Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents

0

Sign in to get full access
Overview
- This paper presents "Agent Q", an advanced AI agent capable of reasoning, learning, and autonomous decision-making.
- Key features of Agent Q include:
- Powerful reasoning and planning capabilities
- Capacity for self-improvement and continual learning
- Ability to operate in complex, dynamic environments
Plain English Explanation
The researchers have developed an AI agent called "Agent Q" that can engage in advanced reasoning, learning, and autonomous decision-making. Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents is designed to operate effectively in complex, constantly changing environments.
Some of the key capabilities of Agent Q include:
- Powerful Reasoning and Planning: Agent Q can use sophisticated techniques like Monte Carlo tree search to analyze situations, weigh options, and plan out sequences of actions.
- Continual Learning: The agent can continuously learn and improve itself over time, adapting to new challenges and environments.
- Autonomy: Agent Q is designed to operate independently, making its own decisions and taking actions without the need for constant human supervision or intervention.
The researchers believe that agents like Agent Q could have a wide range of applications, from assistive technologies to autonomous systems operating in complex, real-world environments. By combining advanced reasoning, learning, and autonomy, these AI agents could help tackle a variety of tasks and problems that are difficult or impractical for humans to address alone.
Technical Explanation
The core of Agent Q is its reasoning and planning capabilities, which allow it to analyze situations, consider different options, and chart out sequences of actions to achieve its objectives. The researchers leverage techniques like Monte Carlo tree search to enable Agent Q to rapidly evaluate and compare potential courses of action.
In addition to its reasoning abilities, Agent Q also has the capacity for continuous learning and self-improvement. The agent can draw insights from its experiences, update its knowledge and decision-making models, and enhance its own capabilities over time. This allows Agent Q to adapt to new challenges and operate effectively in dynamic, ever-changing environments.
The researchers also designed Agent Q to be highly autonomous, with the ability to make decisions and take actions independently without the need for constant human oversight or intervention. This autonomy is enabled by the agent's advanced reasoning, learning, and decision-making capabilities, as well as its understanding of the theoretical underpinnings of language and action.
Critical Analysis
The researchers have put forth a compelling vision for Agent Q and its potential capabilities. However, the paper does not delve deeply into the specific technical details of the agent's architecture or the precise mechanisms underlying its reasoning and learning processes. Enhancing the general capabilities of Agent Q with low-parameter large language models could be an area for further exploration and clarification.
Additionally, while the paper highlights the agent's autonomy, it does not address potential concerns around the safety and reliability of such autonomous systems, or the ethical implications of deploying them in real-world applications. These are important considerations that should be carefully examined in future work.
Conclusion
The research presented in this paper represents a significant step forward in the development of advanced, autonomous AI agents. By combining powerful reasoning, continuous learning, and a high degree of autonomy, Agent Q demonstrates the potential for AI systems to operate effectively in complex, dynamic environments, and potentially tackle a wide range of challenges that are difficult or impractical for humans to address alone. As the field of AI continues to evolve, further research and development in this area could lead to transformative advancements with far-reaching implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, Rafael Rafailov
Large Language Models (LLMs) have shown remarkable capabilities in natural language tasks requiring complex reasoning, yet their application in agentic, multi-step reasoning within interactive environments remains a difficult challenge. Traditional supervised pre-training on static datasets falls short in enabling autonomous agent capabilities needed to perform complex decision-making in dynamic settings like web navigation. Previous attempts to bridge this ga-through supervised fine-tuning on curated expert demonstrations-often suffer from compounding errors and limited exploration data, resulting in sub-optimal policy outcomes. To overcome these challenges, we propose a framework that combines guided Monte Carlo Tree Search (MCTS) search with a self-critique mechanism and iterative fine-tuning on agent interactions using an off-policy variant of the Direct Preference Optimization (DPO) algorithm. Our method allows LLM agents to learn effectively from both successful and unsuccessful trajectories, thereby improving their generalization in complex, multi-step reasoning tasks. We validate our approach in the WebShop environment-a simulated e-commerce platform where it consistently outperforms behavior cloning and reinforced fine-tuning baseline, and beats average human performance when equipped with the capability to do online search. In real-world booking scenarios, our methodology boosts Llama-3 70B model's zero-shot performance from 18.6% to 81.7% success rate (a 340% relative increase) after a single day of data collection and further to 95.4% with online search. We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings.
Read more8/15/2024
🔎
0
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
Read more6/19/2024
0
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
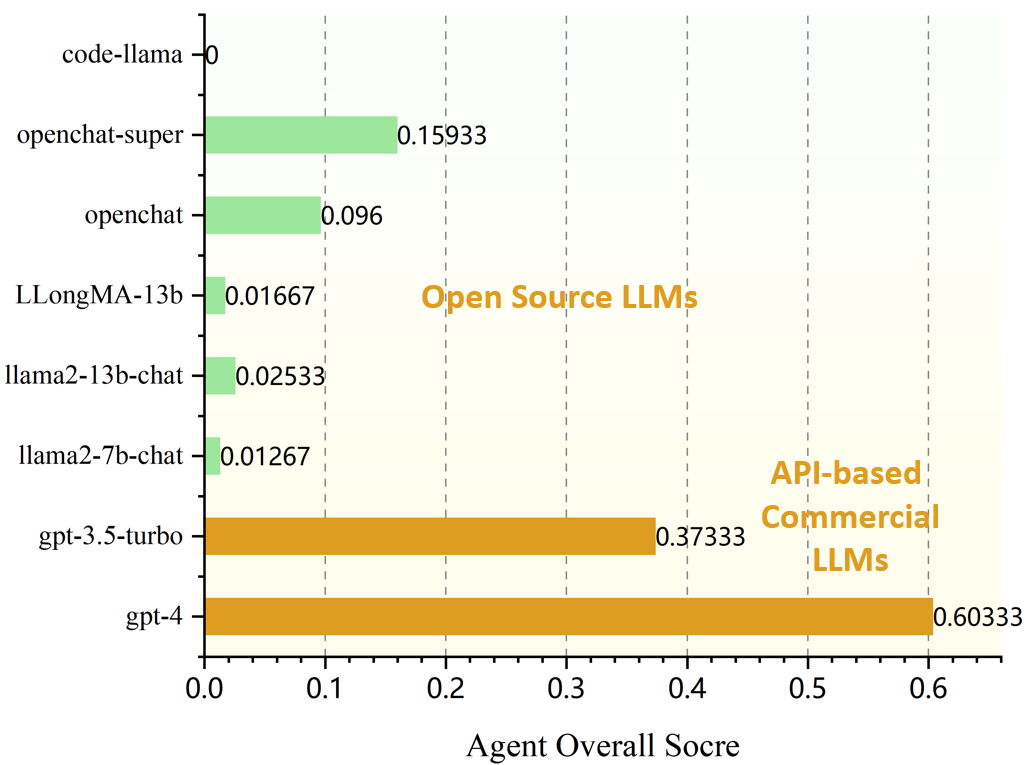
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
Read more4/1/2024
✅
0
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafiq Joty
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
Read more4/16/2024