We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?

0
Sign in to get full access
Overview
- This paper, titled "We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?", investigates the ability of large multimodal models to perform human-like mathematical reasoning.
- The authors introduce a new benchmark called "We-Math" that assesses a model's mathematical reasoning capabilities across various modalities, including text, images, and equations.
- The paper evaluates the performance of several state-of-the-art large language models and multimodal models on the We-Math benchmark and compares their results to human-level performance.
Plain English Explanation
The research paper examines whether large AI models that can handle multiple types of data (like text, images, and math equations) can reason about math in a way that's similar to how humans do. The authors created a new test called "We-Math" that looks at how well these models can solve different kinds of math problems. They then tested several of the latest and greatest AI models on this benchmark and compared their results to how well people do on the same tasks.
The key idea is to see if these advanced AI systems can truly understand and reason about math in a human-like way, rather than just memorizing patterns or following rules. By using a diverse set of math problems that require different types of reasoning, the researchers can get a more nuanced picture of the models' mathematical abilities. This builds on previous work on evaluating large language models' math skills.
The results of this study could help advance the field of multimodal AI and shed light on the current state-of-the-art in terms of machine mathematical reasoning. It may also point to areas where these models still struggle compared to humans, which could guide future research and development.
Technical Explanation
The paper introduces a new benchmark called "We-Math" that aims to comprehensively evaluate the mathematical reasoning capabilities of large multimodal models. The benchmark consists of a diverse set of math problems that span different modalities, including text, images, and equations.
The authors evaluated the performance of several state-of-the-art models, including large language models (LLMs) like GPT-3 and multimodal models like DALL-E 2 and ViLT, on the We-Math benchmark. They compared the models' results to human-level performance on the same tasks.
The key insights from the study include:
- The multimodal models generally outperformed the LLMs on the We-Math benchmark, suggesting that the ability to reason about multiple modalities is important for human-like mathematical reasoning.
- However, even the best-performing multimodal models still fell short of human-level performance on many of the tasks, indicating that there is still significant room for improvement.
- The authors identified specific areas where the models struggled, such as solving complex math word problems and reasoning about spatial relationships in geometric problems.
These findings build on previous work on evaluating large language models' mathematical reasoning abilities and benchmarking multimodal models' capabilities. The new We-Math benchmark provides a more comprehensive and challenging assessment of mathematical reasoning, with the goal of advancing the multimodal math evaluation process.
Critical Analysis
The paper presents a thoughtful and well-designed benchmark for assessing the mathematical reasoning capabilities of large multimodal models. The authors have done a commendable job of creating a diverse set of math problems that span different modalities and levels of complexity.
One potential limitation of the study is the relatively small set of models evaluated. While the authors included some of the most prominent LLMs and multimodal models, there are many other systems that could be tested on the We-Math benchmark. Expanding the evaluation to a wider range of models could provide a more comprehensive understanding of the state of the field.
Additionally, the paper does not delve deeply into the specific reasons why the models struggled on certain types of problems. Further research investigating the underlying strengths and weaknesses of these models could yield valuable insights to guide future model development and training.
Overall, the We-Math benchmark represents an important step forward in assessing the progress and challenges of large language models and multimodal systems in mathematical reasoning. The findings could help drive the development of more capable and human-like AI systems for mathematical problem-solving.
Conclusion
The paper presents a new benchmark called "We-Math" that comprehensively evaluates the mathematical reasoning capabilities of large multimodal AI models. The results show that while these models have made significant strides, they still fall short of human-level performance on many math-related tasks.
The findings from this study could have important implications for the ongoing development of multimodal AI systems and our understanding of the current state of machine mathematical reasoning. The insights gained from the We-Math benchmark may help guide future research and development efforts to create AI systems that can reason about math in a more human-like way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, Runfeng Qiao, Yifan Zhang, Xiao Zong, Yida Xu, Muxi Diao, Zhimin Bao, Chen Li, Honggang Zhang
Visual mathematical reasoning, as a fundamental visual reasoning ability, has received widespread attention from the Large Multimodal Models (LMMs) community. Existing benchmarks, such as MathVista and MathVerse, focus more on the result-oriented performance but neglect the underlying principles in knowledge acquisition and generalization. Inspired by human-like mathematical reasoning, we introduce WE-MATH, the first benchmark specifically designed to explore the problem-solving principles beyond end-to-end performance. We meticulously collect and categorize 6.5K visual math problems, spanning 67 hierarchical knowledge concepts and five layers of knowledge granularity. We decompose composite problems into sub-problems according to the required knowledge concepts and introduce a novel four-dimensional metric, namely Insufficient Knowledge (IK), Inadequate Generalization (IG), Complete Mastery (CM), and Rote Memorization (RM), to hierarchically assess inherent issues in LMMs' reasoning process. With WE-MATH, we conduct a thorough evaluation of existing LMMs in visual mathematical reasoning and reveal a negative correlation between solving steps and problem-specific performance. We confirm the IK issue of LMMs can be effectively improved via knowledge augmentation strategies. More notably, the primary challenge of GPT-4o has significantly transitioned from IK to IG, establishing it as the first LMM advancing towards the knowledge generalization stage. In contrast, other LMMs exhibit a marked inclination towards Rote Memorization - they correctly solve composite problems involving multiple knowledge concepts yet fail to answer sub-problems. We anticipate that WE-MATH will open new pathways for advancements in visual mathematical reasoning for LMMs. The WE-MATH data and evaluation code are available at https://github.com/We-Math/We-Math.
Read more7/2/2024

0
Advancing Geometric Problem Solving: A Comprehensive Benchmark for Multimodal Model Evaluation
Kai Sun, Yushi Bai, Ji Qi, Lei Hou, Juanzi Li
To advance the evaluation of multimodal math reasoning in large multimodal models (LMMs), this paper introduces a novel benchmark, MM-MATH. MM-MATH consists of 5,929 open-ended middle school math problems with visual contexts, with fine-grained classification across difficulty, grade level, and knowledge points. Unlike existing benchmarks relying on binary answer comparison, MM-MATH incorporates both outcome and process evaluations. Process evaluation employs LMM-as-a-judge to automatically analyze solution steps, identifying and categorizing errors into specific error types. Extensive evaluation of ten models on MM-MATH reveals significant challenges for existing LMMs, highlighting their limited utilization of visual information and struggles with higher-difficulty problems. The best-performing model achieves only 31% accuracy on MM-MATH, compared to 82% for humans. This highlights the challenging nature of our benchmark for existing models and the significant gap between the multimodal reasoning capabilities of current models and humans. Our process evaluation reveals that diagram misinterpretation is the most common error, accounting for more than half of the total error cases, underscoring the need for improved image comprehension in multimodal reasoning.
Read more6/28/2024
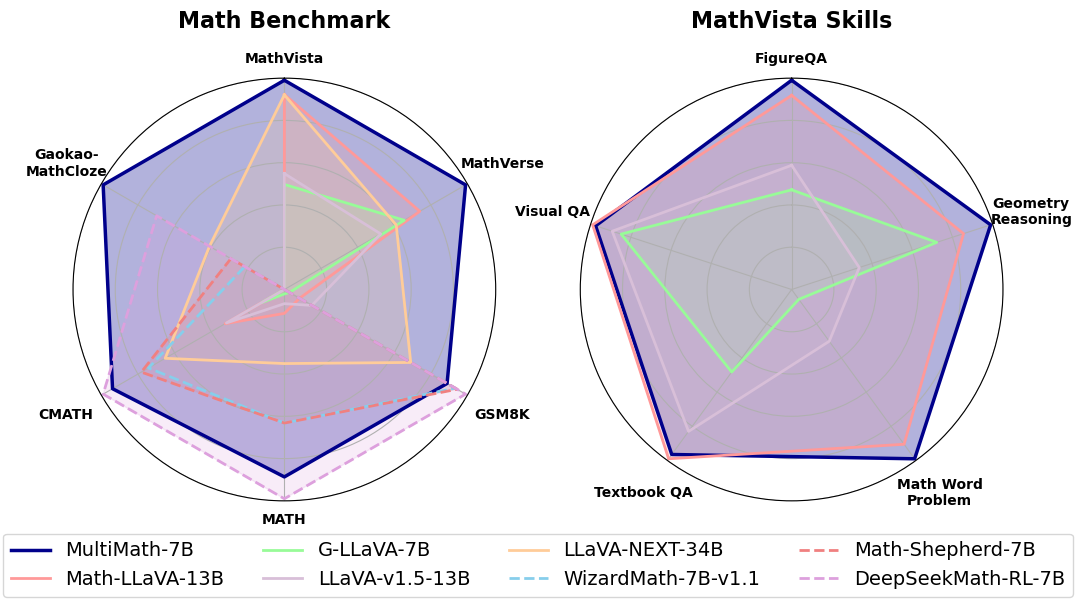
0
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024

0
CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models
Wentao Liu, Qianjun Pan, Yi Zhang, Zhuo Liu, Ji Wu, Jie Zhou, Aimin Zhou, Qin Chen, Bo Jiang, Liang He
Large language models (LLMs) have obtained promising results in mathematical reasoning, which is a foundational skill for human intelligence. Most previous studies focus on improving and measuring the performance of LLMs based on textual math reasoning datasets (e.g., MATH, GSM8K). Recently, a few researchers have released English multimodal math datasets (e.g., MATHVISTA and MATH-V) to evaluate the effectiveness of large multimodal models (LMMs). In this paper, we release a Chinese multimodal math (CMM-Math) dataset, including benchmark and training parts, to evaluate and enhance the mathematical reasoning of LMMs. CMM-Math contains over 28,000 high-quality samples, featuring a variety of problem types (e.g., multiple-choice, fill-in-the-blank, and so on) with detailed solutions across 12 grade levels from elementary to high school in China. Specifically, the visual context may be present in the questions or opinions, which makes this dataset more challenging. Through comprehensive analysis, we discover that state-of-the-art LMMs on the CMM-Math dataset face challenges, emphasizing the necessity for further improvements in LMM development. We also propose a Multimodal Mathematical LMM (Math-LMM) to handle the problems with mixed input of multiple images and text segments. We train our model using three stages, including foundational pre-training, foundational fine-tuning, and mathematical fine-tuning. The extensive experiments indicate that our model effectively improves math reasoning performance by comparing it with the SOTA LMMs over three multimodal mathematical datasets.
Read more9/9/2024