Using LLM for Real-Time Transcription and Summarization of Doctor-Patient Interactions into ePuskesmas in Indonesia

0
Sign in to get full access
Overview
- This research paper explores the use of large language models (LLMs) for real-time transcription and summarization of doctor-patient interactions in Indonesia.
- The goal is to automatically generate electronic medical records (ePuskesmas) from these interactions to improve healthcare documentation and efficiency.
- The research was partially supported by the Ikatan Ilmuwan Indonesia Internasional (I-4) Research Grant.
Plain English Explanation
The researchers wanted to find a way to automatically create electronic medical records from conversations between doctors and patients in Indonesia. They used a type of artificial intelligence called a large language model (LLM) to do this.
LLMs are very advanced language models that can understand and generate human-like text. In this case, the researchers used an LLM to transcribe the audio of the doctor-patient conversations in real-time and then summarize the key points. This allowed them to efficiently create electronic medical records, called ePuskesmas, directly from the interactions.
The researchers believe this approach could improve healthcare documentation and efficiency in Indonesia. The project was supported by a research grant from the Ikatan Ilmuwan Indonesia Internasional (I-4).
Technical Explanation
The researchers used a fine-tuned BERT-based LLM for real-time transcription of the doctor-patient audio recordings. They then utilized an abstractive summarization model to generate concise summaries of the interactions, which were used to populate the ePuskesmas system.
The LLM transcription and summarization models were trained on a large dataset of Indonesian medical conversations. The researchers evaluated the performance of the system on metrics such as transcription accuracy, summarization quality, and ePuskesmas completeness.
Critical Analysis
The paper does not address potential privacy and data security concerns around the use of sensitive medical data. Additionally, the generalization of the models to diverse medical settings and patient populations in Indonesia is not thoroughly explored.
Further research is needed to fine-tune the LLM-based systems for optimal performance in real-world clinical deployments and to address any ethical or regulatory considerations.
Conclusion
This research demonstrates the potential of leveraging large language models for automating the creation of electronic medical records from doctor-patient interactions in Indonesia. The ability to transcribe and summarize these conversations in real-time could significantly improve healthcare documentation and efficiency, though further research is needed to address potential challenges and ensure the responsible deployment of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Using LLM for Real-Time Transcription and Summarization of Doctor-Patient Interactions into ePuskesmas in Indonesia
Azmul Asmar Irfan, Nur Ahmad Khatim, Mansur M. Arief
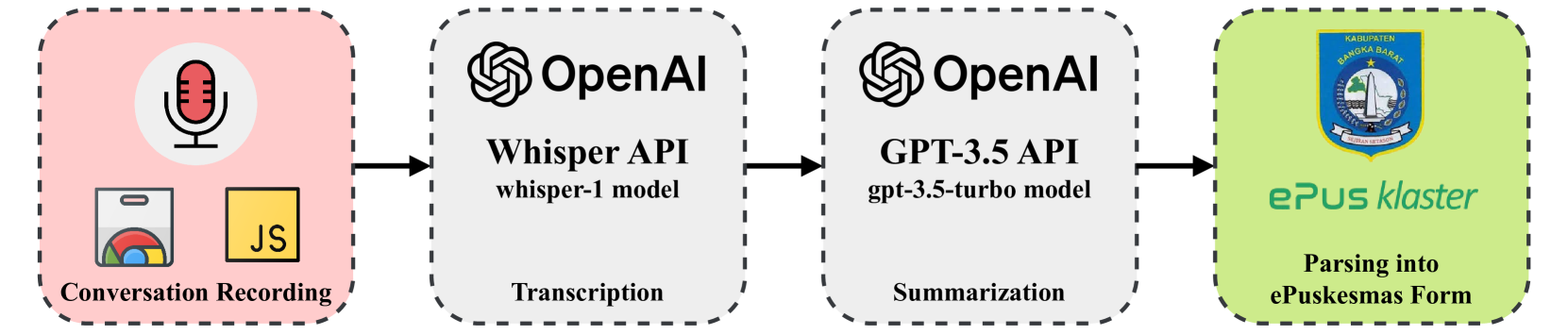
One of the key issues contributing to inefficiency in Puskesmas is the time-consuming nature of doctor-patient interactions. Doctors need to conduct thorough consultations, which include diagnosing the patient's condition, providing treatment advice, and transcribing detailed notes into medical records. In regions with diverse linguistic backgrounds, doctors often have to ask clarifying questions, further prolonging the process. While diagnosing is essential, transcription and summarization can often be automated using AI to improve time efficiency and help doctors enhance care quality and enable early diagnosis and intervention. This paper proposes a solution using a localized large language model (LLM) to transcribe, translate, and summarize doctor-patient conversations. We utilize the Whisper model for transcription and GPT-3 to summarize them into the ePuskemas medical records format. This system is implemented as an add-on to an existing web browser extension, allowing doctors to fill out patient forms while talking. By leveraging this solution for real-time transcription, translation, and summarization, doctors can improve the turnaround time for patient care while enhancing the quality of records, which become more detailed and insightful for future visits. This innovation addresses challenges like overcrowded facilities and the administrative burden on healthcare providers in Indonesia. We believe this solution will help doctors save time, provide better care, and produce more accurate medical records, representing a significant step toward modernizing healthcare and ensuring patients receive timely, high-quality care, even in resource-constrained settings.
Read more9/26/2024

0
Real-time Speech Summarization for Medical Conversations
Khai Le-Duc, Khai-Nguyen Nguyen, Long Vo-Dang, Truong-Son Hy
In doctor-patient conversations, identifying medically relevant information is crucial, posing the need for conversation summarization. In this work, we propose the first deployable real-time speech summarization system for real-world applications in industry, which generates a local summary after every N speech utterances within a conversation and a global summary after the end of a conversation. Our system could enhance user experience from a business standpoint, while also reducing computational costs from a technical perspective. Secondly, we present VietMed-Sum which, to our knowledge, is the first speech summarization dataset for medical conversations. Thirdly, we are the first to utilize LLM and human annotators collaboratively to create gold standard and synthetic summaries for medical conversation summarization. Finally, we present baseline results of state-of-the-art models on VietMed-Sum. All code, data (English-translated and Vietnamese) and models are available online: https://github.com/leduckhai/MultiMed
Read more6/26/2024
💬
0
Efficient Fine-Tuning of Large Language Models for Automated Medical Documentation
Hui Yi Leong, Yi Fan Gao, Ji Shuai, Uktu Pamuksuz
Scientific research indicates that for every hour spent in direct patient care, physicians spend nearly two additional hours on administrative tasks, particularly on electronic health records (EHRs) and desk work. This excessive administrative burden not only reduces the time available for patient care but also contributes to physician burnout and inefficiencies in healthcare delivery. To address these challenges, this study introduces MediGen, a fine-tuned large language model (LLM) designed to automate the generation of medical reports from medical dialogues. By leveraging state-of-the-art methodologies for fine-tuning open-source pretrained models, including LLaMA3-8B, MediGen achieves high accuracy in transcribing and summarizing clinical interactions. The fine-tuned LLaMA3-8B model demonstrated promising results, achieving a ROUGE score of 58% and a BERTScore-F1 of 72%, indicating its effectiveness in generating accurate and clinically relevant medical reports. These findings suggest that MediGen has the potential to significantly reduce the administrative workload on physicians, improving both healthcare efficiency and physician well-being.
Read more9/17/2024
💬
0
Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, Nidhi Rohatgi, Poonam Hosamani, William Collins, Neera Ahuja, Curtis P. Langlotz, Jason Hom, Sergios Gatidis, John Pauly, Akshay S. Chaudhari
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
Read more4/15/2024