Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models

0
Sign in to get full access
Overview
- The paper "Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models" proposes a novel approach to aligning large language models with human values and preferences.
- The key idea is to use a search over smaller, more interpretable language models to guide the alignment of larger, more powerful models.
- This approach aims to address the challenge of aligning complex, black-box models with human values, which is a crucial problem in the field of AI safety and robustness.
Plain English Explanation
Large language models (LLMs), such as GPT-3 and Megatron-LLM, have shown impressive capabilities in a wide range of natural language tasks. However, aligning these powerful models with human values and preferences is a significant challenge. The authors of this paper propose a "weak-to-strong" search approach to address this problem.
The core idea is to use smaller, more interpretable language models as a stepping stone to align the larger, more complex LLMs. The authors start by training a collection of smaller models, each of which represents a different value or preference. They then use these smaller models to guide the search for an alignment of the larger LLM.
This approach is analogous to using smaller models to expedite alignment, or using Bayesian persuasion to efficiently align models. By leveraging the interpretability of the smaller models, the authors aim to make the alignment process more transparent and controllable, ultimately leading to LLMs that better reflect human values.
Technical Explanation
The paper proposes a "weak-to-strong search" approach to align large language models (LLMs) with human values and preferences. The key steps of the approach are:
-
Train a collection of small language models: The authors train a set of smaller, more interpretable language models, each of which represents a different value or preference. These models are referred to as the "weak" models.
-
Search over the small models to find an alignment: The authors then use a search algorithm to find a combination of the weak models that best aligns with the target LLM. This search process is guided by the statistical framework for weak-to-strong generalization and the quantifying gain from weak-to-strong generalization principles.
-
Align the large language model: Once the optimal combination of weak models is found, the authors use this information to guide the alignment of the target LLM, such as AlignGPT.
The key advantage of this approach is that it leverages the interpretability of the smaller, "weak" models to make the alignment of the larger, "strong" LLM more transparent and controllable. This addresses a crucial challenge in the field of AI safety and robustness, where aligning complex, black-box models with human values is a significant problem.
Critical Analysis
The "weak-to-strong search" approach proposed in this paper is a promising step towards aligning large language models with human values and preferences. However, the authors acknowledge several caveats and limitations that warrant further research:
-
Scalability: While the approach leverages smaller models to guide the alignment of larger models, the authors note that the search process may still be computationally intensive, especially as the size of the LLM and the number of weak models increase.
-
Representational power: The authors recognize that the set of weak models may not be able to fully capture the complexity and nuance of human values, which could limit the effectiveness of the alignment process.
-
Generalization: The paper focuses on aligning LLMs with a specific set of values and preferences, but it is unclear how well the approach would generalize to a broader range of human values or to different types of AI systems.
-
Ethical considerations: As with any approach to aligning AI systems with human values, there are important ethical considerations around the selection and representation of those values, as well as the potential for unintended consequences.
Overall, the "weak-to-strong search" approach represents an important contribution to the field of AI alignment, but further research is needed to address the limitations and explore the broader implications of this approach.
Conclusion
The paper "Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models" proposes a novel approach to aligning large language models with human values and preferences. By using a search over smaller, more interpretable models to guide the alignment of larger, more complex models, the authors aim to make the alignment process more transparent and controllable.
This research addresses a crucial challenge in the field of AI safety and robustness, and the "weak-to-strong search" approach represents a promising step towards developing AI systems that better reflect human values. While the approach has some limitations, the authors' work contributes valuable insights and a new direction for future research in this important area of AI alignment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models
Zhanhui Zhou, Zhixuan Liu, Jie Liu, Zhichen Dong, Chao Yang, Yu Qiao
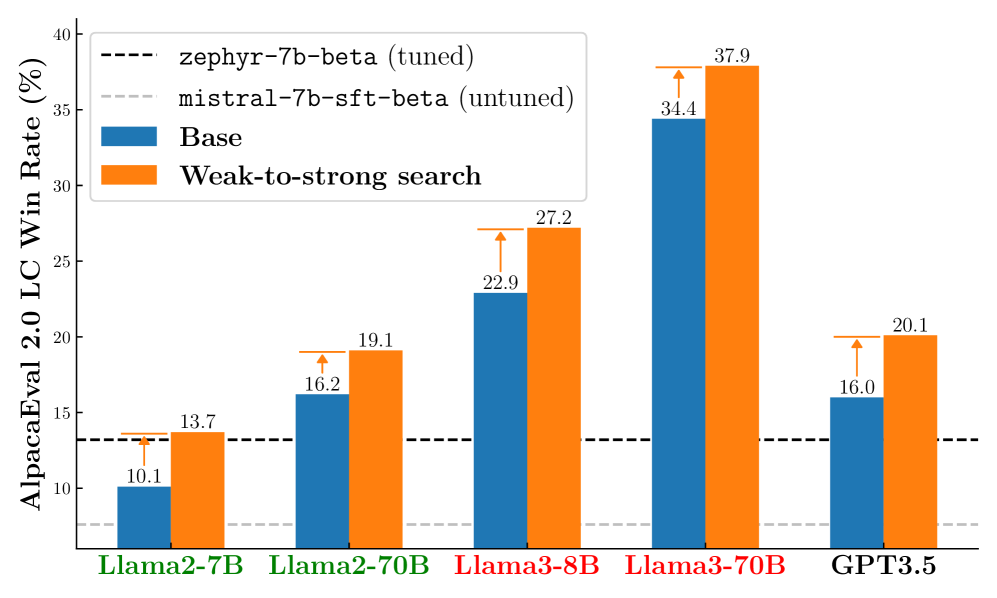
Large language models are usually fine-tuned to align with human preferences. However, fine-tuning a large language model can be challenging. In this work, we introduce $textit{weak-to-strong search}$, framing the alignment of a large language model as a test-time greedy search to maximize the log-likelihood difference between small tuned and untuned models while sampling from the frozen large model. This method serves both as (i) a compute-efficient model up-scaling strategy that avoids directly tuning the large model and as (ii) an instance of weak-to-strong generalization that enhances a strong model with weak test-time guidance. Empirically, we demonstrate the flexibility of weak-to-strong search across different tasks. In controlled-sentiment generation and summarization, we use tuned and untuned $texttt{gpt2}$s to effectively improve the alignment of large models without additional training. Crucially, in a more difficult instruction-following benchmark, AlpacaEval 2.0, we show that reusing off-the-shelf small model pairs (e.g., $texttt{zephyr-7b-beta}$ and its untuned version) can significantly improve the length-controlled win rates of both white-box and black-box large models against $texttt{gpt-4-turbo}$ (e.g., $34.4 rightarrow 37.9$ for $texttt{Llama-3-70B-Instruct}$ and $16.0 rightarrow 20.1$ for $texttt{gpt-3.5-turbo-instruct}$), despite the small models' low win rates $approx 10.0$.
Read more5/30/2024

0
Bayesian WeakS-to-Strong from Text Classification to Generation
Ziyun Cui, Ziyang Zhang, Wen Wu, Guangzhi Sun, Chao Zhang
Advances in large language models raise the question of how alignment techniques will adapt as models become increasingly complex and humans will only be able to supervise them weakly. Weak-to-Strong mimics such a scenario where weak model supervision attempts to harness the full capabilities of a much stronger model. This work extends Weak-to-Strong to WeakS-to-Strong by exploring an ensemble of weak models which simulate the variability in human opinions. Confidence scores are estimated using a Bayesian approach to guide the WeakS-to-Strong generalization. Furthermore, we extend the application of WeakS-to-Strong from text classification tasks to text generation tasks where more advanced strategies are investigated for supervision. Moreover, direct preference optimization is applied to advance the student model's preference learning, beyond the basic learning framework of teacher forcing. Results demonstrate the effectiveness of the proposed approach for the reliability of a strong student model, showing potential for superalignment.
Read more6/6/2024

0
Quantifying the Gain in Weak-to-Strong Generalization
Moses Charikar, Chirag Pabbaraju, Kirankumar Shiragur
Recent advances in large language models have shown capabilities that are extraordinary and near-superhuman. These models operate with such complexity that reliably evaluating and aligning them proves challenging for humans. This leads to the natural question: can guidance from weak models (like humans) adequately direct the capabilities of strong models? In a recent and somewhat surprising work, Burns et al. (2023) empirically demonstrated that when strong models (like GPT-4) are finetuned using labels generated by weak supervisors (like GPT-2), the strong models outperform their weaker counterparts -- a phenomenon they term weak-to-strong generalization. In this work, we present a theoretical framework for understanding weak-to-strong generalization. Specifically, we show that the improvement in performance achieved by strong models over their weaker counterparts is quantified by the misfit error incurred by the strong model on labels generated by the weaker model. Our theory reveals several curious algorithmic insights. For instance, we can predict the amount by which the strong model will improve over the weak model, and also choose among different weak models to train the strong model, based on its misfit error. We validate our theoretical findings through various empirical assessments.
Read more5/27/2024
🤯
0
A statistical framework for weak-to-strong generalization
Seamus Somerstep, Felipe Maia Polo, Moulinath Banerjee, Ya'acov Ritov, Mikhail Yurochkin, Yuekai Sun
Modern large language model (LLM) alignment techniques rely on human feedback, but it is unclear whether the techniques fundamentally limit the capabilities of aligned LLMs. In particular, it is unclear whether it is possible to align (stronger) LLMs with superhuman capabilities with (weaker) human feedback without degrading their capabilities. This is an instance of the weak-to-strong generalization problem: using weaker (less capable) feedback to train a stronger (more capable) model. We prove that weak-to-strong generalization is possible by eliciting latent knowledge from pre-trained LLMs. In particular, we cast the weak-to-strong generalization problem as a transfer learning problem in which we wish to transfer a latent concept from a weak model to a strong pre-trained model. We prove that a naive fine-tuning approach suffers from fundamental limitations, but an alternative refinement-based approach suggested by the problem structure provably overcomes the limitations of fine-tuning. Finally, we demonstrate the practical applicability of the refinement approach with three LLM alignment tasks.
Read more5/28/2024