FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance

0

Sign in to get full access
Overview
- The paper introduces FALIP (Foveal Attention Leveraged Interaction Prompt), a novel approach that leverages visual prompts to boost the zero-shot performance of CLIP, a popular vision-language model.
- FALIP aims to address the "hallucination" issue in text-to-image retrieval, where CLIP can sometimes generate irrelevant or distorted images.
- The key idea is to use a small visual prompt that attracts the model's attention to the most relevant parts of the input image, improving its ability to match the image with the correct text.
Plain English Explanation
FALIP is a new way to help CLIP, a powerful AI model that can match images and text, perform better at a task called "zero-shot learning." In zero-shot learning, the model is asked to identify an image without being shown examples of that specific type of image during training.
The researchers found that CLIP sometimes struggles with this task, generating irrelevant or distorted images when trying to match an image to text. FALIP addresses this by using a small visual "prompt" - a tiny image that is shown along with the main image. This prompt attracts the model's attention to the most important parts of the image, helping it make a better match between the image and the text.
Imagine you're trying to identify a specific type of bird in an image. The visual prompt might be a close-up of the bird's head or beak, guiding the model to focus on the key identifying features. This allows the model to better understand the relationship between the image and the text description, improving its zero-shot performance.
Technical Explanation
The paper introduces the FALIP (Foveal Attention Leveraged Interaction Prompt) approach, which aims to enhance the zero-shot performance of CLIP, a popular vision-language model. CLIP, or Contrastive Language-Image Pre-Training, is known for its ability to match images and text, but it can sometimes struggle with "hallucination" - generating irrelevant or distorted images when trying to match an image to a text description in a zero-shot setting.
FALIP addresses this issue by using a small visual prompt that is shown alongside the main input image. This prompt is designed to attract the model's attention to the most relevant parts of the image, improving its ability to match the image with the correct text. The researchers hypothesize that this foveal attention mechanism can boost CLIP's zero-shot performance by guiding the model's focus to the most informative visual cues.
The paper presents a series of experiments that evaluate the effectiveness of FALIP on various zero-shot tasks, including text-to-image retrieval, image classification, and few-shot learning. The results demonstrate that FALIP can significantly improve CLIP's performance compared to the standard CLIP model, particularly on challenging datasets and tasks.
Critical Analysis
The FALIP approach presents a promising solution to the hallucination issue in CLIP's zero-shot performance. By leveraging a small visual prompt to guide the model's attention, the researchers have shown that CLIP can better match images to text descriptions, even in cases where the model has not been exposed to those specific images during training.
However, the paper does not fully address the potential limitations of this approach. For example, the choice of the visual prompt and its optimal size and placement may be task-dependent, which could make FALIP more challenging to generalize to a wide range of applications. Additionally, the paper does not explore the potential trade-offs between the benefits of the visual prompt and any potential increase in computational complexity or model size.
Further research could investigate the generalization of FALIP to other vision-language models beyond CLIP, as well as explore more advanced attention mechanisms or meta-learning approaches to automatically learn the optimal visual prompts for a given task or dataset. Incorporating principles from Dual Image-Enhanced CLIP or Cascade CLIP could also lead to further performance improvements.
Conclusion
The FALIP approach presented in this paper offers a novel solution to the hallucination issue in CLIP's zero-shot performance. By using a small visual prompt to guide the model's attention, FALIP can significantly improve CLIP's ability to match images to text descriptions, even in challenging scenarios. This research highlights the importance of leveraging visual attention mechanisms to enhance the capabilities of vision-language models, and it opens up new avenues for further exploration in the field of zero-shot learning and multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance
Jiedong Zhuang, Jiaqi Hu, Lianrui Mu, Rui Hu, Xiaoyu Liang, Jiangnan Ye, Haoji Hu
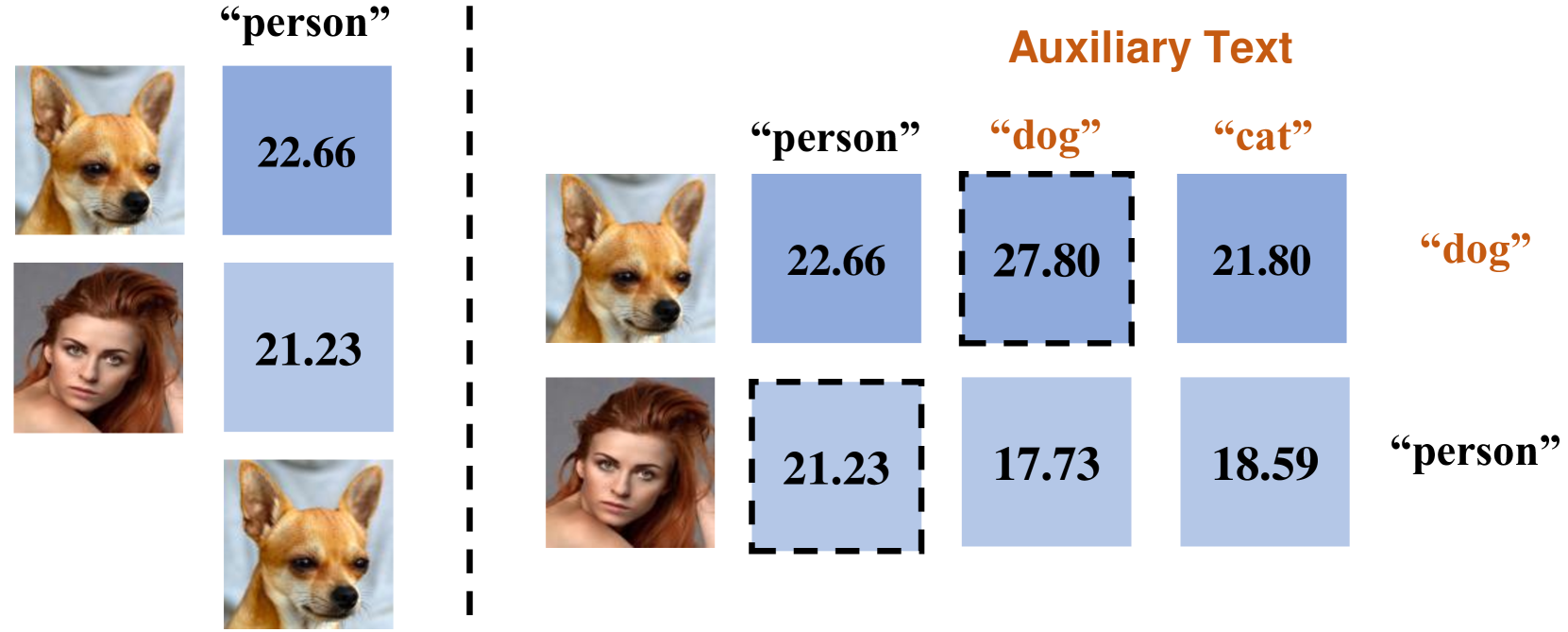
CLIP has achieved impressive zero-shot performance after pre-training on a large-scale dataset consisting of paired image-text data. Previous works have utilized CLIP by incorporating manually designed visual prompts like colored circles and blur masks into the images to guide the model's attention, showing enhanced zero-shot performance in downstream tasks. Although these methods have achieved promising results, they inevitably alter the original information of the images, which can lead to failure in specific tasks. We propose a train-free method Foveal-Attention CLIP (FALIP), which adjusts the CLIP's attention by inserting foveal attention masks into the multi-head self-attention module. We demonstrate FALIP effectively boosts CLIP zero-shot performance in tasks such as referring expressions comprehension, image classification, and 3D point cloud recognition. Experimental results further show that FALIP outperforms existing methods on most metrics and can augment current methods to enhance their performance.
Read more8/22/2024
0
Towards Alleviating Text-to-Image Retrieval Hallucination for CLIP in Zero-shot Learning
Hanyao Wang, Yibing Zhan, Liu Liu, Liang Ding, Yan Yang, Jun Yu
Pretrained cross-modal models, for instance, the most representative CLIP, have recently led to a boom in using pre-trained models for cross-modal zero-shot tasks, considering the generalization properties. However, we analytically discover that CLIP suffers from the text-to-image retrieval hallucination, adversely limiting its capabilities under zero-shot learning: CLIP would select the image with the highest score when asked to figure out which image perfectly matches one given query text among several candidate images even though CLIP knows contents in the image. Accordingly, we propose a Balanced Score with Auxiliary Prompts (BSAP) to mitigate the CLIP's text-to-image retrieval hallucination under zero-shot learning. Specifically, we first design auxiliary prompts to provide multiple reference outcomes for every single image retrieval, then the outcomes derived from each retrieved image in conjunction with the target text are normalized to obtain the final similarity, which alleviates hallucinations in the model. Additionally, we can merge CLIP's original results and BSAP to obtain a more robust hybrid outcome (BSAP-H). Extensive experiments on two typical zero-shot learning tasks, i.e., Referring Expression Comprehension (REC) and Referring Image Segmentation (RIS), are conducted to demonstrate the effectiveness of our BSAP. Specifically, when evaluated on the validation dataset of RefCOCO in REC, BSAP increases CLIP's performance by 20.6%. Further, we validate that our strategy could be applied in other types of pretrained cross-modal models, such as ALBEF and BLIP.
Read more6/28/2024

0
Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval
Gangyan Zeng, Yuan Zhang, Jin Wei, Dongbao Yang, Peng Zhang, Yiwen Gao, Xugong Qin, Yu Zhou
Scene text retrieval aims to find all images containing the query text from an image gallery. Current efforts tend to adopt an Optical Character Recognition (OCR) pipeline, which requires complicated text detection and/or recognition processes, resulting in inefficient and inflexible retrieval. Different from them, in this work we propose to explore the intrinsic potential of Contrastive Language-Image Pre-training (CLIP) for OCR-free scene text retrieval. Through empirical analysis, we observe that the main challenges of CLIP as a text retriever are: 1) limited text perceptual scale, and 2) entangled visual-semantic concepts. To this end, a novel model termed FDP (Focus, Distinguish, and Prompt) is developed. FDP first focuses on scene text via shifting the attention to the text area and probing the hidden text knowledge, and then divides the query text into content word and function word for processing, in which a semantic-aware prompting scheme and a distracted queries assistance module are utilized. Extensive experiments show that FDP significantly enhances the inference speed while achieving better or competitive retrieval accuracy compared to existing methods. Notably, on the IIIT-STR benchmark, FDP surpasses the state-of-the-art model by 4.37% with a 4 times faster speed. Furthermore, additional experiments under phrase-level and attribute-aware scene text retrieval settings validate FDP's particular advantages in handling diverse forms of query text. The source code will be publicly available at https://github.com/Gyann-z/FDP.
Read more8/2/2024

0
ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, Wayne Zhang
Open-vocabulary semantic segmentation requires models to effectively integrate visual representations with open-vocabulary semantic labels. While Contrastive Language-Image Pre-training (CLIP) models shine in recognizing visual concepts from text, they often struggle with segment coherence due to their limited localization ability. In contrast, Vision Foundation Models (VFMs) excel at acquiring spatially consistent local visual representations, yet they fall short in semantic understanding. This paper introduces ProxyCLIP, an innovative framework designed to harmonize the strengths of both CLIP and VFMs, facilitating enhanced open-vocabulary semantic segmentation. ProxyCLIP leverages the spatial feature correspondence from VFMs as a form of proxy attention to augment CLIP, thereby inheriting the VFMs' robust local consistency and maintaining CLIP's exceptional zero-shot transfer capacity. We propose an adaptive normalization and masking strategy to get the proxy attention from VFMs, allowing for adaptation across different VFMs. Remarkably, as a training-free approach, ProxyCLIP significantly improves the average mean Intersection over Union (mIoU) across eight benchmarks from 40.3 to 44.4, showcasing its exceptional efficacy in bridging the gap between spatial precision and semantic richness for the open-vocabulary segmentation task.
Read more8/12/2024