VR-GPT: Visual Language Model for Intelligent Virtual Reality Applications
2405.11537
0
0

Abstract
The advent of immersive Virtual Reality applications has transformed various domains, yet their integration with advanced artificial intelligence technologies like Visual Language Models remains underexplored. This study introduces a pioneering approach utilizing VLMs within VR environments to enhance user interaction and task efficiency. Leveraging the Unity engine and a custom-developed VLM, our system facilitates real-time, intuitive user interactions through natural language processing, without relying on visual text instructions. The incorporation of speech-to-text and text-to-speech technologies allows for seamless communication between the user and the VLM, enabling the system to guide users through complex tasks effectively. Preliminary experimental results indicate that utilizing VLMs not only reduces task completion times but also improves user comfort and task engagement compared to traditional VR interaction methods.
Create account to get full access
Overview
- This paper introduces VR-GPT, a visual language model designed for intelligent virtual reality (VR) applications.
- VR-GPT combines advanced language understanding and generation capabilities with the ability to process and generate visual content, enabling more natural and intuitive interactions in VR environments.
- The model is trained on a large corpus of text and visual data, allowing it to understand and reason about the semantic relationships between language and visual information.
Plain English Explanation
VR-GPT is a new artificial intelligence (AI) system that is designed to work in virtual reality (VR) applications. It is a type of vision-language model that can understand and generate both text and visual content.
Traditionally, VR applications have relied on simplified command-based interactions, which can feel unnatural and limited. VR-GPT aims to change that by allowing users to interact with VR environments using more natural language. For example, a user could ask VR-GPT to "show me the view from the top of the mountain" or "find a comfortable place to sit," and the system would respond by generating the appropriate visual content and guiding the user through the VR space.
The key innovation of VR-GPT is that it is trained on a large amount of text and visual data, allowing it to understand the relationship between language and visual information. This means the system can not only understand what users are saying, but also how that relates to the visual elements of the VR environment. This enables more intuitive and intelligent interactions, similar to how vision-language models are being used to enhance robot explanation capabilities.
Technical Explanation
VR-GPT is a vision-language model that is designed to process and generate both textual and visual content in the context of virtual reality applications. The model is built upon a transformer-based architecture, similar to the original GPT language model, but with additional components for visual understanding and generation.
The key components of VR-GPT include:
- Visual Encoder: This module is responsible for processing visual inputs, such as images or 3D scene representations, and extracting meaningful features that can be used by the language model.
- Language Model: The core of VR-GPT is a large language model, similar to GPT, that has been trained on a vast corpus of text data. This allows the model to understand and generate natural language.
- Multimodal Fusion: The visual and language components are integrated through a multimodal fusion module, which learns to combine the representations from the visual and textual inputs to enable cross-modal reasoning and generation.
During training, VR-GPT is exposed to a diverse dataset that includes both textual descriptions of virtual environments and the corresponding visual representations. This allows the model to learn the semantic relationships between language and visual content, enabling it to generate relevant visual outputs based on natural language inputs and interpret language in the context of the visual scene.
The authors demonstrate the capabilities of VR-GPT through a series of experiments, showing that the model can effectively understand and respond to natural language commands in VR environments, as well as generate visual content to assist users.
Critical Analysis
The VR-GPT paper presents a promising approach for enhancing the user experience in virtual reality applications. However, there are a few potential limitations and areas for further research:
-
Dataset Biases: The performance of VR-GPT is heavily dependent on the quality and diversity of the training data. It is important to ensure that the dataset includes a broad range of virtual environments, languages, and user interactions to mitigate potential biases and ensure the model's robustness.
-
Real-time Performance: Deploying VR-GPT in real-time VR applications may pose challenges, as the model's computational requirements could impact the overall system's responsiveness. Further optimizations or the use of specialized hardware may be necessary to achieve the desired level of performance.
-
Safety and Ethical Considerations: As VR-GPT is designed to interact with users in an open-ended manner, there are potential concerns around safety, privacy, and ethical implications that should be carefully considered, such as ensuring the model's responses are appropriate and do not cause harm.
-
Multimodal Reasoning Limitations: While VR-GPT demonstrates impressive multimodal capabilities, its ability to reason about complex relationships between language and visual information may be limited. Further research is needed to explore more advanced multimodal reasoning techniques.
Overall, the VR-GPT paper presents an exciting step towards more natural and intelligent interactions in virtual reality environments. Continued research and development in this area could lead to significant improvements in the user experience and the broader application of vision-language models.
Conclusion
The VR-GPT paper introduces a novel visual language model that aims to enhance the user experience in virtual reality applications. By combining advanced language understanding and generation capabilities with the ability to process and generate visual content, VR-GPT enables more intuitive and intelligent interactions in VR environments.
The key innovation of VR-GPT is its ability to learn the semantic relationships between language and visual information, allowing the model to understand natural language commands in the context of the virtual scene and generate relevant visual outputs. This technology has the potential to revolutionize how users interact with and navigate VR spaces, paving the way for more engaging and immersive experiences.
While the VR-GPT paper presents promising results, there are still some challenges and areas for further research, such as addressing potential dataset biases, ensuring real-time performance, and considering the ethical implications of such a system. Nonetheless, the advancements made in this work represent an important step forward in the field of vision-language models and their application in virtual reality and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
0
0
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
5/28/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
💬
GameVLM: A Decision-making Framework for Robotic Task Planning Based on Visual Language Models and Zero-sum Games
Aoran Mei, Jianhua Wang, Guo-Niu Zhu, Zhongxue Gan
0
0
With their prominent scene understanding and reasoning capabilities, pre-trained visual-language models (VLMs) such as GPT-4V have attracted increasing attention in robotic task planning. Compared with traditional task planning strategies, VLMs are strong in multimodal information parsing and code generation and show remarkable efficiency. Although VLMs demonstrate great potential in robotic task planning, they suffer from challenges like hallucination, semantic complexity, and limited context. To handle such issues, this paper proposes a multi-agent framework, i.e., GameVLM, to enhance the decision-making process in robotic task planning. In this study, VLM-based decision and expert agents are presented to conduct the task planning. Specifically, decision agents are used to plan the task, and the expert agent is employed to evaluate these task plans. Zero-sum game theory is introduced to resolve inconsistencies among different agents and determine the optimal solution. Experimental results on real robots demonstrate the efficacy of the proposed framework, with an average success rate of 83.3%.
5/24/2024
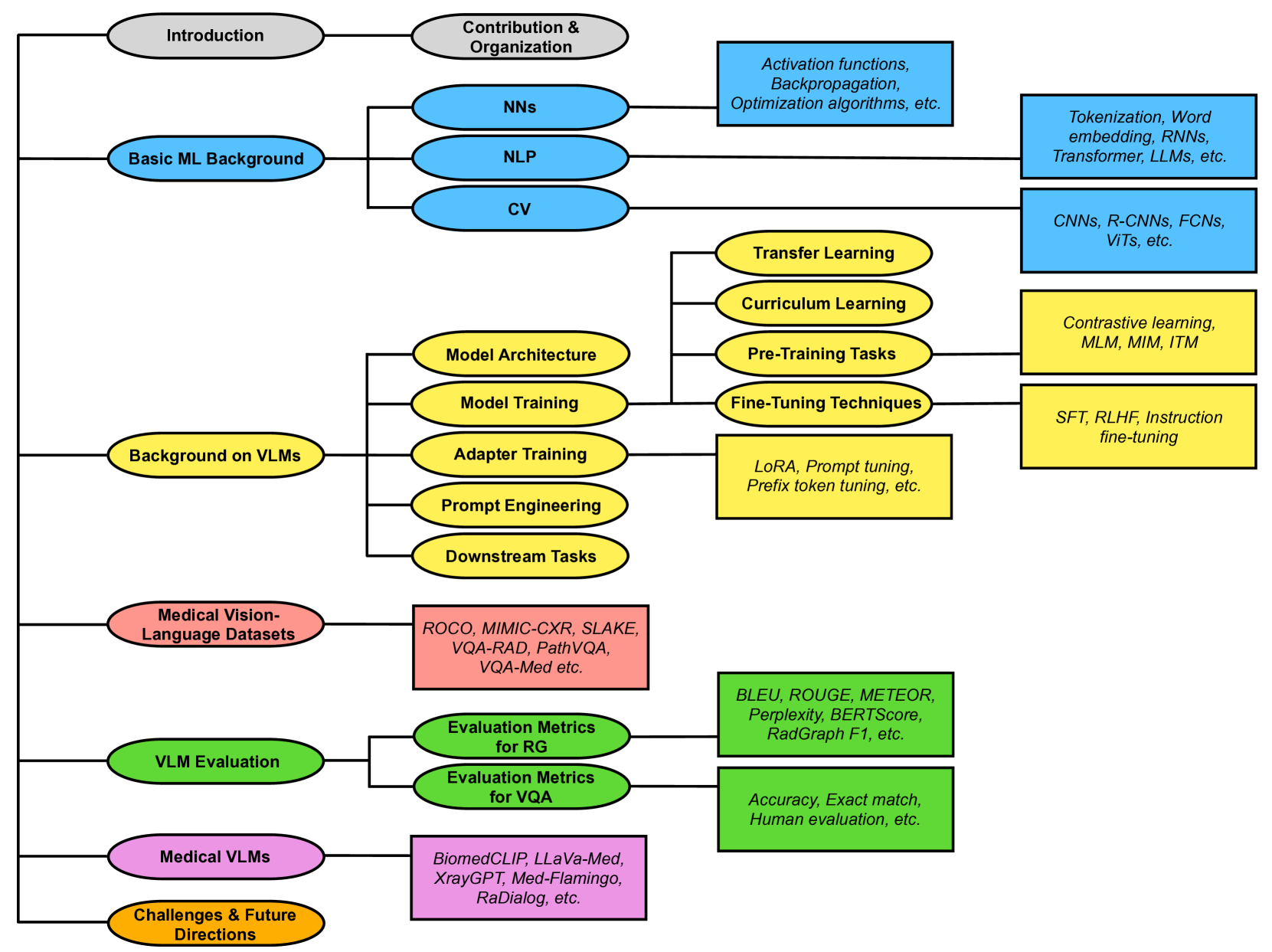
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
0
0
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
4/16/2024