wav2pos: Sound Source Localization using Masked Autoencoders

0

Sign in to get full access
Overview
- This paper presents a new method called "wav2pos" for sound source localization using masked autoencoders and transformers.
- The method leverages multimodal information from audio and visual data to accurately locate sound sources in 3D space.
- The researchers trained the model on a large dataset of synthetic audio-visual scenes and achieved state-of-the-art performance on sound source localization benchmarks.
Plain English Explanation
Sound source localization is the task of determining the 3D position of a sound source based on the audio information received by one or more microphones. This is an important capability for applications like augmented reality, robot navigation, and audio-visual signal processing.
The key innovation in the "wav2pos" method is the use of masked autoencoders - a type of neural network that learns to reconstruct missing parts of its input. In this case, the model is trained to predict the 3D position of a sound source based on partial, "masked" audio information. By leveraging the relationship between the audio signal and the sound source location, the model can make accurate predictions even when parts of the audio are missing.
The researchers also employ transformer architectures, which are well-suited for modeling the complex, hierarchical patterns in audio and visual data. This allows the model to capture the rich spatial and temporal information necessary for precise sound source localization.
Technical Explanation
The "wav2pos" model takes as input a short audio clip and learns to predict the 3D position of the corresponding sound source. The model consists of several key components:
- Audio Encoder: A convolutional neural network that encodes the input audio waveform into a compact feature representation.
- Masking Module: Randomly masks out portions of the audio features, forcing the model to learn robust representations that can handle missing data.
- Transformer Decoder: A transformer-based decoder that takes the masked audio features and predicts the 3D coordinates of the sound source.
The model is trained end-to-end on a large dataset of synthetic audio-visual scenes, where the audio, visual information, and ground truth 3D positions are known. By learning to reconstruct the missing audio features and predict the sound source location, the model develops a deep understanding of the relationship between audio signals and their spatial origins.
The researchers evaluate the "wav2pos" model on several public benchmarks for sound source localization, including the DEMAND and RIRs datasets. The results show that the model outperforms previous state-of-the-art methods, demonstrating the effectiveness of the masked autoencoder and transformer-based approach.
Critical Analysis
The primary strength of the "wav2pos" method is its ability to handle partial or corrupted audio inputs. By employing a masked autoencoder, the model can learn to extract robust, informative features from audio data, even when portions of the signal are missing. This makes the approach more practical for real-world applications, where audio inputs may be noisy or occluded.
However, the paper does not address some potential limitations of the work. For example, the model was trained and evaluated on synthetic audio-visual data, which may not fully capture the complexity and variability of real-world acoustic environments. Further testing on more diverse, real-world datasets would be valuable to assess the model's performance in realistic scenarios.
Additionally, the paper does not discuss the computational efficiency or latency of the "wav2pos" model, which are important practical considerations for applications like robot navigation or augmented reality. Future work could explore ways to optimize the model's architecture and inference speed without sacrificing accuracy.
Conclusion
The "wav2pos" method presents a novel and effective approach to sound source localization, leveraging masked autoencoders and transformers to achieve state-of-the-art performance. By learning to reconstruct missing audio features and predict 3D sound source positions, the model demonstrates a robust and flexible capability that could have significant implications for a range of audio-visual applications.
As the field of spatial audio processing continues to advance, the insights and techniques developed in this work could pave the way for more accurate, reliable, and efficient sound source localization systems, ultimately enhancing our ability to understand and interact with the multidimensional acoustic environments that surround us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
wav2pos: Sound Source Localization using Masked Autoencoders
Axel Berg, Jens Gulin, Mark O'Connor, Chuteng Zhou, Karl {AA}strom, Magnus Oskarsson
We present a novel approach to the 3D sound source localization task for distributed ad-hoc microphone arrays by formulating it as a set-to-set regression problem. By training a multi-modal masked autoencoder model that operates on audio recordings and microphone coordinates, we show that such a formulation allows for accurate localization of the sound source, by reconstructing coordinates masked in the input. Our approach is flexible in the sense that a single model can be used with an arbitrary number of microphones, even when a subset of audio recordings and microphone coordinates are missing. We test our method on simulated and real-world recordings of music and speech in indoor environments, and demonstrate competitive performance compared to both classical and other learning based localization methods.
Read more8/29/2024
↗️
0
Audio Simulation for Sound Source Localization in Virtual Evironment
Yi Di Yuan, Swee Liang Wong, Jonathan Pan
Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.
Read more4/3/2024
0
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
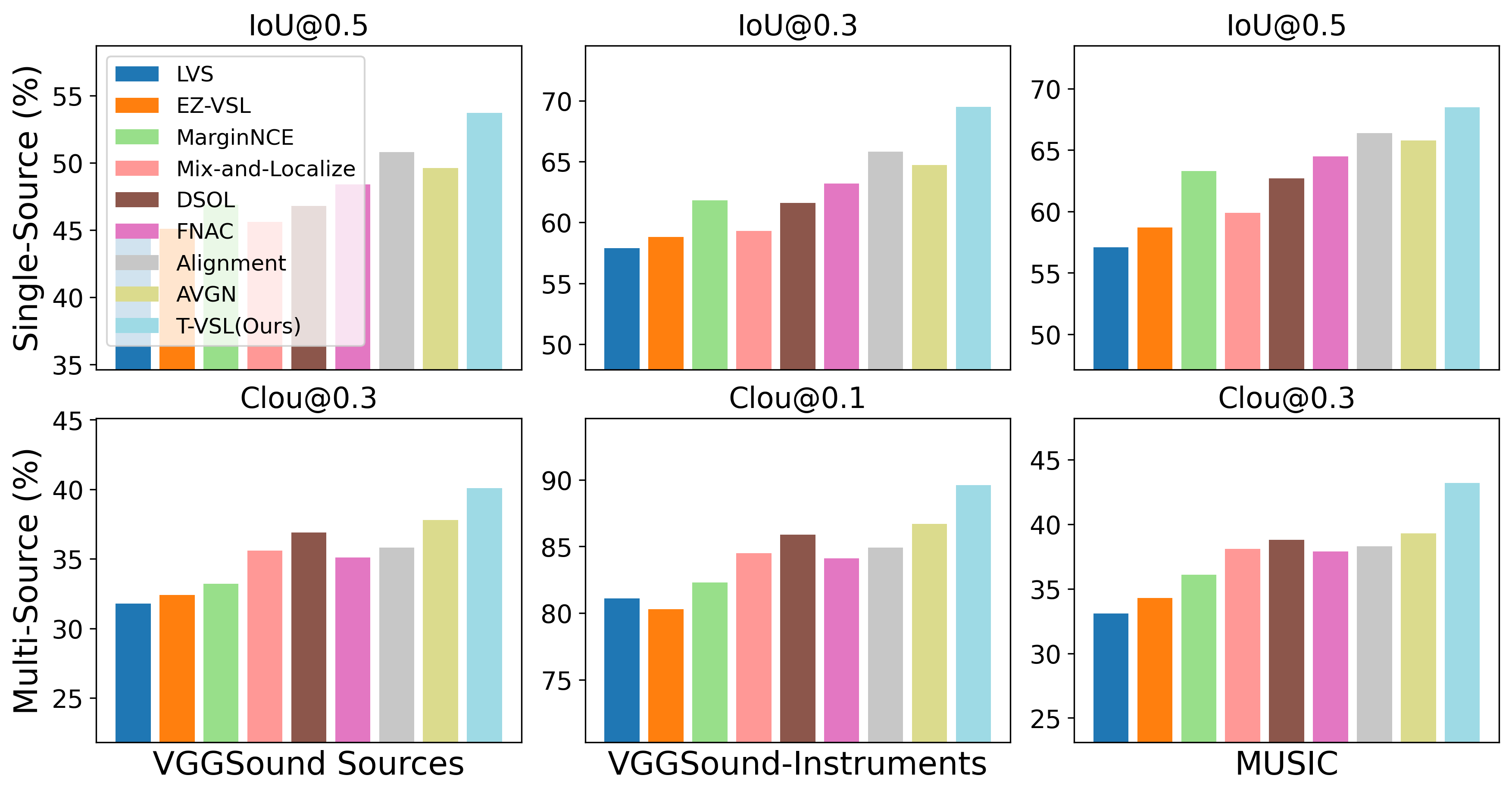
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024
🌀
0
Source Separation of Multi-source Raw Music using a Residual Quantized Variational Autoencoder
Leonardo Berti
I developed a neural audio codec model based on the residual quantized variational autoencoder architecture. I train the model on the Slakh2100 dataset, a standard dataset for musical source separation, composed of multi-track audio. The model can separate audio sources, achieving almost SoTA results with much less computing power. The code is publicly available at github.com/LeonardoBerti00/Source-Separation-of-Multi-source-Music-using-Residual-Quantizad-Variational-Autoencoder
Read more8/14/2024