When Fairness Meets Privacy: Exploring Privacy Threats in Fair Binary Classifiers via Membership Inference Attacks

0
🤯
Sign in to get full access
Overview
- Recent research has developed fairness methods to address discriminatory behaviors in biased machine learning models.
- While these fairness-enhanced models have shown promise, they may be vulnerable to membership inference attacks (MIAs).
- MIAs allow adversaries to determine whether a specific data sample was used during model training by analyzing the model's prediction scores.
- However, the paper finds that score-based MIAs are ineffective against fairness-enhanced models in binary classification tasks.
- Fairness methods can lead to performance degradation for majority subgroups, raising the barrier to successful attacks and widening prediction gaps between member and non-member data.
Plain English Explanation
Machine learning models can sometimes exhibit unfair or discriminatory behaviors, treating certain groups of people differently than others. Researchers have developed "fairness methods" to address this issue and make the models more equitable.
While these fairness-enhanced models have shown promise, a potential vulnerability has been identified. Attackers can try to infer whether a specific data sample was used to train the model by analyzing the model's prediction scores. This is known as a "membership inference attack" (MIA).
However, the research finds that these score-based MIAs are not very effective against fairness-enhanced models in binary classification tasks (e.g., predicting whether someone will default on a loan or not). The attack models used by the adversaries end up being quite simplistic, reducing their performance.
Interestingly, the researchers also observe that fairness methods often lead to worse prediction performance for the majority subgroups in the training data. This raises the difficulty for successful attacks and widens the gaps between the model's predictions for data samples that were used in training versus those that weren't.
Building on these insights, the researchers propose a new and more effective MIA method called "FD-MIA" that leverages the differences in predictions between the original and fairness-enhanced models. Extensive experiments validate the effectiveness of this approach.
Technical Explanation
The paper investigates the vulnerability of fairness-enhanced machine learning models to membership inference attacks (MIAs). MIAs allow adversaries to determine whether a specific data sample was used during model training by analyzing the model's prediction scores.
The researchers find that score-based MIAs are largely ineffective against fairness-enhanced models in binary classification tasks. The attack models trained to launch these MIAs degrade into simplistic threshold models, resulting in lower attack performance.
The researchers also observe that fairness methods often lead to prediction performance degradation for the majority subgroups of the training data. This raises the barrier to successful attacks and widens the prediction gaps between member and non-member data.
Building upon these insights, the researchers propose a new MIA method called "FD-MIA" (fairness discrepancy-based MIA). FD-MIA leverages the difference in predictions from both the original and fairness-enhanced models, exploiting the observed prediction gaps as attack clues.
The paper presents extensive experiments validating the effectiveness of the proposed FD-MIA method compared to existing score-based MIAs when targeting fairness-enhanced models. The researchers also explore potential strategies for mitigating privacy leakages in these settings.
Critical Analysis
The paper provides valuable insights into the vulnerabilities and robustness of fairness-enhanced machine learning models against membership inference attacks. The researchers' finding that score-based MIAs are largely ineffective against these models is an important contribution, as it suggests that the fairness enhancements can provide some level of privacy protection.
However, the researchers acknowledge that the proposed FD-MIA method may still pose a risk, as it can potentially exploit the prediction gaps introduced by fairness methods. Further research may be needed to explore additional privacy-preserving techniques that can mitigate such attacks without compromising the fairness objectives.
Additionally, the paper focuses on binary classification tasks, and it would be valuable to investigate the implications of fairness-enhanced models and MIAs in other ML problem domains, such as regression or multiclass classification.
Conclusion
This research highlights the interplay between fairness, privacy, and the robustness of machine learning models. The findings suggest that fairness-enhanced models can be more resilient to certain membership inference attacks, but they may also introduce new vulnerabilities that need to be addressed.
The proposed FD-MIA method provides a more effective way for adversaries to infer membership in fairness-enhanced models, underscoring the need for continued research and development of privacy-preserving techniques that can maintain fairness without compromising model security. As machine learning becomes more widespread, understanding and mitigating these trade-offs will be crucial for building trustworthy and responsible AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
When Fairness Meets Privacy: Exploring Privacy Threats in Fair Binary Classifiers via Membership Inference Attacks
Huan Tian, Guangsheng Zhang, Bo Liu, Tianqing Zhu, Ming Ding, Wanlei Zhou
Previous studies have developed fairness methods for biased models that exhibit discriminatory behaviors towards specific subgroups. While these models have shown promise in achieving fair predictions, recent research has identified their potential vulnerability to score-based membership inference attacks (MIAs). In these attacks, adversaries can infer whether a particular data sample was used during training by analyzing the model's prediction scores. However, our investigations reveal that these score-based MIAs are ineffective when targeting fairness-enhanced models in binary classifications. The attack models trained to launch the MIAs degrade into simplistic threshold models, resulting in lower attack performance. Meanwhile, we observe that fairness methods often lead to prediction performance degradation for the majority subgroups of the training data. This raises the barrier to successful attacks and widens the prediction gaps between member and non-member data. Building upon these insights, we propose an efficient MIA method against fairness-enhanced models based on fairness discrepancy results (FD-MIA). It leverages the difference in the predictions from both the original and fairness-enhanced models and exploits the observed prediction gaps as attack clues. We also explore potential strategies for mitigating privacy leakages. Extensive experiments validate our findings and demonstrate the efficacy of the proposed method.
Read more8/28/2024
🤯
0
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Eric Aubinais, Elisabeth Gassiat, Pablo Piantanida
Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article provides theoretical guarantees by exploring the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. We then theoretically prove that in a non-linear regression setting with overfitting algorithms, attacks may have a high probability of success. Finally, we investigate several situations for which we provide bounds on this quantity of interest. Interestingly, our findings indicate that discretizing the data might enhance the algorithm's security. Specifically, it is demonstrated to be limited by a constant, which quantifies the diversity of the underlying data distribution. We illustrate those results through two simple simulations.
Read more6/12/2024
🤯
0
Membership Inference Attacks Against Time-Series Models
Noam Koren, Abigail Goldsteen, Guy Amit, Ariel Farkash
Analyzing time-series data that contains personal information, particularly in the medical field, presents serious privacy concerns. Sensitive health data from patients is often used to train machine learning models for diagnostics and ongoing care. Assessing the privacy risk of such models is crucial to making knowledgeable decisions on whether to use a model in production or share it with third parties. Membership Inference Attacks (MIA) are a key method for this kind of evaluation, however time-series prediction models have not been thoroughly studied in this context. We explore existing MIA techniques on time-series models, and introduce new features, focusing on the seasonality and trend components of the data. Seasonality is estimated using a multivariate Fourier transform, and a low-degree polynomial is used to approximate trends. We applied these techniques to various types of time-series models, using datasets from the health domain. Our results demonstrate that these new features enhance the effectiveness of MIAs in identifying membership, improving the understanding of privacy risks in medical data applications.
Read more9/24/2024
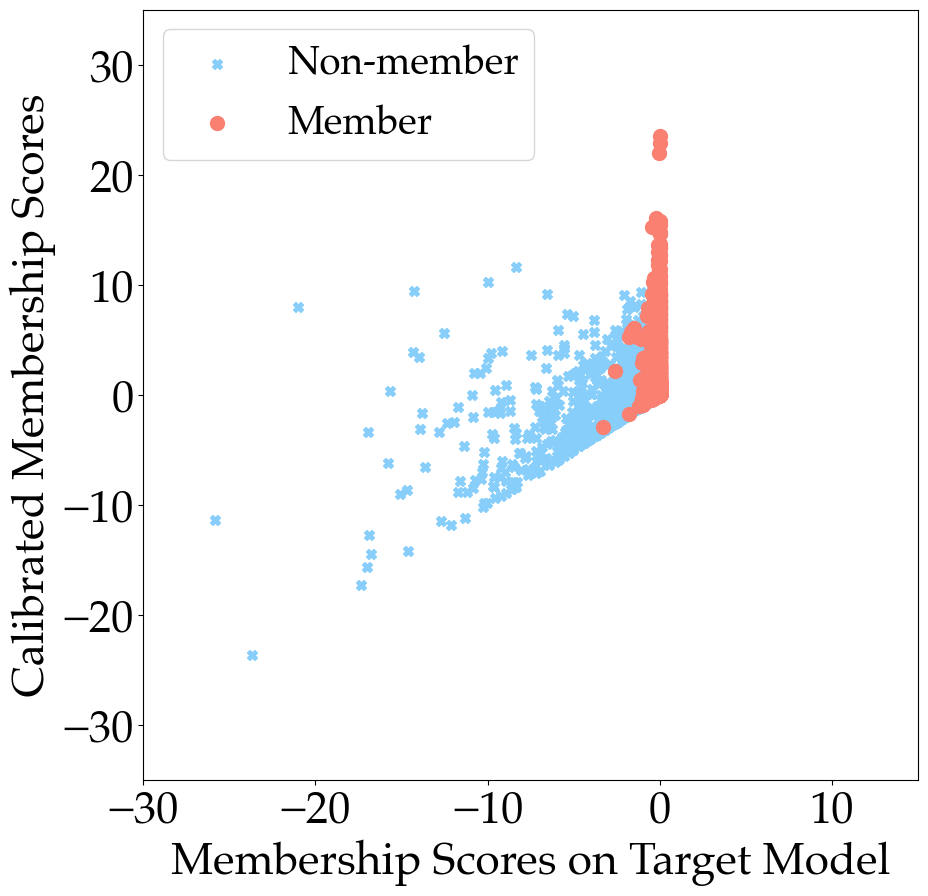
0
Learning-Based Difficulty Calibration for Enhanced Membership Inference Attacks
Haonan Shi, Tu Ouyang, An Wang
Machine learning models, in particular deep neural networks, are currently an integral part of various applications, from healthcare to finance. However, using sensitive data to train these models raises concerns about privacy and security. One method that has emerged to verify if the trained models are privacy-preserving is Membership Inference Attacks (MIA), which allows adversaries to determine whether a specific data point was part of a model's training dataset. While a series of MIAs have been proposed in the literature, only a few can achieve high True Positive Rates (TPR) in the low False Positive Rate (FPR) region (0.01%~1%). This is a crucial factor to consider for an MIA to be practically useful in real-world settings. In this paper, we present a novel approach to MIA that is aimed at significantly improving TPR at low FPRs. Our method, named learning-based difficulty calibration for MIA(LDC-MIA), characterizes data records by their hardness levels using a neural network classifier to determine membership. The experiment results show that LDC-MIA can improve TPR at low FPR by up to 4x compared to the other difficulty calibration based MIAs. It also has the highest Area Under ROC curve (AUC) across all datasets. Our method's cost is comparable with most of the existing MIAs, but is orders of magnitude more efficient than one of the state-of-the-art methods, LiRA, while achieving similar performance.
Read more7/10/2024