Anotherjesse
Models by this creator

dreambooth-batch

1.0K
dreambooth-batch is a batch inference model for Stable Diffusion's DreamBooth training process, developed by Replicate. It is based on the cog-stable-diffusion model, which utilizes the Diffusers library. This model allows for efficient batch generation of images based on DreamBooth-trained models, enabling users to quickly create personalized content. Model inputs and outputs The dreambooth-batch model takes two key inputs: a set of images and a URL pointing to the trained DreamBooth model weights. The images are used to generate new content based on the DreamBooth model, while the weights file provides the necessary information for the model to perform the image generation. Inputs Images**: A JSON input containing the images to be used for generation Weights**: A URL pointing to the trained DreamBooth model weights Outputs Output Images**: An array of generated image URLs Capabilities The dreambooth-batch model excels at generating personalized content based on DreamBooth-trained models. It allows users to quickly create images of their own concepts or characters, leveraging the capabilities of Stable Diffusion's text-to-image generation. What can I use it for? The dreambooth-batch model can be used to generate custom content for a variety of applications, such as: Creating personalized illustrations, avatars, or characters for games, apps, or websites Generating images for marketing, advertising, or social media campaigns Producing unique stock imagery or visual assets for commercial use By using the DreamBooth training process and the efficient batch inference capabilities of dreambooth-batch, users can easily create high-quality, personalized content that aligns with their specific needs or brand. Things to try One key feature of the dreambooth-batch model is its ability to handle batch processing of images. This can be particularly useful for users who need to generate large volumes of content quickly, such as for animation or video production. Additionally, the model's integration with the Diffusers library allows for seamless integration with other Stable Diffusion-based models, such as Real-ESRGAN for image upscaling and enhancement.
Updated 9/19/2024

zeroscope-v2-xl
276
The zeroscope-v2-xl is a text-to-video AI model developed by anotherjesse. It is a Cog implementation that leverages the zeroscope_v2_XL and zeroscope_v2_576w models from HuggingFace to generate high-quality videos from text prompts. This model is an extension of the original cog-text2video implementation, incorporating contributions from various researchers and developers in the text-to-video synthesis field. Model inputs and outputs The zeroscope-v2-xl model accepts a text prompt as input and generates a series of video frames as output. Users can customize various parameters such as the video resolution, frame rate, number of inference steps, and more to fine-tune the output. The model also supports the use of an initial video as a starting point for the generation process. Inputs Prompt**: The text prompt describing the desired video content. Negative Prompt**: An optional text prompt to exclude certain elements from the generated video. Init Video**: An optional URL of an initial video to use as a starting point for the generation. Num Frames**: The number of frames to generate for the output video. Width* and *Height**: The resolution of the output video. Fps**: The frames per second of the output video. Seed**: An optional random seed to ensure reproducibility. Batch Size**: The number of video clips to generate simultaneously. Guidance Scale**: The strength of the text guidance during the generation process. Num Inference Steps**: The number of denoising steps to perform during the generation. Remove Watermark**: An option to remove any watermarks from the generated video. Outputs The model outputs a series of video frames, which can be exported as a video file. Capabilities The zeroscope-v2-xl model is capable of generating high-quality videos from text prompts, with the ability to leverage an initial video as a starting point. The model can produce videos with smooth, consistent frames and realistic visual elements. By incorporating the zeroscope_v2_576w model, the zeroscope-v2-xl is optimized for producing high-quality 16:9 compositions and smooth video outputs. What can I use it for? The zeroscope-v2-xl model can be used for a variety of creative and practical applications, such as: Generating short videos for social media or advertising purposes. Prototyping and visualizing ideas before producing a more polished video. Enhancing existing videos by generating new content to blend with the original footage. Exploring the potential of text-to-video synthesis for various industries, such as entertainment, education, or marketing. Things to try One interesting thing to try with the zeroscope-v2-xl model is to experiment with the use of an initial video as a starting point for the generation process. By providing a relevant video clip and carefully crafting the text prompt, you can potentially create unique and visually compelling video outputs that seamlessly blend the original footage with the generated content. Another idea is to explore the model's capabilities in generating videos with specific styles or visual aesthetics by adjusting the various input parameters, such as the resolution, frame rate, and guidance scale. This can help you achieve different looks and effects that may suit your specific needs or creative vision.
Updated 9/19/2024

real-esrgan-a40
204
real-esrgan-a40 is a variant of the Real-ESRGAN model, which is a powerful image upscaling and enhancement tool. It was created by anotherjesse, a prolific AI model developer. Like the original Real-ESRGAN, real-esrgan-a40 can upscale images while preserving details and reducing noise. It also has the ability to enhance facial features using the GFPGAN face enhancement model. Model inputs and outputs real-esrgan-a40 takes an input image and a scale factor, and outputs an upscaled and enhanced version of the image. The model supports adjustable upscaling, with a scale factor ranging from 0 to 10, allowing you to control the level of magnification. It also has a "face enhance" option, which can be used to improve the appearance of faces in the output image. Inputs image**: The input image to be upscaled and enhanced scale**: The factor to scale the image by, between 0 and 10 face_enhance**: A boolean flag to enable GFPGAN face enhancement Outputs Output**: The upscaled and enhanced version of the input image Capabilities real-esrgan-a40 is capable of significantly improving the quality of low-resolution images through its upscaling and enhancement capabilities. It can produce visually stunning results, especially when dealing with images that contain human faces. The model's ability to adjust the scale factor and enable face enhancement provides users with a high degree of control over the output. What can I use it for? real-esrgan-a40 can be used in a variety of applications, such as enhancing images for social media, improving the quality of old photographs, or generating high-resolution images for print and digital media. It could also be integrated into image editing workflows or used to upscale and enhance images generated by other AI models, such as real-esrgan or llava-lies. Things to try One interesting aspect of real-esrgan-a40 is its ability to enhance facial features. You could try using the "face enhance" option to improve the appearance of portraits or other images with human faces. Additionally, experimenting with different scale factors can produce a range of upscaling results, from subtle improvements to dramatic enlargements.
Updated 9/19/2024

controlnet-inpaint-test
89
controlnet-inpaint-test is a Stable Diffusion-based AI model created by Replicate user anotherjesse. This model is designed for inpainting tasks, allowing users to generate new content within a specified mask area of an image. It builds upon the capabilities of the ControlNet family of models, which leverage additional control signals to guide the image generation process. Similar models include controlnet-x-ip-adapter-realistic-vision-v5, multi-control, multi-controlnet-x-consistency-decoder-x-realestic-vision-v5, controlnet-x-majic-mix-realistic-x-ip-adapter, and controlnet-1.1-x-realistic-vision-v2.0, all of which explore various aspects of the ControlNet architecture and its applications. Model inputs and outputs controlnet-inpaint-test takes a set of inputs to guide the image generation process, including a mask, prompt, control image, and various hyperparameters. The model then outputs one or more images that match the provided prompt and control signals. Inputs Mask**: The area of the image to be inpainted. Prompt**: The text description of the desired output image. Control Image**: An optional image to guide the generation process. Seed**: A random seed value to control the output. Width/Height**: The dimensions of the output image. Num Outputs**: The number of images to generate. Scheduler**: The denoising scheduler to use. Guidance Scale**: The scale for classifier-free guidance. Num Inference Steps**: The number of denoising steps. Disable Safety Check**: An option to disable the safety check. Outputs Output Images**: One or more generated images that match the provided prompt and control signals. Capabilities controlnet-inpaint-test demonstrates the ability to generate new content within a specified mask area of an image, while maintaining coherence with the surrounding context. This can be useful for tasks such as object removal, scene editing, and image repair. What can I use it for? The controlnet-inpaint-test model can be utilized for a variety of image editing and manipulation tasks. For example, you could use it to remove unwanted elements from a photograph, replace damaged or occluded areas of an image, or combine different visual elements into a single cohesive scene. Additionally, the model's ability to generate new content based on a prompt and control image could be leveraged for creative projects, such as concept art or product visualization. Things to try One interesting aspect of controlnet-inpaint-test is its ability to blend the generated content seamlessly with the surrounding image. By carefully selecting the control image and mask, you can explore ways to create visually striking and plausible compositions. Additionally, experimenting with different prompts and hyperparameters can yield a wide range of creative outputs, from photorealistic to more fantastical imagery.
Updated 9/19/2024

multi-control
60
The multi-control model is an AI system that builds upon the Diffusers ControlNet, a powerful tool for generating images with fine-grained control. Developed by the maintainer anotherjesse, this model incorporates various ControlNet modules, allowing users to leverage multiple control inputs for their image generation tasks. The multi-control model is similar to other ControlNet-based models like img2paint_controlnet, qr_code_controlnet, and multi-controlnet-x-consistency-decoder-x-realestic-vision-v5, which also explore the versatility of ControlNet technology. Model inputs and outputs The multi-control model accepts a wide range of inputs, including prompts, control images, and various settings to fine-tune the generation process. Users can provide control images for different ControlNet modules, such as Canny, Depth, Normal, and more. The model then generates one or more output images based on the provided inputs. Inputs Prompt**: The text prompt that describes the desired image. Control Images**: A set of control images that provide guidance to the model, such as Canny, Depth, Normal, and others. Guidance Scale**: A parameter that controls the strength of the guidance from the control images. Number of Outputs**: The number of images to generate. Seed**: A seed value for the random number generator, allowing for reproducible results. Scheduler**: The algorithm used for the denoising diffusion process. Disable Safety Check**: An option to disable the safety check, which can be useful for advanced users but should be used with caution. Outputs Generated Images**: The output images generated by the model based on the provided inputs. Capabilities The multi-control model excels at generating visually striking and detailed images by leveraging multiple control inputs. It can be particularly useful for tasks that require precise control over the image generation process, such as product visualizations, architectural designs, or even scientific visualizations. The model's ability to combine various ControlNet modules allows users to fine-tune the generated images to their specific needs, making it a versatile tool for a wide range of applications. What can I use it for? The multi-control model can be used for a variety of applications, such as: Product Visualization**: Generate high-quality images of products with precise control over the details, lighting, and composition. Architectural Design**: Create realistic renderings of buildings, structures, or interior spaces with the help of control inputs like depth, normal maps, and segmentation. Scientific Visualization**: Visualize complex data or simulations with the ability to incorporate control inputs like edges, depth, and surface normals. Art and Design**: Explore creative image generation by combining multiple control inputs to achieve unique and visually striking results. Things to try One interesting aspect of the multi-control model is its ability to handle multiple control inputs simultaneously. Users can experiment with different combinations of control images, such as using Canny edge detection for outlining the structure, Depth for adding volume and perspective, and Normal maps for capturing surface details. This level of fine-tuning can lead to highly customized and compelling image outputs, making the multi-control model a valuable tool for a wide range of creative and technical applications.
Updated 9/19/2024

sdv2-preview
28
sdv2-preview is a preview of Stable Diffusion 2.0, a latent diffusion model capable of generating photorealistic images from text prompts. It was created by anotherjesse and builds upon the original Stable Diffusion model. The sdv2-preview model uses a downsampling-factor 8 autoencoder with an 865M UNet and OpenCLIP ViT-H/14 text encoder, producing 768x768 px outputs. It is trained from scratch and can be sampled with higher guidance scales than the original Stable Diffusion. Model inputs and outputs The sdv2-preview model takes a text prompt as input and generates one or more corresponding images as output. The text prompt can describe any scene, object, or concept, and the model will attempt to create a photorealistic visualization of it. Inputs Prompt**: A text description of the desired image content. Seed**: An optional random seed to control the stochastic generation process. Width/Height**: The desired dimensions of the output image, up to 1024x768 or 768x1024. Num Outputs**: The number of images to generate (up to 10). Guidance Scale**: A value that controls the trade-off between fidelity to the prompt and creativity in the generation process. Num Inference Steps**: The number of denoising steps used in the diffusion process. Outputs Images**: One or more photorealistic images corresponding to the input prompt. Capabilities The sdv2-preview model is capable of generating a wide variety of photorealistic images from text prompts, including landscapes, portraits, abstract concepts, and fantastical scenes. It has been trained on a large, diverse dataset and can handle complex prompts with multiple elements. What can I use it for? The sdv2-preview model can be used for a variety of creative and practical applications, such as: Generating concept art or illustrations for creative projects. Prototyping product designs or visualizing ideas. Creating unique and personalized images for marketing or social media. Exploring creative prompts and ideas without the need for traditional artistic skills. Things to try Some interesting things to try with the sdv2-preview model include: Experimenting with different types of prompts, from the specific to the abstract. Combining the model with other tools, such as image editing software or 3D modeling tools, to create more complex and integrated visuals. Exploring the model's capabilities for specific use cases, such as product design, character creation, or scientific visualization. Comparing the output of sdv2-preview to similar models, such as the original Stable Diffusion or the Stable Diffusion 2-1-unclip model, to understand the model's unique strengths and characteristics.
Updated 9/19/2024
🔎
sdxl-civit-lora
9
The sdxl-civit-lora model is a text-to-image generative AI model that builds upon the SDXL (Stable Diffusion XL) architecture, incorporating the CIVIT (Conditional Image-to-Video Translation) technique to enable inpainting and refiner capabilities. This model was created by anotherjesse, who has also developed similar models like llava-lies and sdxl-recur. Model inputs and outputs The sdxl-civit-lora model accepts a variety of inputs, including an image, a prompt, and optional parameters like a mask, seed, and refiner. It can generate one or more output images based on the provided inputs. Inputs Prompt**: The text prompt that describes the desired image. Negative Prompt**: Allows you to specify unwanted elements in the generated image. Image**: An existing image that can be used as a starting point for img2img or inpaint modes. Mask**: A URI that specifies a mask for the inpaint mode, where black areas will be preserved and white areas will be inpainted. Seed**: A random seed value to control the image generation process. Width/Height**: The desired dimensions of the output image. Num Outputs**: The number of images to generate. Scheduler**: The algorithm used for the image denoising process. Guidance Scale**: A scale factor that controls the influence of the text prompt on the generated image. Num Inference Steps**: The number of denoising steps to perform during image generation. Outputs Images**: One or more generated images in the form of URIs. Capabilities The sdxl-civit-lora model is capable of generating high-quality, visually striking images from text prompts. It can also perform image-to-image tasks like inpainting, where the model can fill in missing or damaged areas of an image based on the provided prompt and mask. What can I use it for? The sdxl-civit-lora model can be used for a variety of creative and practical applications, such as generating concept art, product visualizations, or even illustrations for stories and articles. The inpainting capabilities can be particularly useful for tasks like photo restoration or object removal. Additionally, the model can be fine-tuned or combined with other techniques to create specialized image generation tools. Things to try One interesting aspect of the sdxl-civit-lora model is its ability to incorporate LoRA (Low-Rank Adaptation) weights, which can be used to fine-tune the model for specific tasks or styles. Experimenting with different LoRA weights and the lora_scale parameter can lead to unique and unexpected results.
Updated 9/19/2024
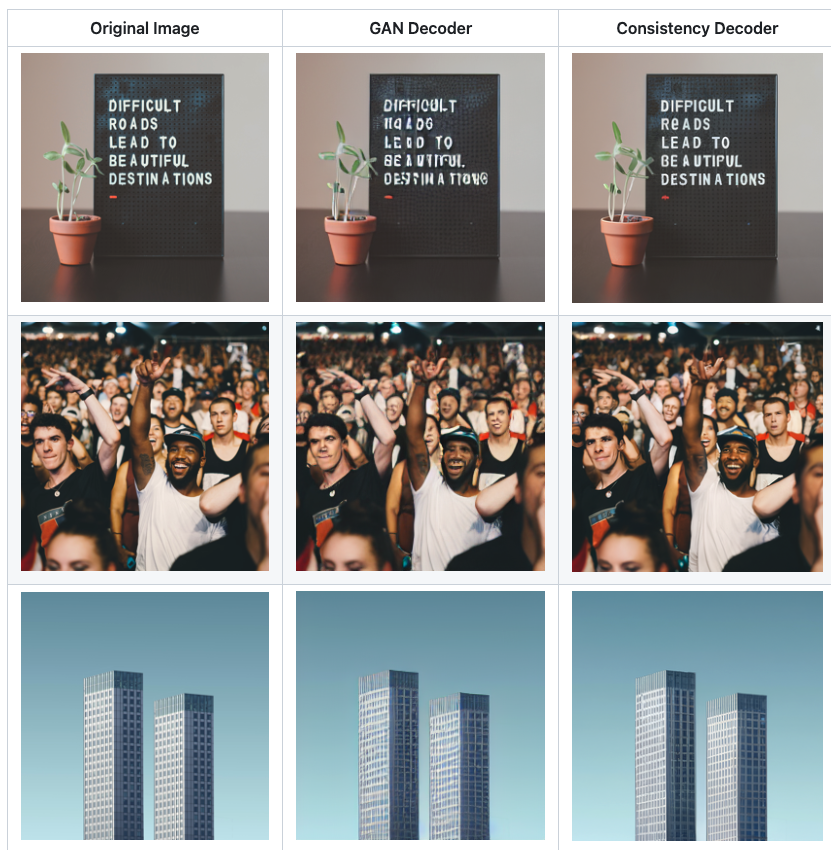
sd15-consistency-decoder-vae
2
sd15-consistency-decoder-vae is an AI model developed by anotherjesse that builds upon the Stable Diffusion 1.5 and OpenAI's Consistency Decoder models. It aims to generate photo-realistic images from text prompts, similar to other popular text-to-image models like Stable Diffusion and SDv2 Preview. Model inputs and outputs sd15-consistency-decoder-vae takes in a text prompt as the main input, along with optional parameters like seed, image size, number of outputs, and more. The model then generates one or more images based on the provided prompt and settings. Inputs Prompt**: The text prompt that describes the desired image Seed**: A random seed value to control image generation Width/Height**: The desired width and height of the output image Num Outputs**: The number of images to generate Guidance Scale**: The scale for classifier-free guidance Negative Prompt**: Specify things to not see in the output Consistency Decoder**: Enable or disable the consistency decoder Num Inference Steps**: The number of denoising steps Outputs One or more generated images, returned as an array of image URLs Capabilities sd15-consistency-decoder-vae is capable of generating a wide variety of photorealistic images from text prompts, including scenes, portraits, and more. The consistency decoder feature aims to improve the coherence and stability of the generated images. What can I use it for? sd15-consistency-decoder-vae can be used for various creative and practical applications, such as generating concept art, product visualizations, and even personalized content. The model's flexibility allows users to experiment with different prompts and settings to create unique and compelling images. As with any text-to-image model, it can be a powerful tool for artists, designers, and content creators. Things to try Try experimenting with different prompts, including specific details, adjectives, and contextual information to see how the model responds. You can also play with the various input parameters, such as adjusting the guidance scale or number of inference steps, to find the settings that work best for your desired output.
Updated 9/19/2024

llava-lies
2
llava-lies is a model developed by Replicate AI contributor anotherjesse. It is related to the LLaVA (Large Language and Vision Assistant) family of models, which are large language and vision models aimed at achieving GPT-4-level capabilities. The llava-lies model specifically focuses on injecting randomness into generated images. Model inputs and outputs The llava-lies model takes in the following inputs: Inputs Image**: The input image to generate from Prompt**: The prompt to use for text generation Image Seed**: The seed to use for image generation Temperature**: Adjusts the randomness of the outputs, with higher values resulting in more random generation Max Tokens**: The maximum number of tokens to generate The output of the model is an array of generated text. Capabilities The llava-lies model is capable of generating text based on a given prompt and input image, with the ability to control the randomness of the output through the temperature parameter. This could be useful for tasks like creative writing, image captioning, or generating descriptive text to accompany images. What can I use it for? The llava-lies model could be used in a variety of applications that require generating text based on visual inputs, such as: Automated image captioning for social media or e-commerce Generating creative story ideas or plot points based on visual prompts Enhancing product descriptions with visually-inspired text Exploring the creative potential of combining language and vision models Things to try One interesting aspect of the llava-lies model is its ability to inject randomness into the image generation process. This could be used to explore the boundaries of creative expression, generating a diverse range of interpretations or ideas based on a single visual prompt. Experimenting with different temperature settings and image seeds could yield unexpected and thought-provoking results.
Updated 8/31/2024

sdxl-recur
1
The sdxl-recur model is an exploration of image-to-image zooming and recursive generation of images, built on top of the SDXL model. This model allows for the generation of images through a process of progressive zooming and refinement, starting from an initial image or prompt. It is similar to other SDXL-based models like image-merge-sdxl, sdxl-custom-model, masactrl-sdxl, and sdxl, all of which build upon the core SDXL architecture. Model inputs and outputs The sdxl-recur model accepts a variety of inputs, including a prompt, an optional starting image, zoom factor, number of steps, and number of frames. The model then generates a series of images that progressively zoom in on the initial prompt or image. The outputs are an array of generated image URLs. Inputs Prompt**: The input text prompt that describes the desired image. Image**: An optional starting image that the model can use as a reference. Zoom**: The zoom factor to apply to the image during the recursive generation process. Steps**: The number of denoising steps to perform per image. Frames**: The number of frames to generate in the recursive process. Width/Height**: The desired width and height of the output images. Scheduler**: The scheduler algorithm to use for the diffusion process. Guidance Scale**: The scale for classifier-free guidance, which controls the balance between the prompt and the model's own generation. Prompt Strength**: The strength of the input prompt when using image-to-image or inpainting. Outputs The model generates an array of image URLs representing the recursively zoomed and refined images. Capabilities The sdxl-recur model is capable of generating images based on a text prompt, or starting from an existing image and recursively zooming and refining the output. This allows for the exploration of increasingly detailed and complex visual concepts, starting from a high-level prompt or initial image. What can I use it for? The sdxl-recur model could be useful for a variety of creative and artistic applications, such as generating concept art, visual storytelling, or exploring abstract and surreal imagery. The recursive zooming and refinement process could also be applied to tasks like product visualization, architectural design, or scientific visualization, where the ability to generate increasingly detailed and focused images could be valuable. Things to try One interesting aspect of the sdxl-recur model is the ability to start with an existing image and recursively zoom in, generating increasingly detailed and refined versions of the original. This could be useful for tasks like image enhancement, object detection, or content-aware image editing. Additionally, experimenting with different prompts, zoom factors, and other input parameters could lead to the discovery of unexpected and unique visual outputs.
Updated 9/19/2024