Why Online Reinforcement Learning is Causal

0

Sign in to get full access
Overview
- The paper discusses how online reinforcement learning is inherently causal in nature, as the agent's actions affect the environment and the subsequent observations.
- It explores the role of causal probabilities in reinforcement learning and how they differ from traditional conditional probabilities.
- The paper argues that understanding the causal relationships between actions, states, and rewards is essential for effective reinforcement learning in dynamic environments.
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent (like a robot or computer program) learns to make decisions by interacting with its environment and receiving rewards or punishments. In traditional reinforcement learning, the agent tries to maximize the rewards it receives based on the observed outcomes of its actions.
However, the paper suggests that this approach is missing something important. In the real world, our actions don't just lead to certain outcomes - they actually
The paper argues that to truly understand and improve reinforcement learning, we need to focus on these causal relationships. We need to understand how the agent's actions
By incorporating this causal understanding, the agent can learn more effectively and make better decisions. It can explore the environment in a more targeted way, anticipate the consequences of its actions, and even reason about hypothetical scenarios that haven't occurred yet.
The paper suggests that this causal perspective is especially important in "online" reinforcement learning, where the agent is learning and acting in a dynamic, real-world environment. In these settings, the causal relationships between actions, states, and rewards are constantly shifting, and the agent needs to adapt accordingly.
Overall, the key idea is that reinforcement learning is fundamentally a causal process, and that explicitly incorporating this causal understanding can lead to more effective and robust learning algorithms.
Technical Explanation
The paper argues that online reinforcement learning is inherently a causal process, as the agent's actions affect the environment and the subsequent observations. This is in contrast to traditional conditional probability-based approaches, which do not explicitly model the causal relationships between actions, states, and rewards.
The authors introduce the concept of "causal probabilities" to capture these causal dependencies. Causal probabilities describe the probability of an outcome
The paper presents a theoretical framework for incorporating causal probabilities into reinforcement learning algorithms. This involves modeling the environment as a causal dynamical system, where the agent's actions influence the subsequent states and rewards. The authors show how this causal perspective can lead to improved exploration, credit assignment, and generalization capabilities compared to traditional approaches.
The paper also discusses the challenges of learning causal models in complex, partially observable environments. It suggests that leveraging causal representations and structured exploration techniques can help mitigate these challenges and lead to more robust and sample-efficient reinforcement learning.
Critical Analysis
The paper makes a compelling case for the importance of causal reasoning in reinforcement learning, particularly in online settings where the environment is dynamic and unpredictable. The authors' focus on causal probabilities and causal models is a valuable contribution to the field, as it highlights the limitations of purely statistical approaches and the need for a deeper understanding of the underlying causal mechanisms.
However, the paper does not address several practical challenges that may arise when implementing causal reinforcement learning algorithms. For example, how do we effectively learn causal models from limited data, especially in high-dimensional or partially observable environments? What are the computational and memory requirements of these causal reasoning approaches, and how do they scale to real-world problems?
Additionally, the paper does not delve into the implications of causal reinforcement learning for issues like safety, robustness, and transparency. As these algorithms become more sophisticated, it will be important to consider how causal reasoning affects the system's behavior, particularly in safety-critical applications.
Overall, the paper provides a strong theoretical foundation for causal reinforcement learning, but more research is needed to address the practical challenges and broader implications of this approach. As the field continues to evolve, papers on causal prompting for model-based offline reinforcement learning, preference elicitation for offline reinforcement learning, out-distribution adaptation for offline RL and counterfactual reasoning, identifiable causal representation learning, and hybrid reinforcement learning from offline observation alone will be important to consider.
Conclusion
The paper demonstrates that online reinforcement learning is fundamentally a causal process, where the agent's actions directly influence the environment and the subsequent observations and rewards. By incorporating this causal understanding into reinforcement learning algorithms, the authors argue that agents can learn more effectively, explore the environment more strategically, and reason about hypothetical scenarios.
This causal perspective represents a valuable shift in the way we approach reinforcement learning, moving beyond the traditional focus on conditional probabilities and towards a deeper understanding of the underlying causal mechanisms. While further research is needed to address the practical challenges of implementing causal reinforcement learning, this paper lays an important foundation for the field and highlights the potential benefits of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Why Online Reinforcement Learning is Causal
Oliver Schulte, Pascal Poupart
Reinforcement learning (RL) and causal modelling naturally complement each other. The goal of causal modelling is to predict the effects of interventions in an environment, while the goal of reinforcement learning is to select interventions that maximize the rewards the agent receives from the environment. Reinforcement learning includes the two most powerful sources of information for estimating causal relationships: temporal ordering and the ability to act on an environment. This paper examines which reinforcement learning settings we can expect to benefit from causal modelling, and how. In online learning, the agent has the ability to interact directly with their environment, and learn from exploring it. Our main argument is that in online learning, conditional probabilities are causal, and therefore offline RL is the setting where causal learning has the most potential to make a difference. Essentially, the reason is that when an agent learns from their {em own} experience, there are no unobserved confounders that influence both the agent's own exploratory actions and the rewards they receive. Our paper formalizes this argument. For offline RL, where an agent may and typically does learn from the experience of {em others}, we describe previous and new methods for leveraging a causal model, including support for counterfactual queries.
Read more7/12/2024
0
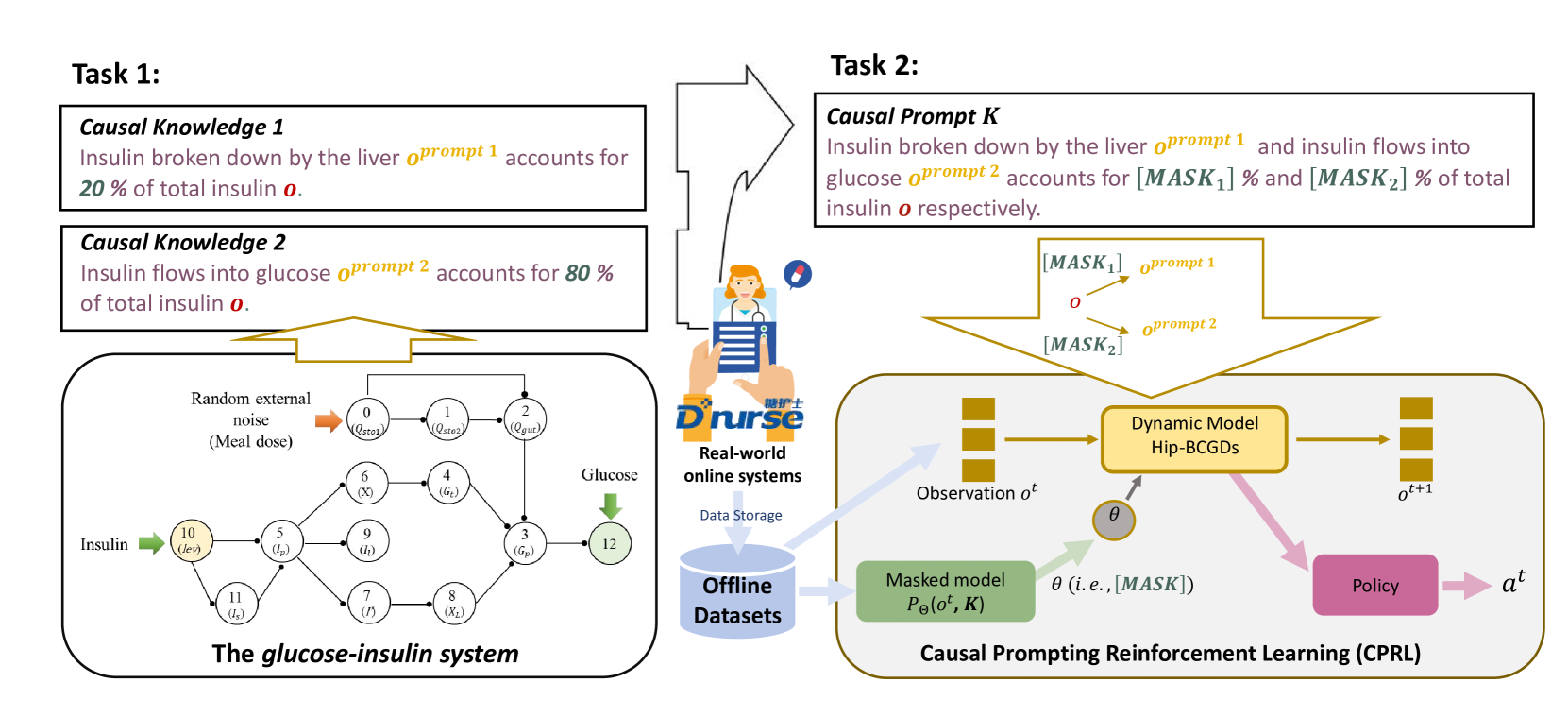
Causal prompting model-based offline reinforcement learning
Xuehui Yu, Yi Guan, Rujia Shen, Xin Li, Chen Tang, Jingchi Jiang
Model-based offline Reinforcement Learning (RL) allows agents to fully utilise pre-collected datasets without requiring additional or unethical explorations. However, applying model-based offline RL to online systems presents challenges, primarily due to the highly suboptimal (noise-filled) and diverse nature of datasets generated by online systems. To tackle these issues, we introduce the Causal Prompting Reinforcement Learning (CPRL) framework, designed for highly suboptimal and resource-constrained online scenarios. The initial phase of CPRL involves the introduction of the Hidden-Parameter Block Causal Prompting Dynamic (Hip-BCPD) to model environmental dynamics. This approach utilises invariant causal prompts and aligns hidden parameters to generalise to new and diverse online users. In the subsequent phase, a single policy is trained to address multiple tasks through the amalgamation of reusable skills, circumventing the need for training from scratch. Experiments conducted across datasets with varying levels of noise, including simulation-based and real-world offline datasets from the Dnurse APP, demonstrate that our proposed method can make robust decisions in out-of-distribution and noisy environments, outperforming contemporary algorithms. Additionally, we separately verify the contributions of Hip-BCPDs and the skill-reuse strategy to the robustness of performance. We further analyse the visualised structure of Hip-BCPD and the interpretability of sub-skills. We released our source code and the first ever real-world medical dataset for precise medical decision-making tasks.
Read more6/4/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024

0
Offline Reinforcement Learning with Imputed Rewards
Carlo Romeo, Andrew D. Bagdanov
Offline Reinforcement Learning (ORL) offers a robust solution to training agents in applications where interactions with the environment must be strictly limited due to cost, safety, or lack of accurate simulation environments. Despite its potential to facilitate deployment of artificial agents in the real world, Offline Reinforcement Learning typically requires very many demonstrations annotated with ground-truth rewards. Consequently, state-of-the-art ORL algorithms can be difficult or impossible to apply in data-scarce scenarios. In this paper we propose a simple but effective Reward Model that can estimate the reward signal from a very limited sample of environment transitions annotated with rewards. Once the reward signal is modeled, we use the Reward Model to impute rewards for a large sample of reward-free transitions, thus enabling the application of ORL techniques. We demonstrate the potential of our approach on several D4RL continuous locomotion tasks. Our results show that, using only 1% of reward-labeled transitions from the original datasets, our learned reward model is able to impute rewards for the remaining 99% of the transitions, from which performant agents can be learned using Offline Reinforcement Learning.
Read more7/16/2024