When is the consistent prediction likely to be a correct prediction?

0

Sign in to get full access
Overview
- This paper investigates when the consistent prediction of a machine learning model is likely to be correct.
- The authors conduct experiments to understand the relationship between model consistency and accuracy.
- They explore factors that can influence whether a consistent prediction is a good predictor of the true label.
Plain English Explanation
The paper looks at when a machine learning model's consistent predictions are likely to be right. Often, models will make the same prediction multiple times for a given input. The researchers wanted to understand if these consistent predictions are usually correct, or if they can sometimes be wrong.
To investigate this, the authors designed a series of experiments. They tested different machine learning models on various datasets to see how the models' consistency relates to their accuracy. The goal was to identify the conditions where a consistent prediction is a good signal that the prediction is actually correct.
This research builds on previous work that has examined the reasoning and consistency capabilities of large language models. By focusing on the relationship between consistency and accuracy, the authors hope to provide insights into when we can trust a model's confident, repeated predictions.
Technical Explanation
The paper first describes the experimental setup used to test model consistency and accuracy. The authors evaluated several different machine learning models, including neural networks and decision trees, on a range of classification tasks. For each input, the models were asked to make multiple predictions, and the researchers tracked how often the models made the same prediction repeatedly (consistency) and how often those consistent predictions matched the true label (accuracy).
The experiments were designed to test factors that could influence the link between consistency and accuracy, such as dataset difficulty, model complexity, and training data size. The results showed that in some cases, consistent predictions were highly accurate, indicating that the model was quite confident and reliable. However, in other situations, consistent predictions could still be incorrect, suggesting that consistency alone is not a guaranteed signal of accuracy.
The authors analyzed the findings to identify the key conditions that determined when consistent predictions were likely to be correct. For example, they found that easier datasets, more complex models, and larger training sets tend to produce more reliable consistent predictions. The paper discusses the implications of these insights for deploying machine learning models in real-world applications.
Critical Analysis
The paper provides a nuanced look at the relationship between model consistency and accuracy, highlighting that there is no simple one-to-one mapping between the two. The experimental approach is well-designed and the results offer valuable insights.
However, the paper does not explore all possible factors that could influence the consistency-accuracy relationship. For example, it does not consider how the specific task, data distribution, or model architecture might play a role. Additionally, the experiments were conducted on a limited set of models and datasets, so the findings may not generalize to all machine learning scenarios.
It would also be interesting to see further research on whether large language models can self-correct when their consistent predictions are incorrect. This could help improve the reliability of these models in real-world applications where consistency is important.
Overall, this paper makes a valuable contribution by highlighting the nuances involved in interpreting a model's consistent predictions. Readers should keep these caveats in mind when applying the insights to their own machine learning projects.
Conclusion
This paper investigates the conditions under which a machine learning model's consistent predictions are likely to be accurate. Through a series of carefully designed experiments, the authors found that factors like dataset difficulty, model complexity, and training data size can all influence the relationship between consistency and accuracy.
The key takeaway is that while consistent predictions can be a useful signal of a model's confidence and reliability, they do not guarantee correctness. Practitioners need to carefully consider the context and characteristics of their specific machine learning problem to determine how much weight to place on a model's consistent outputs.
These insights have important implications for deploying machine learning systems in real-world applications, where the ability to trust a model's predictions is crucial. The paper serves as a valuable resource for researchers and practitioners alike as they work to build more reliable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
When is the consistent prediction likely to be a correct prediction?
Alex Nguyen, Dheeraj Mekala, Chengyu Dong, Jingbo Shang
Self-consistency (Wang et al., 2023) suggests that the most consistent answer obtained through large language models (LLMs) is more likely to be correct. In this paper, we challenge this argument and propose a nuanced correction. Our observations indicate that consistent answers derived through more computation i.e. longer reasoning texts, rather than simply the most consistent answer across all outputs, are more likely to be correct. This is predominantly because we demonstrate that LLMs can autonomously produce chain-of-thought (CoT) style reasoning with no custom prompts merely while generating longer responses, which lead to consistent predictions that are more accurate. In the zero-shot setting, by sampling Mixtral-8x7B model multiple times and considering longer responses, we achieve 86% of its self-consistency performance obtained through zero-shot CoT prompting on the GSM8K and MultiArith datasets. Finally, we demonstrate that the probability of LLMs generating a longer response is quite low, highlighting the need for decoding strategies conditioned on output length.
Read more7/9/2024

0
Can Large Language Models Always Solve Easy Problems if They Can Solve Harder Ones?
Zhe Yang, Yichang Zhang, Tianyu Liu, Jian Yang, Junyang Lin, Chang Zhou, Zhifang Sui
Large language models (LLMs) have demonstrated impressive capabilities, but still suffer from inconsistency issues (e.g. LLMs can react differently to disturbances like rephrasing or inconsequential order change). In addition to these inconsistencies, we also observe that LLMs, while capable of solving hard problems, can paradoxically fail at easier ones. To evaluate this hard-to-easy inconsistency, we develop the ConsisEval benchmark, where each entry comprises a pair of questions with a strict order of difficulty. Furthermore, we introduce the concept of consistency score to quantitatively measure this inconsistency and analyze the potential for improvement in consistency by relative consistency score. Based on comprehensive experiments across a variety of existing models, we find: (1) GPT-4 achieves the highest consistency score of 92.2% but is still inconsistent to specific questions due to distraction by redundant information, misinterpretation of questions, etc.; (2) models with stronger capabilities typically exhibit higher consistency, but exceptions also exist; (3) hard data enhances consistency for both fine-tuning and in-context learning. Our data and code will be publicly available on GitHub.
Read more6/19/2024
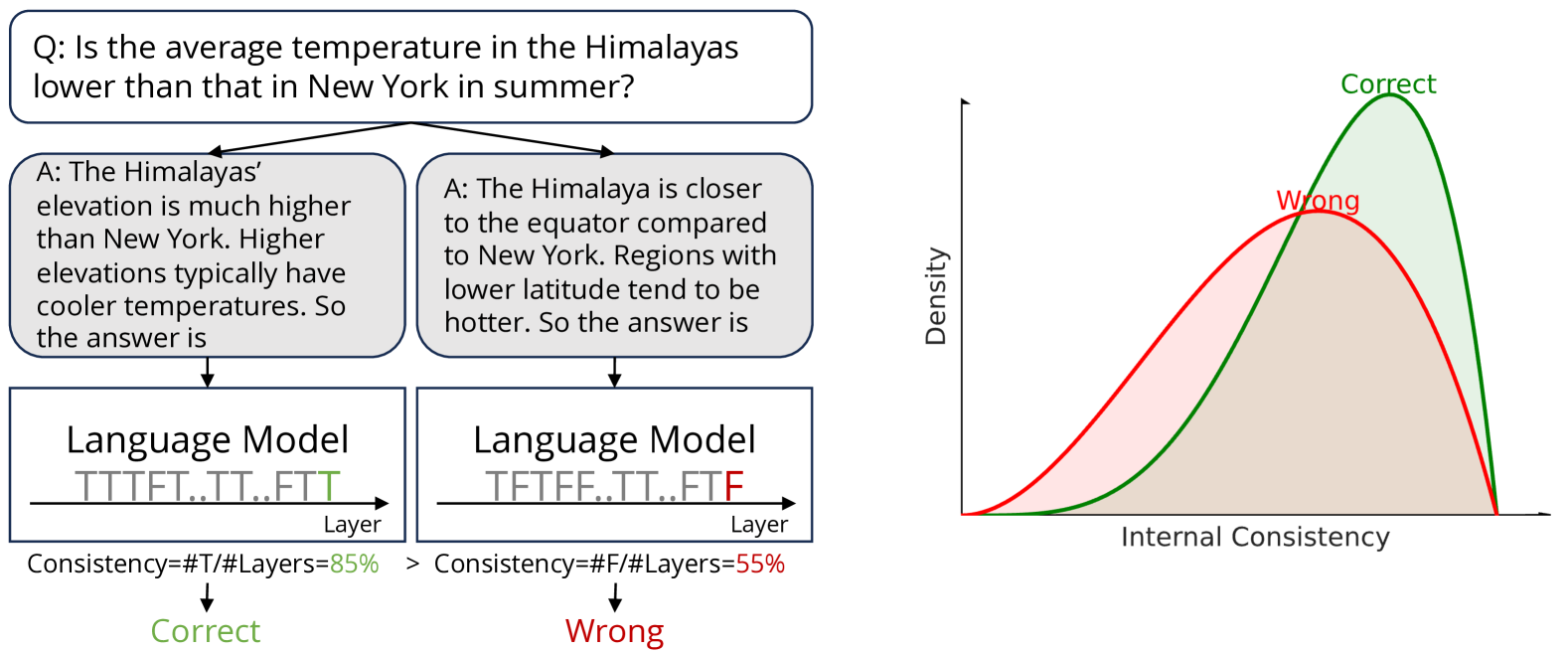
0
Calibrating Reasoning in Language Models with Internal Consistency
Zhihui Xie, Jizhou Guo, Tong Yu, Shuai Li
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks, aided by techniques like chain-of-thought (CoT) prompting that elicits verbalized reasoning. However, LLMs often generate text with obvious mistakes and contradictions, raising doubts about their ability to robustly process and utilize generated rationales. In this work, we investigate CoT reasoning in LLMs through the lens of internal representations, focusing on how these representations are influenced by generated rationales. Our preliminary analysis reveals that while generated rationales improve answer accuracy, inconsistencies emerge between the model's internal representations in middle layers and those in final layers, potentially undermining the reliability of their reasoning processes. To address this, we propose internal consistency as a measure of the model's confidence by examining the agreement of latent predictions decoded from intermediate layers. Extensive empirical studies across different models and datasets demonstrate that internal consistency effectively distinguishes between correct and incorrect reasoning paths. Motivated by this, we propose a new approach to calibrate CoT reasoning by up-weighting reasoning paths with high internal consistency, resulting in a significant boost in reasoning performance. Further analysis uncovers distinct patterns in attention and feed-forward modules across layers, providing insights into the emergence of internal inconsistency. In summary, our results demonstrate the potential of using internal representations for self-evaluation of LLMs.
Read more5/30/2024
💬
0
Evaluating Consistency and Reasoning Capabilities of Large Language Models
Yash Saxena, Sarthak Chopra, Arunendra Mani Tripathi
Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
Read more4/26/2024