Zero-Shot Generalization during Instruction Tuning: Insights from Similarity and Granularity

0
Sign in to get full access
Overview
- This paper explores the phenomenon of zero-shot generalization during instruction tuning, which is the process of training language models to follow instructions and perform various tasks.
- The researchers investigate how the similarity and granularity of instructions impact a language model's ability to generalize to new, unseen instructions.
- They present insights into the factors that contribute to successful zero-shot generalization, which can have important implications for the development of more capable and versatile language models.
Plain English Explanation
The paper focuses on a technique called "instruction tuning," which is a way of training language models to follow instructions and perform different tasks. The researchers wanted to understand how well these models can generalize, or apply what they've learned, to new instructions they haven't seen before (called "zero-shot generalization").
To do this, the researchers looked at two key factors: similarity and granularity of the instructions. Similarity refers to how related the new instructions are to the ones the model was trained on, while granularity refers to how specific or detailed the instructions are.
The researchers found that when the new instructions were similar to the ones the model was trained on, and when the instructions were more detailed and specific, the model was better able to generalize and apply what it had learned to the new instructions. This provides important insights into the factors that contribute to successful zero-shot generalization, which could help developers create more capable and versatile language models in the future.
Technical Explanation
The paper investigates the phenomenon of zero-shot generalization during instruction tuning, which is the process of training language models to follow instructions and perform various tasks. The researchers explore how the similarity and granularity of instructions impact a language model's ability to generalize to new, unseen instructions.
In their experiments, the researchers trained a language model on a set of instructions and then evaluated its performance on a separate set of novel instructions. They manipulated the similarity of the new instructions to the training instructions, as well as the level of granularity (specificity) of the instructions.
The results showed that when the new instructions were more similar to the training instructions, and when the instructions were more detailed and specific, the language model was better able to generalize and apply what it had learned to the new instructions. This suggests that both the relatedness of the instructions and their level of granularity are important factors in determining the success of zero-shot generalization during instruction tuning.
Critical Analysis
The paper provides valuable insights into the factors that contribute to successful zero-shot generalization during instruction tuning. However, the researchers acknowledge that their study is limited to a specific set of instructions and tasks, and that further research is needed to explore the generalizability of their findings.
Additionally, the paper does not address the potential biases that may be introduced during the instruction tuning process, or the potential for language models to exhibit inconsistent or unpredictable behavior when faced with novel instructions. These are important considerations that future research should explore.
Overall, the paper makes a valuable contribution to our understanding of zero-shot generalization in the context of instruction tuning, but more work is needed to fully understand the limitations and potential pitfalls of this approach.
Conclusion
This paper provides important insights into the factors that influence a language model's ability to generalize to new instructions during the process of instruction tuning. The researchers found that both the similarity of the new instructions to the training instructions, as well as the level of granularity or specificity of the instructions, play a key role in determining the success of zero-shot generalization.
These findings have significant implications for the development of more capable and versatile language models, which are increasingly being applied to a wide range of real-world tasks and applications. By understanding the factors that contribute to successful zero-shot generalization, researchers and developers can work to create language models that are more robust, flexible, and adaptable to new and unfamiliar situations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero-Shot Generalization during Instruction Tuning: Insights from Similarity and Granularity
Bingxiang He, Ning Ding, Cheng Qian, Jia Deng, Ganqu Cui, Lifan Yuan, Huan-ang Gao, Huimin Chen, Zhiyuan Liu, Maosong Sun
Understanding alignment techniques begins with comprehending zero-shot generalization brought by instruction tuning, but little of the mechanism has been understood. Existing work has largely been confined to the task level, without considering that tasks are artificially defined and, to LLMs, merely consist of tokens and representations. This line of research has been limited to examining transfer between tasks from a task-pair perspective, with few studies focusing on understanding zero-shot generalization from the perspective of the data itself. To bridge this gap, we first demonstrate through multiple metrics that zero-shot generalization during instruction tuning happens very early. Next, we investigate the facilitation of zero-shot generalization from both data similarity and granularity perspectives, confirming that encountering highly similar and fine-grained training data earlier during instruction tuning, without the constraints of defined tasks, enables better generalization. Finally, we propose a more grounded training data arrangement method, Test-centric Multi-turn Arrangement, and show its effectiveness in promoting continual learning and further loss reduction. For the first time, we show that zero-shot generalization during instruction tuning is a form of similarity-based generalization between training and test data at the instance level. We hope our analysis will advance the understanding of zero-shot generalization during instruction tuning and contribute to the development of more aligned LLMs. Our code is released at https://github.com/HBX-hbx/dynamics_of_zero-shot_generalization.
Read more6/18/2024

0
Deep Exploration of Cross-Lingual Zero-Shot Generalization in Instruction Tuning
Janghoon Han, Changho Lee, Joongbo Shin, Stanley Jungkyu Choi, Honglak Lee, Kynghoon Bae
Instruction tuning has emerged as a powerful technique, significantly boosting zero-shot performance on unseen tasks. While recent work has explored cross-lingual generalization by applying instruction tuning to multilingual models, previous studies have primarily focused on English, with a limited exploration of non-English tasks. For an in-depth exploration of cross-lingual generalization in instruction tuning, we perform instruction tuning individually for two distinct language meta-datasets. Subsequently, we assess the performance on unseen tasks in a language different from the one used for training. To facilitate this investigation, we introduce a novel non-English meta-dataset named KORANI (Korean Natural Instruction), comprising 51 Korean benchmarks. Moreover, we design cross-lingual templates to mitigate discrepancies in language and instruction-format of the template between training and inference within the cross-lingual setting. Our experiments reveal consistent improvements through cross-lingual generalization in both English and Korean, outperforming baseline by average scores of 20.7% and 13.6%, respectively. Remarkably, these enhancements are comparable to those achieved by monolingual instruction tuning and even surpass them in some tasks. The result underscores the significance of relevant data acquisition across languages over linguistic congruence with unseen tasks during instruction tuning.
Read more6/14/2024

0
Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
Read more6/7/2024
0
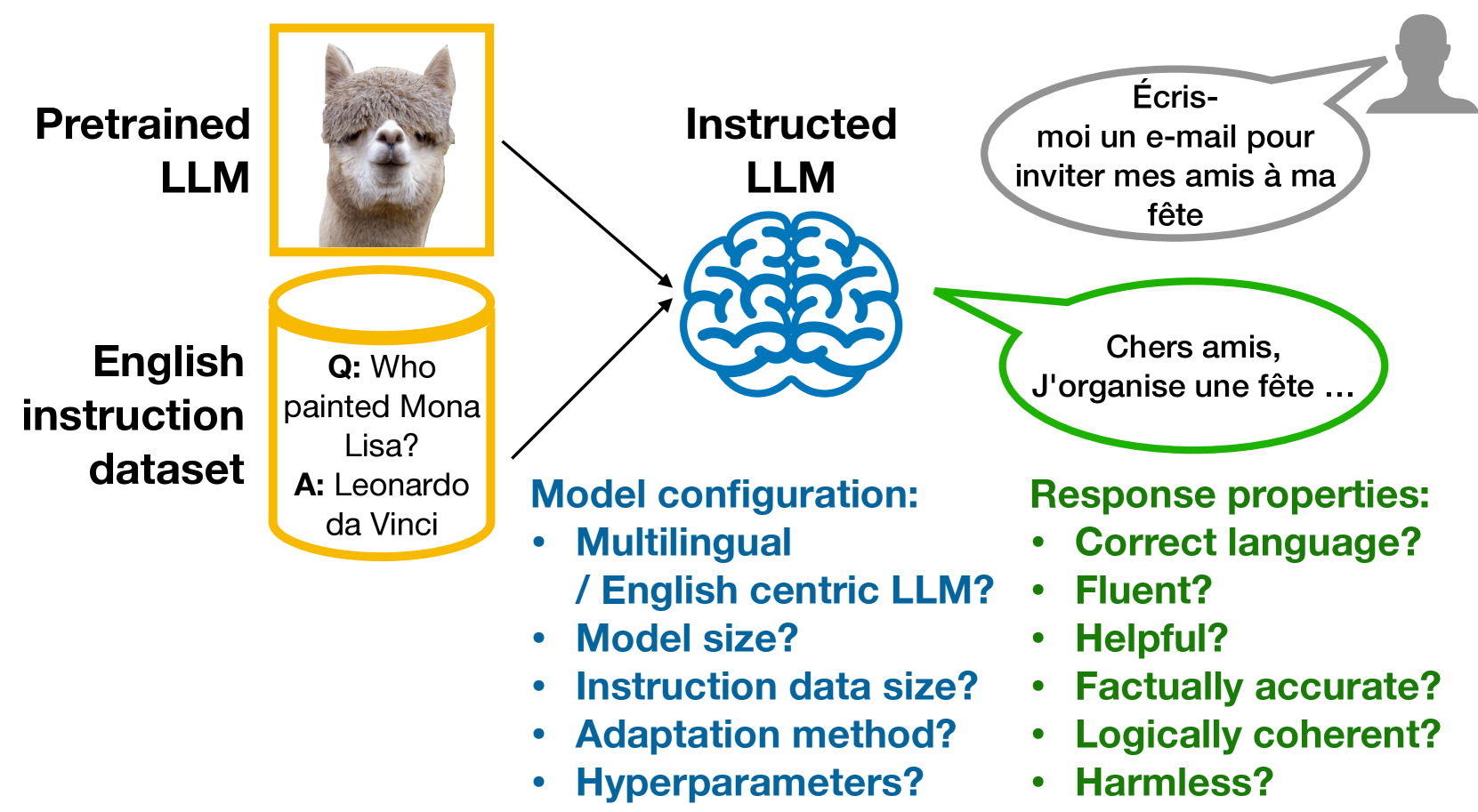
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
Read more4/23/2024