Align and Aggregate: Compositional Reasoning with Video Alignment and Answer Aggregation for Video Question-Answering

0

Sign in to get full access
Overview
- This paper introduces a new approach called "Align and Aggregate" for video question-answering, which aims to improve compositional reasoning by aligning video frames with question components and aggregating the relevant information.
- The key ideas are to align video frames with question components and aggregate the aligned information to answer the question.
- The model is evaluated on the VQAv2 and TVQA datasets, showing improvements over previous state-of-the-art approaches.
Plain English Explanation
The paper presents a new way to answer questions about videos. The key idea is to break down the question into smaller components and then match each component to the relevant parts of the video. By aligning the question and video in this way, the model can focus on the most important information to answer the question.
For example, if the question is "What color is the car that the person is driving?", the model would first identify the relevant parts of the video - the car and the person driving it. It would then use this alignment between the question and the video to determine the color of the car and provide the answer.
This approach of aligning the question with the video and aggregating the relevant information is called "Align and Aggregate". The researchers show that this method outperforms previous state-of-the-art techniques for answering questions about videos, particularly when the questions require combining different pieces of information from the video.
Technical Explanation
The paper proposes a new "Align and Aggregate" approach for video question-answering. The core idea is to align the video frames with the components of the question and then aggregate the aligned information to answer the question.
The model first encodes the video and question separately using transformer-based architectures. It then aligns the video frames with the question components by computing attention weights between the video and question features. This allows the model to identify the most relevant parts of the video for answering each part of the question.
Next, the model aggregates the aligned video features based on the question structure. This is done using a modular reasoning network that applies different operations (e.g., pooling, concatenation) to the aligned features depending on the question type. The final answer is then predicted from the aggregated video features.
The "Align and Aggregate" approach is evaluated on the VQAv2 and TVQA datasets, where it outperforms previous state-of-the-art methods. The authors also conduct ablation studies to show the importance of the alignment and aggregation components.
Critical Analysis
The "Align and Aggregate" approach presented in this paper is a promising step towards more compositional and interpretable video question-answering models. By explicitly aligning the video and question components, the model can focus on the most relevant information to answer each part of the question.
However, the paper does not address the potential limitations of this approach. For example, the alignment process relies on attention mechanisms, which can be sensitive to biases in the training data. There may also be cases where the question cannot be easily decomposed into separate components, limiting the effectiveness of the aggregation step.
Additionally, the paper does not provide a detailed analysis of the model's performance on different types of questions or video content. It would be helpful to understand the strengths and weaknesses of the approach in different scenarios, such as when the question requires complex spatial-temporal reasoning or when the video contains distracting information.
Furthermore, the paper does not discuss the potential weakly-supervised or modular aspects of the model, which could be important for improving its generalization and interpretability.
Overall, the "Align and Aggregate" approach is a promising step forward, but further research is needed to address its limitations and fully understand its potential impact on video question-answering.
Conclusion
This paper introduces a new "Align and Aggregate" approach for video question-answering that aims to improve compositional reasoning. The key ideas are to align the video frames with the question components and then aggregate the aligned information to answer the question.
The experimental results show that this approach outperforms previous state-of-the-art methods on standard benchmarks, indicating its potential for advancing the field of video question-answering. The paper also highlights the importance of explicitly modeling the relationship between the video and question, which could have broader implications for other multimodal reasoning tasks.
While the "Align and Aggregate" approach is a promising step forward, further research is needed to address its limitations and fully explore its capabilities. Potential areas for future work include investigating the model's performance on different types of questions and videos, as well as exploring weakly-supervised or modular aspects that could improve its generalization and interpretability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Align and Aggregate: Compositional Reasoning with Video Alignment and Answer Aggregation for Video Question-Answering
Zhaohe Liao, Jiangtong Li, Li Niu, Liqing Zhang
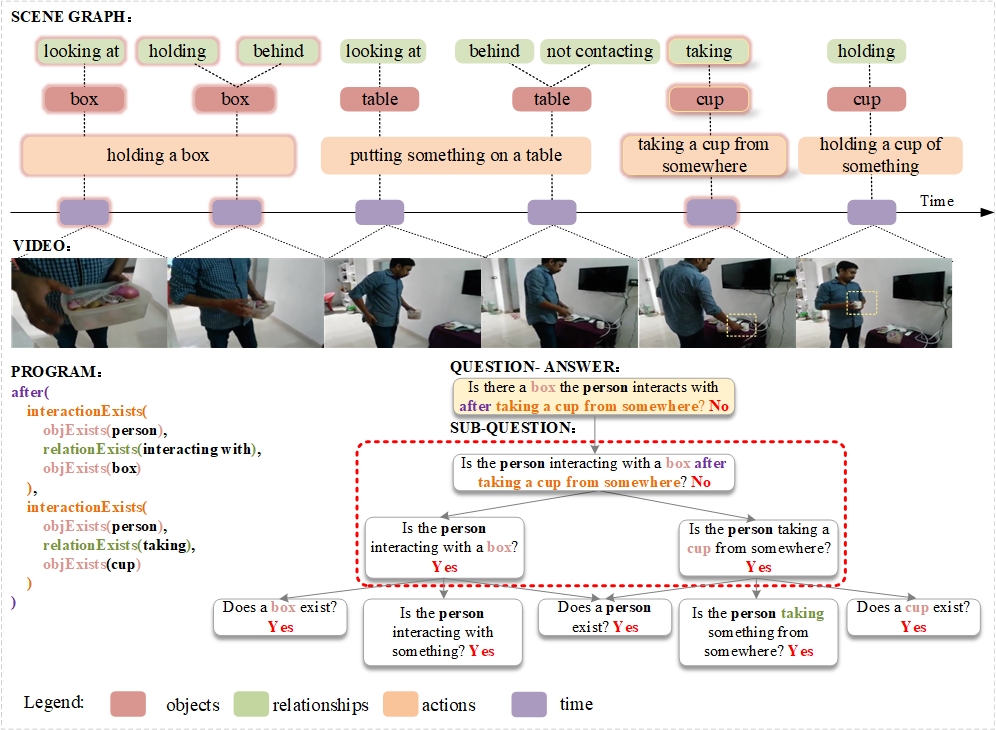
Despite the recent progress made in Video Question-Answering (VideoQA), these methods typically function as black-boxes, making it difficult to understand their reasoning processes and perform consistent compositional reasoning. To address these challenges, we propose a textit{model-agnostic} Video Alignment and Answer Aggregation (VA$^{3}$) framework, which is capable of enhancing both compositional consistency and accuracy of existing VidQA methods by integrating video aligner and answer aggregator modules. The video aligner hierarchically selects the relevant video clips based on the question, while the answer aggregator deduces the answer to the question based on its sub-questions, with compositional consistency ensured by the information flow along question decomposition graph and the contrastive learning strategy. We evaluate our framework on three settings of the AGQA-Decomp dataset with three baseline methods, and propose new metrics to measure the compositional consistency of VidQA methods more comprehensively. Moreover, we propose a large language model (LLM) based automatic question decomposition pipeline to apply our framework to any VidQA dataset. We extend MSVD and NExT-QA datasets with it to evaluate our VA$^3$ framework on broader scenarios. Extensive experiments show that our framework improves both compositional consistency and accuracy of existing methods, leading to more interpretable real-world VidQA models.
Read more7/4/2024
0
Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
Lili Liang, Guanglu Sun, Jin Qiu, Lizhong Zhang
Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
Read more4/8/2024

0
ComAlign: Compositional Alignment in Vision-Language Models
Ali Abdollah, Amirmohammad Izadi, Armin Saghafian, Reza Vahidimajd, Mohammad Mozafari, Amirreza Mirzaei, Mohammadmahdi Samiei, Mahdieh Soleymani Baghshah
Vision-language models (VLMs) like CLIP have showcased a remarkable ability to extract transferable features for downstream tasks. Nonetheless, the training process of these models is usually based on a coarse-grained contrastive loss between the global embedding of images and texts which may lose the compositional structure of these modalities. Many recent studies have shown VLMs lack compositional understandings like attribute binding and identifying object relationships. Although some recent methods have tried to achieve finer-level alignments, they either are not based on extracting meaningful components of proper granularity or don't properly utilize the modalities' correspondence (especially in image-text pairs with more ingredients). Addressing these limitations, we introduce Compositional Alignment (ComAlign), a fine-grained approach to discover more exact correspondence of text and image components using only the weak supervision in the form of image-text pairs. Our methodology emphasizes that the compositional structure (including entities and relations) extracted from the text modality must also be retained in the image modality. To enforce correspondence of fine-grained concepts in image and text modalities, we train a lightweight network lying on top of existing visual and language encoders using a small dataset. The network is trained to align nodes and edges of the structure across the modalities. Experimental results on various VLMs and datasets demonstrate significant improvements in retrieval and compositional benchmarks, affirming the effectiveness of our plugin model.
Read more9/14/2024

0
Listen Then See: Video Alignment with Speaker Attention
Aviral Agrawal (Carnegie Mellon University), Carlos Mateo Samudio Lezcano (Carnegie Mellon University), Iqui Balam Heredia-Marin (Carnegie Mellon University), Prabhdeep Singh Sethi (Carnegie Mellon University)
Video-based Question Answering (Video QA) is a challenging task and becomes even more intricate when addressing Socially Intelligent Question Answering (SIQA). SIQA requires context understanding, temporal reasoning, and the integration of multimodal information, but in addition, it requires processing nuanced human behavior. Furthermore, the complexities involved are exacerbated by the dominance of the primary modality (text) over the others. Thus, there is a need to help the task's secondary modalities to work in tandem with the primary modality. In this work, we introduce a cross-modal alignment and subsequent representation fusion approach that achieves state-of-the-art results (82.06% accuracy) on the Social IQ 2.0 dataset for SIQA. Our approach exhibits an improved ability to leverage the video modality by using the audio modality as a bridge with the language modality. This leads to enhanced performance by reducing the prevalent issue of language overfitting and resultant video modality bypassing encountered by current existing techniques. Our code and models are publicly available at https://github.com/sts-vlcc/sts-vlcc
Read more4/23/2024