Using Large Language Models to Generate Authentic Multi-agent Knowledge Work Datasets

0
💬
Sign in to get full access
Overview
- This paper presents a method for generating authentic and relevant text using large language models.
- The authors explore techniques to enhance the quality and usefulness of text generated by these models.
- The research aims to improve the integration of large language models into real-world applications and workflows.
Plain English Explanation
The paper discusses ways to make text generated by powerful AI language models more realistic and useful. Large language models, like GPT-3, are able to produce human-like text on a wide range of topics. However, the text they generate can sometimes lack authenticity or be unsuitable for practical applications.
The researchers investigate techniques to enhance the quality of generated text. This includes methods to make the text more coherent and relevant to specific tasks or contexts. The goal is to make it easier to incorporate large language models into real-world applications, such as generating documentation or answering questions.
By improving the authenticity and usefulness of AI-generated text, the researchers aim to unlock the full potential of large language models and enable their broader adoption.
Technical Explanation
The paper explores techniques for generating authentic and relevant text using large language models. The authors focus on methods to enhance the quality and usefulness of the generated text, with the goal of better integrating these models into real-world applications.
The researchers investigate several approaches, including:
- Techniques to make the generated text more coherent and relevant to specific tasks or contexts
- Methods to enrich the generated text with additional information or context
- Strategies to improve the consistency and reliability of the generated text
The authors evaluate their techniques through a series of experiments, measuring the quality, relevance, and usefulness of the generated text. They also discuss the potential applications of their work, such as generating documentation or enhancing question-answering systems.
Critical Analysis
The paper presents a thoughtful approach to improving the quality and usefulness of text generated by large language models. The researchers acknowledge the limitations of current models and the need for further refinement to enable their widespread adoption in real-world applications.
One potential area for concern is the potential for these techniques to be used to generate misleading or inauthentic content. The authors discuss the importance of ensuring the reliability and trustworthiness of the generated text, but more research may be needed to address this challenge.
Additionally, the paper focuses on enhancing the quality of the generated text, but does not delve deeply into the ethical implications of these technologies. As large language models become more capable, it will be important to consider their social impact and ensure they are developed and deployed responsibly.
Conclusion
This paper presents a promising approach to improving the authenticity and usefulness of text generated by large language models. By developing techniques to enhance the quality, relevance, and reliability of the generated text, the researchers aim to enable the broader adoption of these powerful AI systems in real-world applications.
The work has the potential to unlock new use cases for large language models, such as generating high-quality documentation or enhancing question-answering capabilities. However, further research will be needed to address concerns around the potential misuse of these technologies and their broader societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Using Large Language Models to Generate Authentic Multi-agent Knowledge Work Datasets
Desiree Heim, Christian Jilek, Adrian Ulges, Andreas Dengel
Current publicly available knowledge work data collections lack diversity, extensive annotations, and contextual information about the users and their documents. These issues hinder objective and comparable data-driven evaluations and optimizations of knowledge work assistance systems. Due to the considerable resources needed to collect such data in real-life settings and the necessity of data censorship, collecting such a dataset appears nearly impossible. For this reason, we propose a configurable, multi-agent knowledge work dataset generator. This system simulates collaborative knowledge work among agents producing Large Language Model-generated documents and accompanying data traces. Additionally, the generator captures all background information, given in its configuration or created during the simulation process, in a knowledge graph. Finally, the resulting dataset can be utilized and shared without privacy or confidentiality concerns. This paper introduces our approach's design and vision and focuses on generating authentic knowledge work documents using Large Language Models. Our study involving human raters who assessed 53% of the generated and 74% of the real documents as realistic demonstrates the potential of our approach. Furthermore, we analyze the authenticity criteria mentioned in the participants' comments and elaborate on potential improvements for identified common issues.
Read more9/9/2024
0
Using Large Language Models to Enrich the Documentation of Datasets for Machine Learning
Joan Giner-Miguelez, Abel G'omez, Jordi Cabot
Recent regulatory initiatives like the European AI Act and relevant voices in the Machine Learning (ML) community stress the need to describe datasets along several key dimensions for trustworthy AI, such as the provenance processes and social concerns. However, this information is typically presented as unstructured text in accompanying documentation, hampering their automated analysis and processing. In this work, we explore using large language models (LLM) and a set of prompting strategies to automatically extract these dimensions from documents and enrich the dataset description with them. Our approach could aid data publishers and practitioners in creating machine-readable documentation to improve the discoverability of their datasets, assess their compliance with current AI regulations, and improve the overall quality of ML models trained on them. In this paper, we evaluate the approach on 12 scientific dataset papers published in two scientific journals (Nature's Scientific Data and Elsevier's Data in Brief) using two different LLMs (GPT3.5 and Flan-UL2). Results show good accuracy with our prompt extraction strategies. Concrete results vary depending on the dimensions, but overall, GPT3.5 shows slightly better accuracy (81,21%) than FLAN-UL2 (69,13%) although it is more prone to hallucinations. We have released an open-source tool implementing our approach and a replication package, including the experiments' code and results, in an open-source repository.
Read more5/27/2024

0
Knowledge Tagging with Large Language Model based Multi-Agent System
Hang Li, Tianlong Xu, Ethan Chang, Qingsong Wen
Knowledge tagging for questions is vital in modern intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been performed by pedagogical experts, as the task demands not only a deep semantic understanding of question stems and knowledge definitions but also a strong ability to link problem-solving logic with relevant knowledge concepts. With the advent of advanced natural language processing (NLP) algorithms, such as pre-trained language models and large language models (LLMs), pioneering studies have explored automating the knowledge tagging process using various machine learning models. In this paper, we investigate the use of a multi-agent system to address the limitations of previous algorithms, particularly in handling complex cases involving intricate knowledge definitions and strict numerical constraints. By demonstrating its superior performance on the publicly available math question knowledge tagging dataset, MathKnowCT, we highlight the significant potential of an LLM-based multi-agent system in overcoming the challenges that previous methods have encountered. Finally, through an in-depth discussion of the implications of automating knowledge tagging, we underscore the promising results of deploying LLM-based algorithms in educational contexts.
Read more9/16/2024
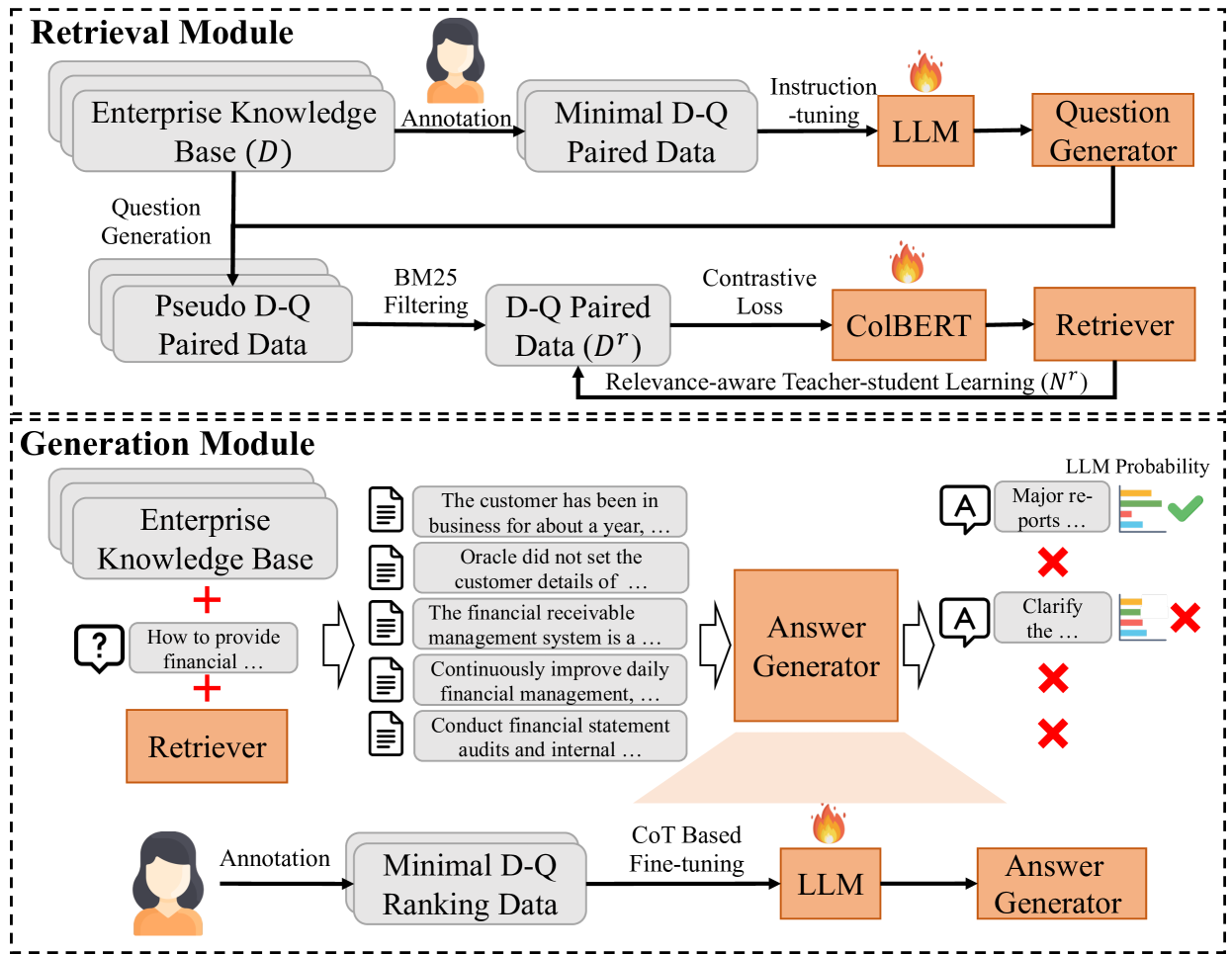
0
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Read more4/23/2024