Visual-Semantic Decomposition and Partial Alignment for Document-based Zero-Shot Learning

0

Sign in to get full access
Overview
- A new approach for document-based zero-shot learning that uses visual-semantic decomposition and partial semantic alignment.
- Focuses on leveraging the rich semantic information in documents to enable zero-shot recognition of visual concepts.
- Proposes a framework to learn visual-semantic decomposition and partial semantic alignment in an end-to-end manner.
Plain English Explanation
In the field of computer vision, zero-shot learning is a technique that allows models to recognize objects or concepts they haven't seen during training. This paper introduces a new approach for zero-shot learning that specifically targets document-based scenarios.
The key idea is to leverage the rich semantic information contained in documents, such as textual descriptions, to help the model learn to recognize visual concepts it hasn't encountered before. The researchers propose a framework that can decompose the visual and semantic information in a document and then partially align the two components, allowing the model to learn effective associations between visual and textual data.
This approach is particularly useful for scenarios where a large amount of textual information about visual concepts is available, but not enough labeled visual data to train a traditional computer vision model. By harnessing the semantic knowledge in documents, the model can learn to recognize these new visual concepts in a zero-shot manner, without requiring any additional labeled visual data.
Technical Explanation
The proposed framework consists of two key components: visual-semantic decomposition and partial semantic alignment.
Visual-Semantic Decomposition: The model first learns to decompose the input document into its visual and semantic components. This is achieved by training separate encoders for the visual and textual information in the document, allowing the model to extract these two distinct representations.
Partial Semantic Alignment: The model then learns to partially align the visual and semantic representations, focusing on the relevant semantic concepts that are most informative for the visual recognition task. This partial alignment helps the model learn effective associations between the visual and textual data, without being overwhelmed by irrelevant semantic information.
The researchers train this framework in an end-to-end manner, using a combination of supervised and unsupervised losses to jointly optimize the visual-semantic decomposition and partial alignment components. The resulting model is able to effectively leverage the rich semantic knowledge in documents to recognize new visual concepts in a zero-shot manner.
Critical Analysis
The paper presents a promising approach for document-based zero-shot learning, but there are a few potential limitations and areas for further research:
-
Generalization to Other Domains: The experiments in the paper focus on a specific dataset of visual concepts and their textual descriptions. It would be important to evaluate the framework's performance on a wider range of document-based zero-shot learning tasks and datasets to assess its broader applicability.
-
Partial Alignment Effectiveness: The partial semantic alignment component is a key contribution of the paper, but its effectiveness could be further analyzed. It would be interesting to see how the model's performance compares to approaches that use full semantic alignment or other alignment strategies.
-
Interpretability and Explainability: The paper does not provide much insight into how the model is actually using the semantic information from the documents to enable zero-shot recognition. Enhancing the interpretability and explainability of the model's decision-making process could lead to valuable insights and potential improvements.
-
Scalability and Efficiency: As the size and complexity of the documents increase, the computational and memory requirements of the framework may also grow. Investigating ways to improve the scalability and efficiency of the approach could make it more practical for real-world applications.
Overall, the paper presents an intriguing and potentially impactful approach to document-based zero-shot learning, but further research and evaluation would be valuable to fully understand its strengths, limitations, and practical applications.
Conclusion
This paper introduces a novel framework for document-based zero-shot learning that leverages visual-semantic decomposition and partial semantic alignment. By harnessing the rich semantic information in documents, the model can learn to recognize new visual concepts without requiring any additional labeled visual data.
The key contributions of the work are the end-to-end learning of visual-semantic decomposition and partial alignment, which allow the model to effectively associate textual and visual data and enable zero-shot recognition. While the paper demonstrates promising results, further research is needed to assess the framework's broader applicability, interpretability, and scalability.
Nevertheless, this work represents an important step forward in the field of zero-shot learning, highlighting the potential of leveraging document-based semantic knowledge to expand the visual recognition capabilities of computer vision models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Visual-Semantic Decomposition and Partial Alignment for Document-based Zero-Shot Learning
Xiangyan Qu, Jing Yu, Keke Gai, Jiamin Zhuang, Yuanmin Tang, Gang Xiong, Gaopeng Gou, Qi Wu
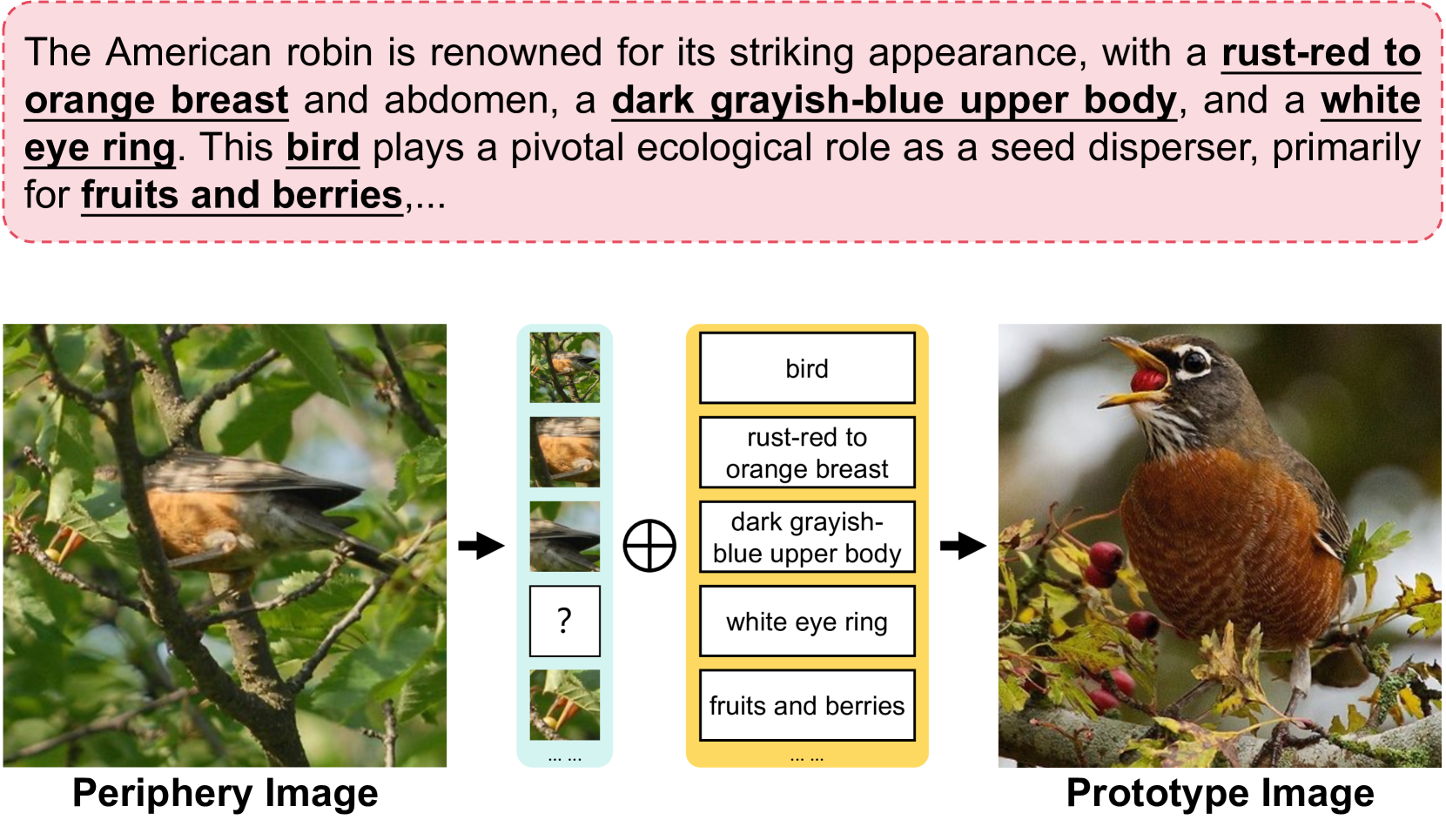
Recent work shows that documents from encyclopedias serve as helpful auxiliary information for zero-shot learning. Existing methods align the entire semantics of a document with corresponding images to transfer knowledge. However, they disregard that semantic information is not equivalent between them, resulting in a suboptimal alignment. In this work, we propose a novel network to extract multi-view semantic concepts from documents and images and align the matching rather than entire concepts. Specifically, we propose a semantic decomposition module to generate multi-view semantic embeddings from visual and textual sides, providing the basic concepts for partial alignment. To alleviate the issue of information redundancy among embeddings, we propose the local-to-semantic variance loss to capture distinct local details and multiple semantic diversity loss to enforce orthogonality among embeddings. Subsequently, two losses are introduced to partially align visual-semantic embedding pairs according to their semantic relevance at the view and word-to-patch levels. Consequently, we consistently outperform state-of-the-art methods under two document sources in three standard benchmarks for document-based zero-shot learning. Qualitatively, we show that our model learns the interpretable partial association.
Read more7/24/2024
0
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
Read more4/10/2024

0
Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Shiming Chen, Wenjin Hou, Salman Khan, Fahad Shahbaz Khan
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2. Codes are available at: https://github.com/shiming-chen/ZSLViT .
Read more7/23/2024

0
Epsilon: Exploring Comprehensive Visual-Semantic Projection for Multi-Label Zero-Shot Learning
Ziming Liu, Jingcai Guo, Song Guo, Xiaocheng Lu
This paper investigates a challenging problem of zero-shot learning in the multi-label scenario (MLZSL), wherein the model is trained to recognize multiple unseen classes within a sample (e.g., an image) based on seen classes and auxiliary knowledge, e.g., semantic information. Existing methods usually resort to analyzing the relationship of various seen classes residing in a sample from the dimension of spatial or semantic characteristics and transferring the learned model to unseen ones. However, they neglect the integrity of local and global features. Although the use of the attention structure will accurately locate local features, especially objects, it will significantly lose its integrity, and the relationship between classes will also be affected. Rough processing of global features will also directly affect comprehensiveness. This neglect will make the model lose its grasp of the main components of the image. Relying only on the local existence of seen classes during the inference stage introduces unavoidable bias. In this paper, we propose a novel and comprehensive visual-semantic framework for MLZSL, dubbed Epsilon, to fully make use of such properties and enable a more accurate and robust visual-semantic projection. In terms of spatial information, we achieve effective refinement by group aggregating image features into several semantic prompts. It can aggregate semantic information rather than class information, preserving the correlation between semantics. In terms of global semantics, we use global forward propagation to collect as much information as possible to ensure that semantics are not omitted. Experiments on large-scale MLZSL benchmark datasets NUS-Wide and Open-Images-v4 demonstrate that the proposed Epsilon outperforms other state-of-the-art methods with large margins.
Read more8/27/2024