Bayesian WeakS-to-Strong from Text Classification to Generation

0

Sign in to get full access
Overview
- This paper explores a Bayesian approach to training machine learning models that can generalize from weak to strong supervision, with applications in both text classification and text generation tasks.
- The authors propose a Bayesian WeakS-to-Strong framework that learns a shared representation between weak and strong supervision signals, allowing the model to leverage weak supervision to improve performance on strongly supervised tasks.
- The framework is evaluated on several text classification and generation benchmarks, demonstrating strong performance compared to baseline approaches.
Plain English Explanation
The paper looks at a way to train machine learning models that can start with "weak" supervision (e.g. less detailed or noisier training data) and then gradually improve to "strong" supervision (e.g. high-quality, curated training data). This is an important problem because it can be expensive and time-consuming to collect large amounts of high-quality training data for complex AI tasks.
The key idea is to have the model learn a shared representation between the weak and strong supervision signals. This allows the model to leverage the abundant but imperfect weak supervision data to improve its performance on the scarce but high-quality strong supervision data. This is similar to how humans can learn new skills by starting with approximate knowledge and then refining it over time.
The authors evaluate their Bayesian WeakS-to-Strong framework on text classification and generation tasks, where it outperforms other approaches that don't make use of the connection between weak and strong supervision. This suggests the framework could be a useful tool for building high-performing AI models when only limited amounts of curated training data are available.
Technical Explanation
The paper proposes a Bayesian framework for training machine learning models that can generalize from weak to strong supervision. The key components of this framework are:
- A shared representation layer that encodes both the weak and strong supervision signals.
- A Bayesian modeling approach that learns the parameters of this shared representation in a principled way, using both the weak and strong supervision data.
- Techniques for effectively optimizing the model to leverage the weak supervision during training, such as a novel weak-to-strong search alignment procedure.
The authors evaluate this Bayesian WeakS-to-Strong framework on several text classification and generation benchmarks, including sentiment analysis, question answering, and language modeling tasks. They show that it outperforms alternative approaches that do not make use of the connection between weak and strong supervision.
Critical Analysis
The theoretical analysis provided in the paper offers a solid foundation for understanding how the Bayesian WeakS-to-Strong framework can lead to improved generalization performance. However, the authors acknowledge that further research is needed to fully characterize the conditions under which this framework will be most effective.
One potential limitation is that the framework assumes the weak and strong supervision signals are related in a specific way (i.e., they share a common underlying representation). In practice, the relationship between weak and strong supervision may be more complex, and developing more flexible modeling approaches could be an important area for future work.
Additionally, while the empirical results are promising, it would be valuable to see the framework evaluated on a wider range of tasks and datasets to better understand its broader applicability and limitations.
Conclusion
Overall, this paper presents a novel Bayesian approach to training models that can effectively leverage weak supervision signals to improve performance on strongly supervised tasks. The technical contributions and empirical results suggest this framework could be a valuable tool for building high-performing AI systems when only limited amounts of curated training data are available. Further research to explore the framework's broader applicability and robustness could help unlock its full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bayesian WeakS-to-Strong from Text Classification to Generation
Ziyun Cui, Ziyang Zhang, Wen Wu, Guangzhi Sun, Chao Zhang
Advances in large language models raise the question of how alignment techniques will adapt as models become increasingly complex and humans will only be able to supervise them weakly. Weak-to-Strong mimics such a scenario where weak model supervision attempts to harness the full capabilities of a much stronger model. This work extends Weak-to-Strong to WeakS-to-Strong by exploring an ensemble of weak models which simulate the variability in human opinions. Confidence scores are estimated using a Bayesian approach to guide the WeakS-to-Strong generalization. Furthermore, we extend the application of WeakS-to-Strong from text classification tasks to text generation tasks where more advanced strategies are investigated for supervision. Moreover, direct preference optimization is applied to advance the student model's preference learning, beyond the basic learning framework of teacher forcing. Results demonstrate the effectiveness of the proposed approach for the reliability of a strong student model, showing potential for superalignment.
Read more10/3/2024

0
Quantifying the Gain in Weak-to-Strong Generalization
Moses Charikar, Chirag Pabbaraju, Kirankumar Shiragur
Recent advances in large language models have shown capabilities that are extraordinary and near-superhuman. These models operate with such complexity that reliably evaluating and aligning them proves challenging for humans. This leads to the natural question: can guidance from weak models (like humans) adequately direct the capabilities of strong models? In a recent and somewhat surprising work, Burns et al. (2023) empirically demonstrated that when strong models (like GPT-4) are finetuned using labels generated by weak supervisors (like GPT-2), the strong models outperform their weaker counterparts -- a phenomenon they term weak-to-strong generalization. In this work, we present a theoretical framework for understanding weak-to-strong generalization. Specifically, we show that the improvement in performance achieved by strong models over their weaker counterparts is quantified by the misfit error incurred by the strong model on labels generated by the weaker model. Our theory reveals several curious algorithmic insights. For instance, we can predict the amount by which the strong model will improve over the weak model, and also choose among different weak models to train the strong model, based on its misfit error. We validate our theoretical findings through various empirical assessments.
Read more5/27/2024
0
Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models
Zhanhui Zhou, Zhixuan Liu, Jie Liu, Zhichen Dong, Chao Yang, Yu Qiao
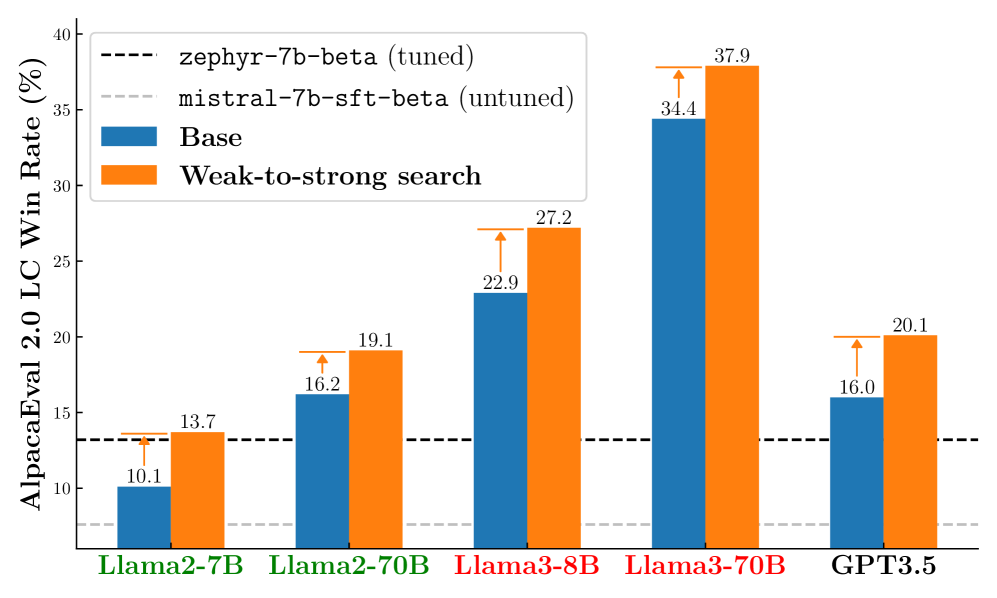
Large language models are usually fine-tuned to align with human preferences. However, fine-tuning a large language model can be challenging. In this work, we introduce $textit{weak-to-strong search}$, framing the alignment of a large language model as a test-time greedy search to maximize the log-likelihood difference between small tuned and untuned models while sampling from the frozen large model. This method serves both as (i) a compute-efficient model up-scaling strategy that avoids directly tuning the large model and as (ii) an instance of weak-to-strong generalization that enhances a strong model with weak test-time guidance. Empirically, we demonstrate the flexibility of weak-to-strong search across different tasks. In controlled-sentiment generation and summarization, we use tuned and untuned $texttt{gpt2}$s to effectively improve the alignment of large models without additional training. Crucially, in a more difficult instruction-following benchmark, AlpacaEval 2.0, we show that reusing off-the-shelf small model pairs (e.g., $texttt{zephyr-7b-beta}$ and its untuned version) can significantly improve the length-controlled win rates of both white-box and black-box large models against $texttt{gpt-4-turbo}$ (e.g., $34.4 rightarrow 37.9$ for $texttt{Llama-3-70B-Instruct}$ and $16.0 rightarrow 20.1$ for $texttt{gpt-3.5-turbo-instruct}$), despite the small models' low win rates $approx 10.0$.
Read more5/30/2024

0
Weak-to-Strong Reasoning
Yuqing Yang, Yan Ma, Pengfei Liu
When large language models (LLMs) exceed human-level capabilities, it becomes increasingly challenging to provide full-scale and accurate supervision for these models. Weak-to-strong learning, which leverages a less capable model to unlock the latent abilities of a stronger model, proves valuable in this context. Yet, the efficacy of this approach for complex reasoning tasks is still untested. Furthermore, tackling reasoning tasks under the weak-to-strong setting currently lacks efficient methods to avoid blindly imitating the weak supervisor including its errors. In this paper, we introduce a progressive learning framework that enables the strong model to autonomously refine its training data, without requiring input from either a more advanced model or human-annotated data. This framework begins with supervised fine-tuning on a selective small but high-quality dataset, followed by preference optimization on contrastive samples identified by the strong model itself. Extensive experiments on the GSM8K and MATH datasets demonstrate that our method significantly enhances the reasoning capabilities of Llama2-70b using three separate weak models. This method is further validated in a forward-looking experimental setup, where Llama3-8b-instruct effectively supervises Llama3-70b on the highly challenging OlympicArena dataset. This work paves the way for a more scalable and sophisticated strategy to enhance AI reasoning powers. All relevant code and resources are available in url{https://github.com/GAIR-NLP/weak-to-strong-reasoning}.
Read more10/2/2024