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
6/4/2024
💬
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, Kangwei Liu, Yuansheng Ni, Guozhou Zheng, Huajun Chen
0
0
Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners from applying knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily applied to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video.
6/26/2024
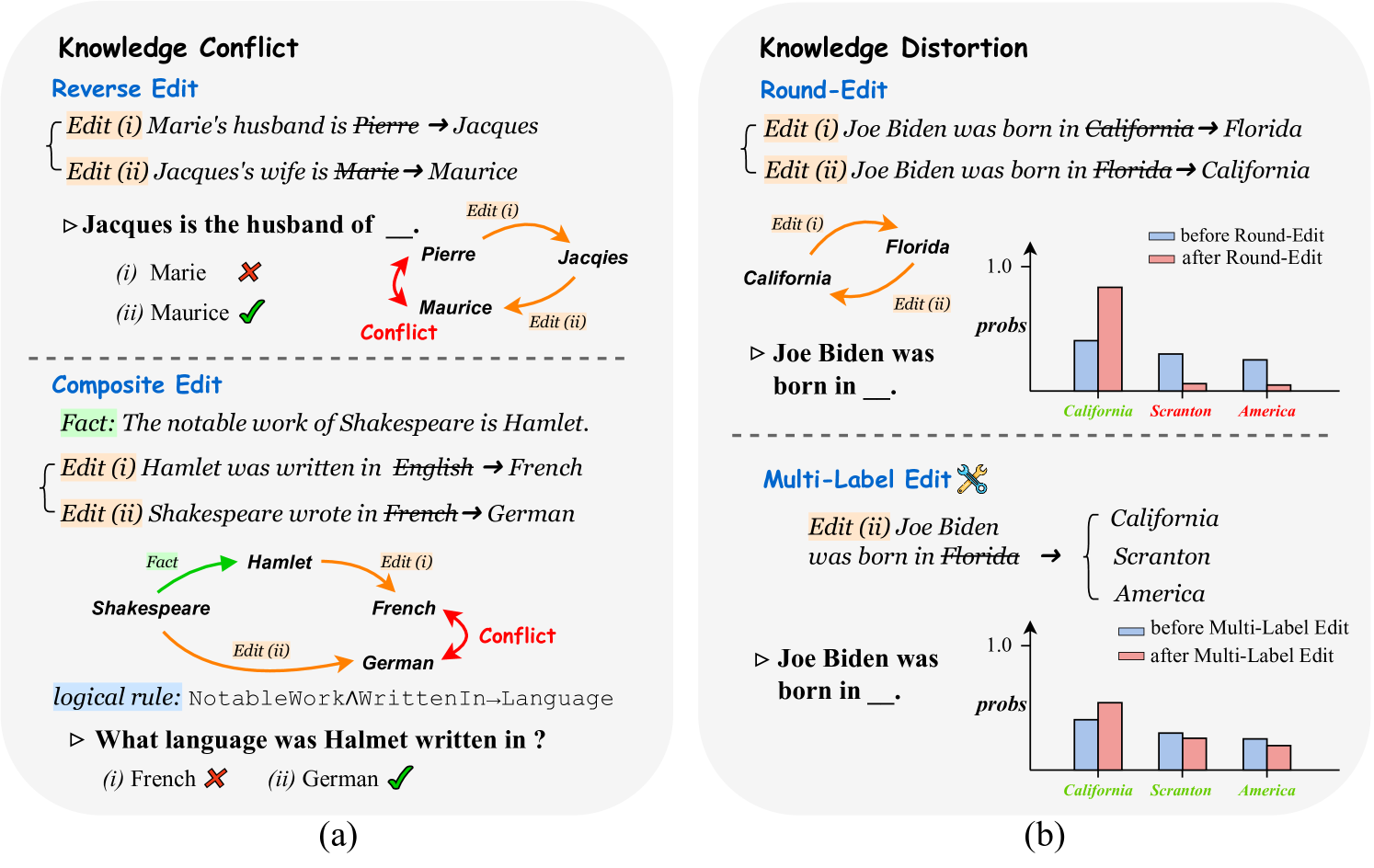
Unveiling the Pitfalls of Knowledge Editing for Large Language Models
Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, Huajun Chen
0
0
As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code and data are available at https://github.com/zjunlp/PitfallsKnowledgeEditing.
5/14/2024

Editing Factual Knowledge and Explanatory Ability of Medical Large Language Models
Derong Xu, Ziheng Zhang, Zhihong Zhu, Zhenxi Lin, Qidong Liu, Xian Wu, Tong Xu, Wanyu Wang, Yuyang Ye, Xiangyu Zhao, Yefeng Zheng, Enhong Chen
0
0
Model editing aims to precisely alter the behaviors of large language models (LLMs) in relation to specific knowledge, while leaving unrelated knowledge intact. This approach has proven effective in addressing issues of hallucination and outdated information in LLMs. However, the potential of using model editing to modify knowledge in the medical field remains largely unexplored, even though resolving hallucination is a pressing need in this area. Our observations indicate that current methods face significant challenges in dealing with specialized and complex knowledge in medical domain. Therefore, we propose MedLaSA, a novel Layer-wise Scalable Adapter strategy for medical model editing. MedLaSA harnesses the strengths of both adding extra parameters and locate-then-edit methods for medical model editing. We utilize causal tracing to identify the association of knowledge in neurons across different layers, and generate a corresponding scale set from the association value for each piece of knowledge. Subsequently, we incorporate scalable adapters into the dense layers of LLMs. These adapters are assigned scaling values based on the corresponding specific knowledge, which allows for the adjustment of the adapter's weight and rank. The more similar the content, the more consistent the scale between them. This ensures precise editing of semantically identical knowledge while avoiding impact on unrelated knowledge. To evaluate the editing impact on the behaviours of LLMs, we propose two model editing studies for medical domain: (1) editing factual knowledge for medical specialization and (2) editing the explanatory ability for complex knowledge. We build two novel medical benchmarking datasets and introduce a series of challenging and comprehensive metrics. Extensive experiments on medical LLMs demonstrate the editing efficiency of MedLaSA, without affecting unrelated knowledge.
6/5/2024