ViFu: Multiple 360$^circ$ Objects Reconstruction with Clean Background via Visible Part Fusion

0

Sign in to get full access
Overview
- This paper presents a method called ViFu for reconstructing multiple 360-degree objects with a clean background using visible part fusion.
- The key idea is to leverage the visible parts of objects from multiple images to create a complete 3D reconstruction, while removing the background.
- The authors demonstrate the effectiveness of ViFu on various datasets, showing improved reconstruction quality and background removal compared to previous methods.
Plain English Explanation
The research paper describes a new technique called ViFu for creating 3D models of multiple objects from 360-degree images. The main challenge is that the objects are often partially obscured, so the full 3D shape is not visible in any single image. ViFu solves this by combining the visible parts of the object from multiple images to form a complete 3D reconstruction. At the same time, it is able to remove the background, leaving just the object itself.
This is useful for a variety of applications, such as DreamScene360: Unconstrained Text-to-3D Scene Generation where generating high-quality 3D models of objects is important. The ability to remove the background automatically also makes the process more efficient.
The key innovation of ViFu is the way it fuses the visible parts from different images to construct the final 3D model. This allows it to handle cases where the object is partially occluded or hidden in some of the input images. The authors show that ViFu outperforms previous methods in terms of both reconstruction quality and background removal.
Technical Explanation
The ViFu method takes as input a set of 360-degree images of multiple objects against a background. The goal is to reconstruct the 3D shape of each object while removing the background.
ViFu works by first using a deep learning model to segment each image into the object and background regions. It then leverages the visible parts of the object from multiple views to reconstruct the 3D shape. Specifically, ViFu uses a fusion module that combines the 3D features extracted from each image to form a complete 3D model of the object.
The key innovation is that ViFu can handle cases where the object is partially occluded or hidden in some of the input images. By fusing the visible parts, it is able to reconstruct a high-quality 3D model even when the full object is not visible in any single view.
To remove the background, ViFu employs a background reconstruction module that estimates the 3D geometry of the background based on the observed images. This allows it to separate the object from the background in the final 3D reconstruction.
The authors evaluate ViFu on several datasets, including You Only Scan Once: Dynamic Scene Reconstruction and Incremental Joint Learning of Depth, Pose & Implicit Scene. The results show that ViFu achieves state-of-the-art performance in terms of both reconstruction quality and background removal.
Critical Analysis
The ViFu method presents an interesting approach to 3D reconstruction of multiple objects with clean backgrounds. The key strengths are its ability to handle partial occlusion and its effective background removal.
However, the paper does not address some potential limitations. For example, it is unclear how well ViFu would perform on highly complex or deformable objects, or in cases where the background is more cluttered. Additionally, the computational complexity and runtime of the method are not discussed in detail.
Further research could also explore the integration of ViFu with other 3D reconstruction techniques, such as PlatoneRF: 3D Reconstruction of Plato's Cave via Single Viewpoint, to potentially achieve even better results.
Overall, ViFu represents an interesting contribution to the field of 3D reconstruction, with promising applications in areas like WALT3D: Generating Realistic Training Data from Time. However, as with any research, there are opportunities for further refinement and exploration.
Conclusion
The ViFu method presented in this paper offers a novel approach to 3D reconstruction of multiple objects with clean backgrounds. By fusing the visible parts of objects from multiple 360-degree images, ViFu is able to create high-quality 3D models while effectively removing the background.
This technique has significant potential for applications in areas such as virtual reality, augmented reality, and 3D content creation. The ability to automatically generate 3D models of objects with clean backgrounds could streamline many workflows and enable new types of immersive experiences.
While the paper highlights the strengths of ViFu, there are also opportunities for further research to address potential limitations and integrate the method with other 3D reconstruction techniques. Overall, this work represents an important step forward in the field of 3D reconstruction and object modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ViFu: Multiple 360$^circ$ Objects Reconstruction with Clean Background via Visible Part Fusion
Tianhan Xu, Takuya Ikeda, Koichi Nishiwaki
In this paper, we propose a method to segment and recover a static, clean background and multiple 360$^circ$ objects from observations of scenes at different timestamps. Recent works have used neural radiance fields to model 3D scenes and improved the quality of novel view synthesis, while few studies have focused on modeling the invisible or occluded parts of the training images. These under-reconstruction parts constrain both scene editing and rendering view selection, thereby limiting their utility for synthetic data generation for downstream tasks. Our basic idea is that, by observing the same set of objects in various arrangement, so that parts that are invisible in one scene may become visible in others. By fusing the visible parts from each scene, occlusion-free rendering of both background and foreground objects can be achieved. We decompose the multi-scene fusion task into two main components: (1) objects/background segmentation and alignment, where we leverage point cloud-based methods tailored to our novel problem formulation; (2) radiance fields fusion, where we introduce visibility field to quantify the visible information of radiance fields, and propose visibility-aware rendering for the fusion of series of scenes, ultimately obtaining clean background and 360$^circ$ object rendering. Comprehensive experiments were conducted on synthetic and real datasets, and the results demonstrate the effectiveness of our method.
Read more4/16/2024
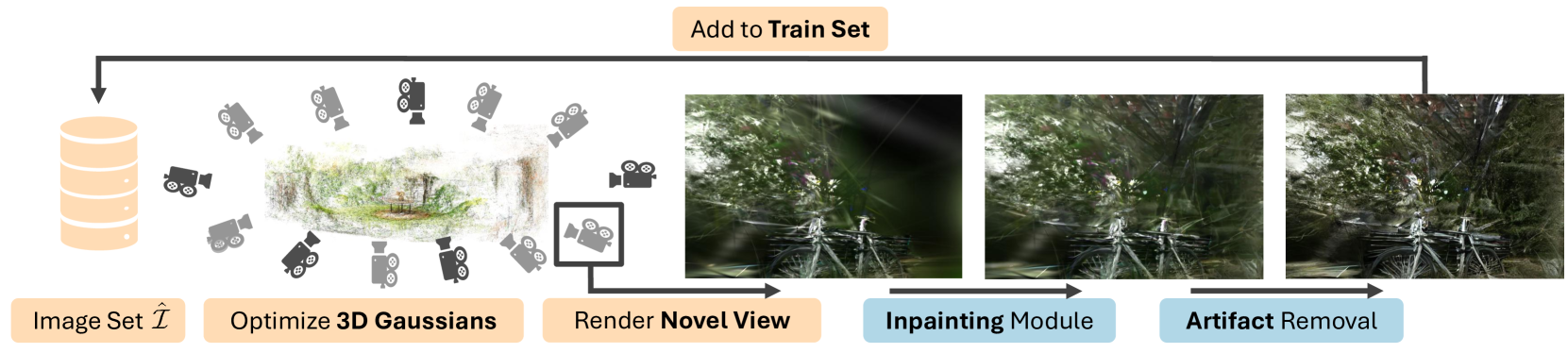
0
Sp2360: Sparse-view 360 Scene Reconstruction using Cascaded 2D Diffusion Priors
Soumava Paul, Christopher Wewer, Bernt Schiele, Jan Eric Lenssen
We aim to tackle sparse-view reconstruction of a 360 3D scene using priors from latent diffusion models (LDM). The sparse-view setting is ill-posed and underconstrained, especially for scenes where the camera rotates 360 degrees around a point, as no visual information is available beyond some frontal views focused on the central object(s) of interest. In this work, we show that pretrained 2D diffusion models can strongly improve the reconstruction of a scene with low-cost fine-tuning. Specifically, we present SparseSplat360 (Sp2360), a method that employs a cascade of in-painting and artifact removal models to fill in missing details and clean novel views. Due to superior training and rendering speeds, we use an explicit scene representation in the form of 3D Gaussians over NeRF-based implicit representations. We propose an iterative update strategy to fuse generated pseudo novel views with existing 3D Gaussians fitted to the initial sparse inputs. As a result, we obtain a multi-view consistent scene representation with details coherent with the observed inputs. Our evaluation on the challenging Mip-NeRF360 dataset shows that our proposed 2D to 3D distillation algorithm considerably improves the performance of a regularized version of 3DGS adapted to a sparse-view setting and outperforms existing sparse-view reconstruction methods in 360 scene reconstruction. Qualitatively, our method generates entire 360 scenes from as few as 9 input views, with a high degree of foreground and background detail.
Read more6/4/2024

0
Simultaneous Map and Object Reconstruction
Nathaniel Chodosh, Anish Madan, Deva Ramanan, Simon Lucey
In this paper, we present a method for dynamic surface reconstruction of large-scale urban scenes from LiDAR. Depth-based reconstructions tend to focus on small-scale objects or large-scale SLAM reconstructions that treat moving objects as outliers. We take a holistic perspective and optimize a compositional model of a dynamic scene that decomposes the world into rigidly moving objects and the background. To achieve this, we take inspiration from recent novel view synthesis methods and pose the reconstruction problem as a global optimization, minimizing the distance between our predicted surface and the input LiDAR scans. We show how this global optimization can be decomposed into registration and surface reconstruction steps, which are handled well by off-the-shelf methods without any re-training. By careful modeling of continuous-time motion, our reconstructions can compensate for the rolling shutter effects of rotating LiDAR sensors. This allows for the first system (to our knowledge) that properly motion compensates LiDAR scans for rigidly-moving objects, complementing widely-used techniques for motion compensation of static scenes. Beyond pursuing dynamic reconstruction as a goal in and of itself, we also show that such a system can be used to auto-label partially annotated sequences and produce ground truth annotation for hard-to-label problems such as depth completion and scene flow.
Read more6/21/2024

0
Part123: Part-aware 3D Reconstruction from a Single-view Image
Anran Liu, Cheng Lin, Yuan Liu, Xiaoxiao Long, Zhiyang Dou, Hao-Xiang Guo, Ping Luo, Wenping Wang
Recently, the emergence of diffusion models has opened up new opportunities for single-view reconstruction. However, all the existing methods represent the target object as a closed mesh devoid of any structural information, thus neglecting the part-based structure, which is crucial for many downstream applications, of the reconstructed shape. Moreover, the generated meshes usually suffer from large noises, unsmooth surfaces, and blurry textures, making it challenging to obtain satisfactory part segments using 3D segmentation techniques. In this paper, we present Part123, a novel framework for part-aware 3D reconstruction from a single-view image. We first use diffusion models to generate multiview-consistent images from a given image, and then leverage Segment Anything Model (SAM), which demonstrates powerful generalization ability on arbitrary objects, to generate multiview segmentation masks. To effectively incorporate 2D part-based information into 3D reconstruction and handle inconsistency, we introduce contrastive learning into a neural rendering framework to learn a part-aware feature space based on the multiview segmentation masks. A clustering-based algorithm is also developed to automatically derive 3D part segmentation results from the reconstructed models. Experiments show that our method can generate 3D models with high-quality segmented parts on various objects. Compared to existing unstructured reconstruction methods, the part-aware 3D models from our method benefit some important applications, including feature-preserving reconstruction, primitive fitting, and 3D shape editing.
Read more5/28/2024