When Fuzzing Meets LLMs: Challenges and Opportunities
2404.16297
0
0
Abstract
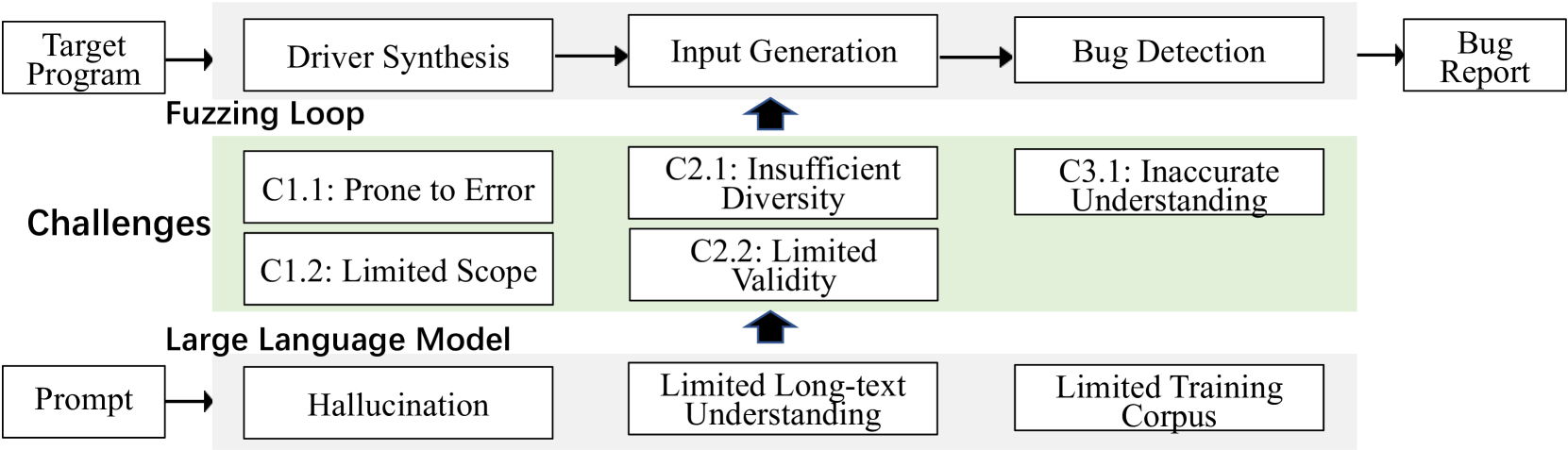
Fuzzing, a widely-used technique for bug detection, has seen advancements through Large Language Models (LLMs). Despite their potential, LLMs face specific challenges in fuzzing. In this paper, we identified five major challenges of LLM-assisted fuzzing. To support our findings, we revisited the most recent papers from top-tier conferences, confirming that these challenges are widespread. As a remedy, we propose some actionable recommendations to help improve applying LLM in Fuzzing and conduct preliminary evaluations on DBMS fuzzing. The results demonstrate that our recommendations effectively address the identified challenges.
Create account to get full access
Overview
- This paper explores the challenges and opportunities that arise when fuzzing (a software testing technique) is applied to large language models (LLMs).
- The authors discuss how fuzzing can be used to identify vulnerabilities in LLMs, but also highlight the unique challenges that come with testing these complex AI systems.
- The paper covers potential solutions and future research directions to address the issues at the intersection of fuzzing and LLMs.
Plain English Explanation
This paper looks at what happens when you try to test large language models using a technique called fuzzing. Fuzzing is a way to find bugs in software by feeding it random or unexpected inputs and seeing how it reacts.
The authors explain that while fuzzing can be helpful for finding vulnerabilities in LLMs, there are also some unique challenges. LLMs are very different from traditional software, so the usual fuzzing methods don't always work as well. For example, LLMs are trained on huge amounts of data and can generate their own text, which makes them harder to test in a systematic way.
The paper discusses potential solutions to these problems, such as using multi-role consensus through LLMs to help validate the outputs of the models. It also suggests areas for future research to better understand how to effectively apply fuzzing to these powerful AI systems.
Overall, the paper highlights the need to carefully consider the unique properties of LLMs when trying to test and secure them, rather than just applying existing software testing techniques.
Technical Explanation
The paper explores the challenges and opportunities that arise when applying fuzzing to large language models (LLMs). Fuzzing is a software testing technique that involves feeding unexpected or random inputs to a system to identify vulnerabilities.
The authors argue that while fuzzing can be a valuable tool for detecting vulnerabilities in LLMs, these AI systems pose unique challenges compared to traditional software. LLMs are trained on massive datasets and can generate their own text, making them more complex to test in a systematic way.
The paper discusses several key challenges, including:
- The difficulty of defining appropriate input/output spaces for fuzzing LLMs
- The challenge of detecting meaningful failures or vulnerabilities in the model's outputs
- The potential for adversarial attacks to exploit weaknesses in LLMs during the fuzzing process
To address these challenges, the authors propose potential solutions, such as:
- Using multi-role consensus through LLMs to validate model outputs
- Developing new fuzzing techniques tailored to the unique properties of LLMs
- Exploring the landscape of large language models to better understand their vulnerabilities
The paper also suggests areas for future research, including investigating the security implications of using LLMs for online advertisements and exploring how large language models can be used as research assistants to aid in the fuzzing process.
Critical Analysis
The paper raises important concerns about the challenges of applying traditional software testing techniques, such as fuzzing, to large language models. The authors rightly point out the unique properties of LLMs, which make them more complex and difficult to test in a systematic way.
One potential limitation of the research is that it focuses primarily on the technical challenges of fuzzing LLMs, without delving too deeply into the broader implications or societal impact of these issues. For example, the paper does not discuss the potential risks or consequences of vulnerabilities in LLMs being exploited, such as the spread of misinformation or the misuse of these powerful AI systems.
Additionally, while the paper proposes some potential solutions, such as using multi-role consensus and developing new fuzzing techniques, it does not provide a comprehensive or detailed roadmap for addressing these challenges. Further research and experimentation may be needed to fully understand the efficacy and practicality of the suggested approaches.
Overall, the paper makes a valuable contribution to the literature on large language model vulnerability detection and repair, but there may be room for the authors to expand the scope and depth of their analysis in future work.
Conclusion
This paper highlights the unique challenges that arise when applying traditional software testing techniques, such as fuzzing, to large language models. While fuzzing can be a valuable tool for identifying vulnerabilities in LLMs, the authors demonstrate that these AI systems pose unique challenges that require new approaches and further research.
The paper's discussion of potential solutions and future research directions provides a useful framework for addressing these issues. By exploring the landscape of large language models and developing more tailored testing methods, researchers and practitioners may be able to better secure these powerful AI systems and mitigate the risks they pose.
Overall, this paper serves as an important contribution to the ongoing efforts to understand and address the security implications of large language models, paving the way for more robust and trustworthy AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing
Hongxiang Zhang, Yuyang Rong, Yifeng He, Hao Chen
0
0
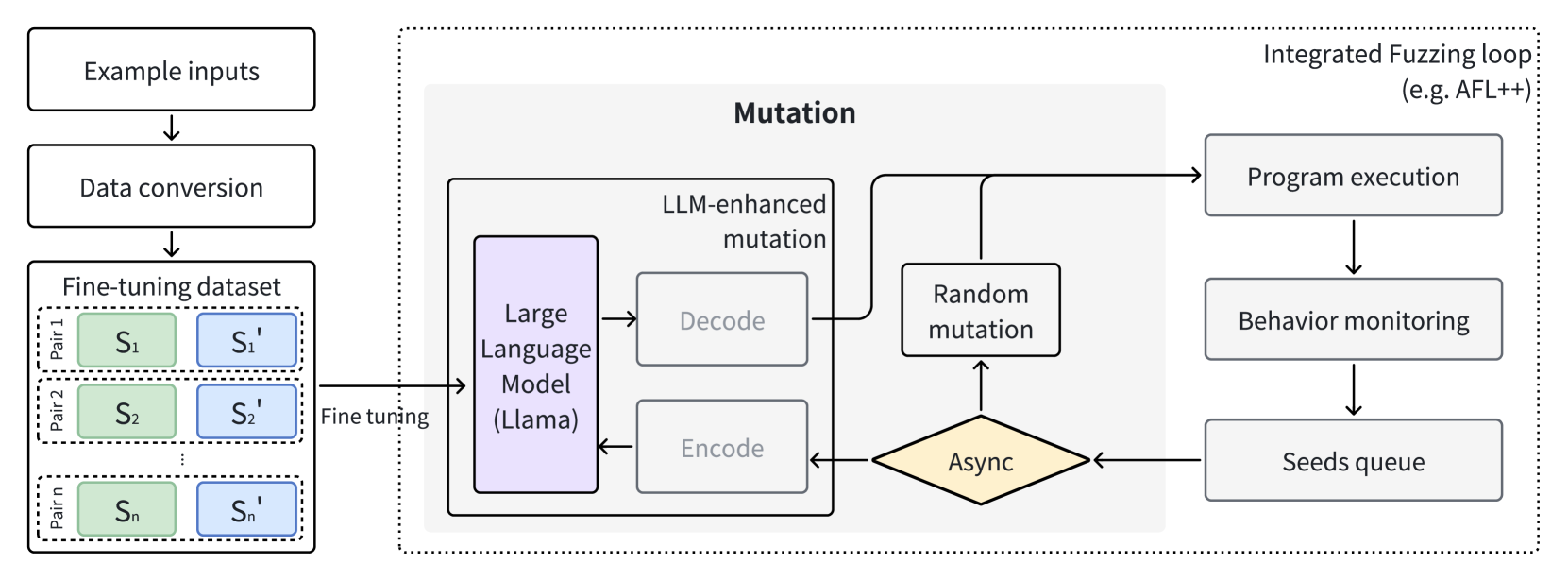
Greybox fuzzing has achieved success in revealing bugs and vulnerabilities in programs. However, randomized mutation strategies have limited the fuzzer's performance on structured data. Specialized fuzzers can handle complex structured data, but require additional efforts in grammar and suffer from low throughput. In this paper, we explore the potential of utilizing the Large Language Model to enhance greybox fuzzing for structured data. We utilize the pre-trained knowledge of LLM about data conversion and format to generate new valid inputs. We further fine-tuned it with paired mutation seeds to learn structured format and mutation strategies effectively. Our LLM-based fuzzer, LLAMAFUZZ, integrates the power of LLM to understand and mutate structured data to fuzzing. We conduct experiments on the standard bug-based benchmark Magma and a wide variety of real-world programs. LLAMAFUZZ outperforms our top competitor by 41 bugs on average. We also identified 47 unique bugs across all trials. Moreover, LLAMAFUZZ demonstrated consistent performance on both bug trigger and bug reached. Compared to AFL++, LLAMAFUZZ achieved 27.19% more branches in real-world program sets on average. We also demonstrate a case study to explain how LLMs enhance the fuzzing process in terms of code coverage.
6/17/2024
💬
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
0
0
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
5/27/2024

MedFuzz: Exploring the Robustness of Large Language Models in Medical Question Answering
Robert Osazuwa Ness, Katie Matton, Hayden Helm, Sheng Zhang, Junaid Bajwa, Carey E. Priebe, Eric Horvitz
0
0
Large language models (LLM) have achieved impressive performance on medical question-answering benchmarks. However, high benchmark accuracy does not imply that the performance generalizes to real-world clinical settings. Medical question-answering benchmarks rely on assumptions consistent with quantifying LLM performance but that may not hold in the open world of the clinic. Yet LLMs learn broad knowledge that can help the LLM generalize to practical conditions regardless of unrealistic assumptions in celebrated benchmarks. We seek to quantify how well LLM medical question-answering benchmark performance generalizes when benchmark assumptions are violated. Specifically, we present an adversarial method that we call MedFuzz (for medical fuzzing). MedFuzz attempts to modify benchmark questions in ways aimed at confounding the LLM. We demonstrate the approach by targeting strong assumptions about patient characteristics presented in the MedQA benchmark. Successful attacks modify a benchmark item in ways that would be unlikely to fool a medical expert but nonetheless trick the LLM into changing from a correct to an incorrect answer. Further, we present a permutation test technique that can ensure a successful attack is statistically significant. We show how to use performance on a MedFuzzed benchmark, as well as individual successful attacks. The methods show promise at providing insights into the ability of an LLM to operate robustly in more realistic settings.
6/12/2024
Large Language Models for Cyber Security: A Systematic Literature Review
HanXiang Xu, ShenAo Wang, NingKe Li, KaiLong Wang, YanJie Zhao, Kai Chen, Ting Yu, Yang Liu, HaoYu Wang
0
0
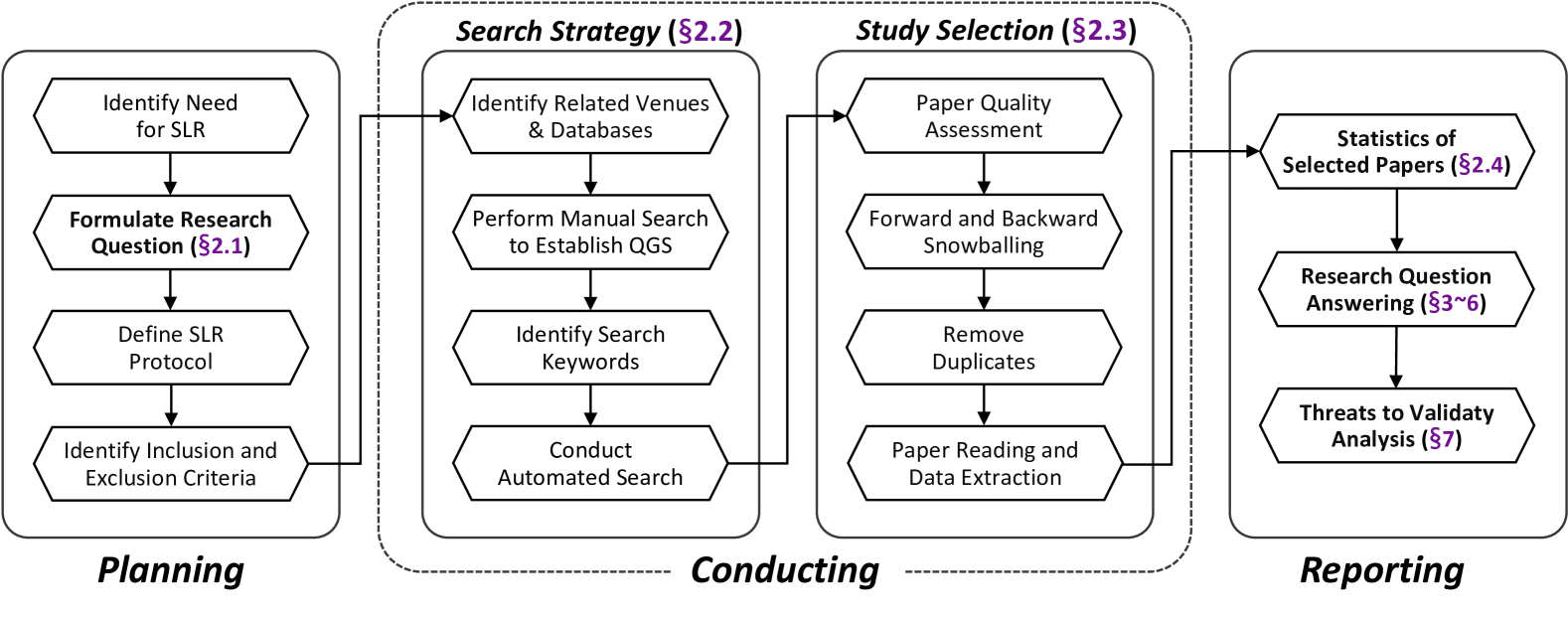
The rapid advancement of Large Language Models (LLMs) has opened up new opportunities for leveraging artificial intelligence in various domains, including cybersecurity. As the volume and sophistication of cyber threats continue to grow, there is an increasing need for intelligent systems that can automatically detect vulnerabilities, analyze malware, and respond to attacks. In this survey, we conduct a comprehensive review of the literature on the application of LLMs in cybersecurity (LLM4Security). By comprehensively collecting over 30K relevant papers and systematically analyzing 127 papers from top security and software engineering venues, we aim to provide a holistic view of how LLMs are being used to solve diverse problems across the cybersecurity domain. Through our analysis, we identify several key findings. First, we observe that LLMs are being applied to a wide range of cybersecurity tasks, including vulnerability detection, malware analysis, network intrusion detection, and phishing detection. Second, we find that the datasets used for training and evaluating LLMs in these tasks are often limited in size and diversity, highlighting the need for more comprehensive and representative datasets. Third, we identify several promising techniques for adapting LLMs to specific cybersecurity domains, such as fine-tuning, transfer learning, and domain-specific pre-training. Finally, we discuss the main challenges and opportunities for future research in LLM4Security, including the need for more interpretable and explainable models, the importance of addressing data privacy and security concerns, and the potential for leveraging LLMs for proactive defense and threat hunting. Overall, our survey provides a comprehensive overview of the current state-of-the-art in LLM4Security and identifies several promising directions for future research.
5/10/2024