Active Learning with Task Adaptation Pre-training for Speech Emotion Recognition

0
🗣️
Sign in to get full access
Overview
- Speech emotion recognition (SER) is an important technology with applications in human-machine interaction, virtual assistants, and mental health assistance.
- Existing SER methods often struggle with the information gap between the pre-training speech recognition task and the downstream SER task, leading to sub-optimal performance.
- Current SER methods also require significant time for fine-tuning on specific speech datasets, limiting their effectiveness in real-world scenarios with large-scale noisy data.
Plain English Explanation
The paper proposes a new approach called AFTER to improve speech emotion recognition (SER) systems. SER is the ability of a computer system to understand the emotional state of a person based on their speech. This technology has many useful applications, like improving virtual assistants or helping with mental health treatment.
However, current SER systems often struggle because the initial training process (on speech recognition) doesn't match well with the final task of emotion recognition. This causes the systems to perform worse than they could. Additionally, these systems require a lot of time and effort to adapt to specific speech datasets, which limits their usefulness in real-world situations with lots of noisy or messy data.
The AFTER approach aims to address these problems. It first uses a technique called "task adaptation pre-training" to better align the initial speech recognition training with the final emotion recognition goal. Then, it employs "active learning" methods to quickly identify the most important speech samples to fine-tune the system, rather than having to use the entire dataset. This saves a lot of time while maintaining strong performance.
Technical Explanation
The paper introduces a new active learning (AL)-based fine-tuning framework for speech emotion recognition (SER), called AFTER. The key components of the AFTER framework are:
-
Task Adaptation Pre-Training (TAPT): This step aims to minimize the information gap between the pre-training speech recognition task and the downstream SER task. By aligning the pre-training and fine-tuning objectives, TAPT helps improve the performance of the SER model.
-
Active Learning (AL) Fine-Tuning: After the TAPT stage, the AFTER framework employs AL methods to iteratively select the most informative and diverse samples from the target dataset. This reduces the time required for fine-tuning, as the model only needs to be trained on a subset of the data.
The paper evaluates the AFTER framework on the IEMOCAP dataset and shows that it can improve accuracy by 8.45% while reducing the fine-tuning time by 79%, compared to existing methods.
Critical Analysis
The paper presents a promising approach to address the limitations of current SER systems. However, some potential areas for further research include:
- Generalization to other datasets: The evaluation is limited to the IEMOCAP dataset, and it would be valuable to assess the AFTER framework's performance on a wider range of speech emotion datasets.
- Robustness to noisy data: While the paper mentions the AFTER framework's potential for real-world scenarios with large-scale noisy data, the experimental validation is not comprehensive in this regard.
- Interpretability of the model: The paper does not provide much insight into the inner workings of the AFTER framework and how the various components contribute to the improved performance. Incorporating more interpretability would be valuable for understanding the model's strengths and weaknesses.
Conclusion
The proposed AFTER framework represents a significant advancement in speech emotion recognition (SER) by addressing the information gap between pre-training and fine-tuning, as well as the time-consuming nature of traditional fine-tuning approaches. By leveraging task adaptation pre-training and active learning methods, the AFTER framework can achieve substantial improvements in accuracy and efficiency, paving the way for more effective and practical SER systems in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Active Learning with Task Adaptation Pre-training for Speech Emotion Recognition
Dongyuan Li, Ying Zhang, Yusong Wang, Funakoshi Kataro, Manabu Okumura
Speech emotion recognition (SER) has garnered increasing attention due to its wide range of applications in various fields, including human-machine interaction, virtual assistants, and mental health assistance. However, existing SER methods often overlook the information gap between the pre-training speech recognition task and the downstream SER task, resulting in sub-optimal performance. Moreover, current methods require much time for fine-tuning on each specific speech dataset, such as IEMOCAP, which limits their effectiveness in real-world scenarios with large-scale noisy data. To address these issues, we propose an active learning (AL)-based fine-tuning framework for SER, called textsc{After}, that leverages task adaptation pre-training (TAPT) and AL methods to enhance performance and efficiency. Specifically, we first use TAPT to minimize the information gap between the pre-training speech recognition task and the downstream speech emotion recognition task. Then, AL methods are employed to iteratively select a subset of the most informative and diverse samples for fine-tuning, thereby reducing time consumption. Experiments demonstrate that our proposed method textsc{After}, using only 20% of samples, improves accuracy by 8.45% and reduces time consumption by 79%. The additional extension of textsc{After} and ablation studies further confirm its effectiveness and applicability to various real-world scenarios. Our source code is available on Github for reproducibility. (https://github.com/Clearloveyuan/AFTER).
Read more5/2/2024
0
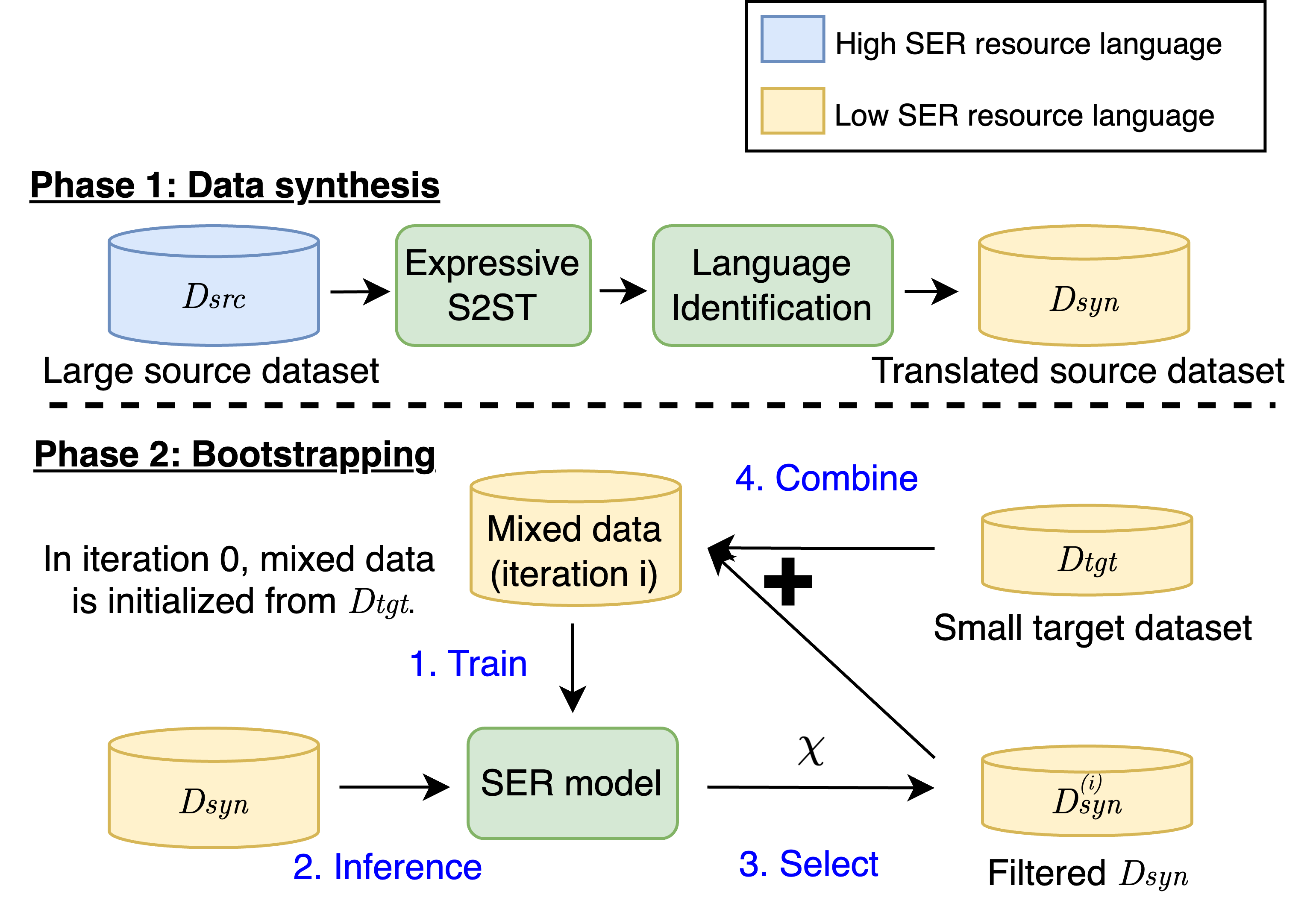
Improving Speech Emotion Recognition in Under-Resourced Languages via Speech-to-Speech Translation with Bootstrapping Data Selection
Hsi-Che Lin, Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
Speech Emotion Recognition (SER) is a crucial component in developing general-purpose AI agents capable of natural human-computer interaction. However, building robust multilingual SER systems remains challenging due to the scarcity of labeled data in languages other than English and Chinese. In this paper, we propose an approach to enhance SER performance in low SER resource languages by leveraging data from high-resource languages. Specifically, we employ expressive Speech-to-Speech translation (S2ST) combined with a novel bootstrapping data selection pipeline to generate labeled data in the target language. Extensive experiments demonstrate that our method is both effective and generalizable across different upstream models and languages. Our results suggest that this approach can facilitate the development of more scalable and robust multilingual SER systems.
Read more9/18/2024

0
Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Read more6/13/2024
0
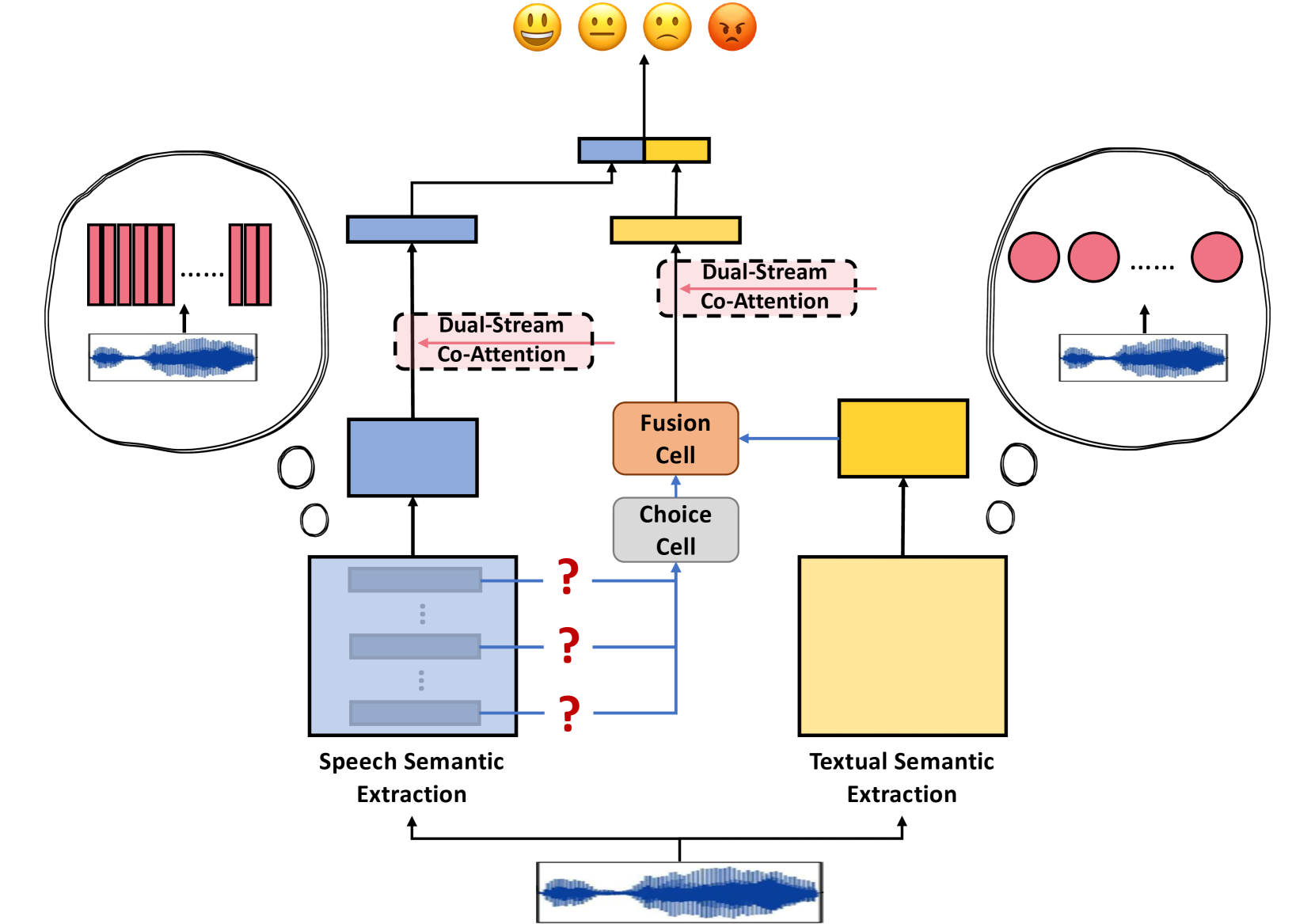
MFSN: Multi-perspective Fusion Search Network For Pre-training Knowledge in Speech Emotion Recognition
Haiyang Sun, Fulin Zhang, Yingying Gao, Zheng Lian, Shilei Zhang, Junlan Feng
Speech Emotion Recognition (SER) is an important research topic in human-computer interaction. Many recent works focus on directly extracting emotional cues through pre-trained knowledge, frequently overlooking considerations of appropriateness and comprehensiveness. Therefore, we propose a novel framework for pre-training knowledge in SER, called Multi-perspective Fusion Search Network (MFSN). Considering comprehensiveness, we partition speech knowledge into Textual-related Emotional Content (TEC) and Speech-related Emotional Content (SEC), capturing cues from both semantic and acoustic perspectives, and we design a new architecture search space to fully leverage them. Considering appropriateness, we verify the efficacy of different modeling approaches in capturing SEC and fills the gap in current research. Experimental results on multiple datasets demonstrate the superiority of MFSN.
Read more6/27/2024