Assessing Contamination in Large Language Models: Introducing the LogProber method

0

Sign in to get full access
Overview
- Introduces the LogProber method for assessing contamination in large language models.
- Contamination refers to when a model has "memorized" training data and can reproduce it, leading to privacy and security concerns.
- The paper presents a technique to quantify the extent of contamination in language models.
Plain English Explanation
The paper discusses a new method called LogProber for evaluating how much a large language model, like GPT-3, has "memorized" or become contaminated by the data it was trained on. When a model is trained on a large amount of online text, it can sometimes remember and reproduce specific pieces of that training data, which can raise privacy and security issues.
LogProber provides a way to measure the extent of this contamination. By probing the model with carefully crafted prompts, the researchers can estimate how much the model has memorized versus how much it has truly learned. This can help identify potential privacy risks and guide efforts to make language models more secure and trustworthy.
Technical Explanation
The paper introduces the LogProber method for quantifying contamination in large language models. Contamination refers to when a model has memorized specific training data and can reproduce it, which raises privacy and security concerns.
LogProber works by probing the model with carefully crafted prompts that are designed to elicit responses that would indicate the model has memorized parts of its training data. By analyzing the model's responses, the researchers can estimate the extent of contamination.
The paper describes the technical details of the LogProber method, including the prompt design, response analysis, and interpretation of the results. The authors also present experimental results demonstrating the application of LogProber to several large language models.
Critical Analysis
The paper provides a valuable contribution by introducing a rigorous method for assessing contamination in large language models. However, the authors acknowledge some limitations of their approach. For example, LogProber may not be able to detect more subtle forms of contamination, and the prompts used may not fully capture all possible ways a model could reproduce training data.
Additionally, the paper focuses on a specific type of contamination (direct reproduction of training data), but there may be other ways models could exhibit concerning behavior due to their training data, such as biases or limited generalization. Further research is needed to develop a more comprehensive taxonomy and understanding of data contamination in language models.
Conclusion
The LogProber method introduced in this paper represents an important step forward in assessing the privacy and security risks of large language models. By providing a way to quantify contamination, the technique can help guide efforts to develop more trustworthy and robust language models that protect user privacy. As the use of these models continues to grow, tools like LogProber will be increasingly crucial for ensuring the responsible development and deployment of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assessing Contamination in Large Language Models: Introducing the LogProber method
Nicolas Yax, Pierre-Yves Oudeyer, Stefano Palminteri
In machine learning, contamination refers to situations where testing data leak into the training set. The issue is particularly relevant for the evaluation of the performance of Large Language Models (LLMs), which are generally trained on gargantuan, and generally opaque, corpora of text scraped from the world wide web. Developing tools to detect contamination is therefore crucial to be able to fairly and properly track the evolution of the performance of LLMs. Most recent works in the field are not tailored to quantify contamination on short sequences of text like we find in psychology questionnaires. In the present paper we introduce LogProber, a novel, efficient, algorithm that we show able to detect contamination using token probability in given sentences. In the second part we investigate the limitations of the method and discuss how different training methods can contaminate models without leaving traces in the token probabilities.
Read more8/27/2024
💬
0
How Much are Large Language Models Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mathieu Ravaut, Bosheng Ding, Fangkai Jiao, Hailin Chen, Xingxuan Li, Ruochen Zhao, Chengwei Qin, Caiming Xiong, Shafiq Joty
With the rise of Large Language Models (LLMs) in recent years, abundant new opportunities are emerging, but also new challenges, among which contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a major issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently detect contamination.In this paper, we survey all recent work on contamination detection with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms.
Read more8/22/2024
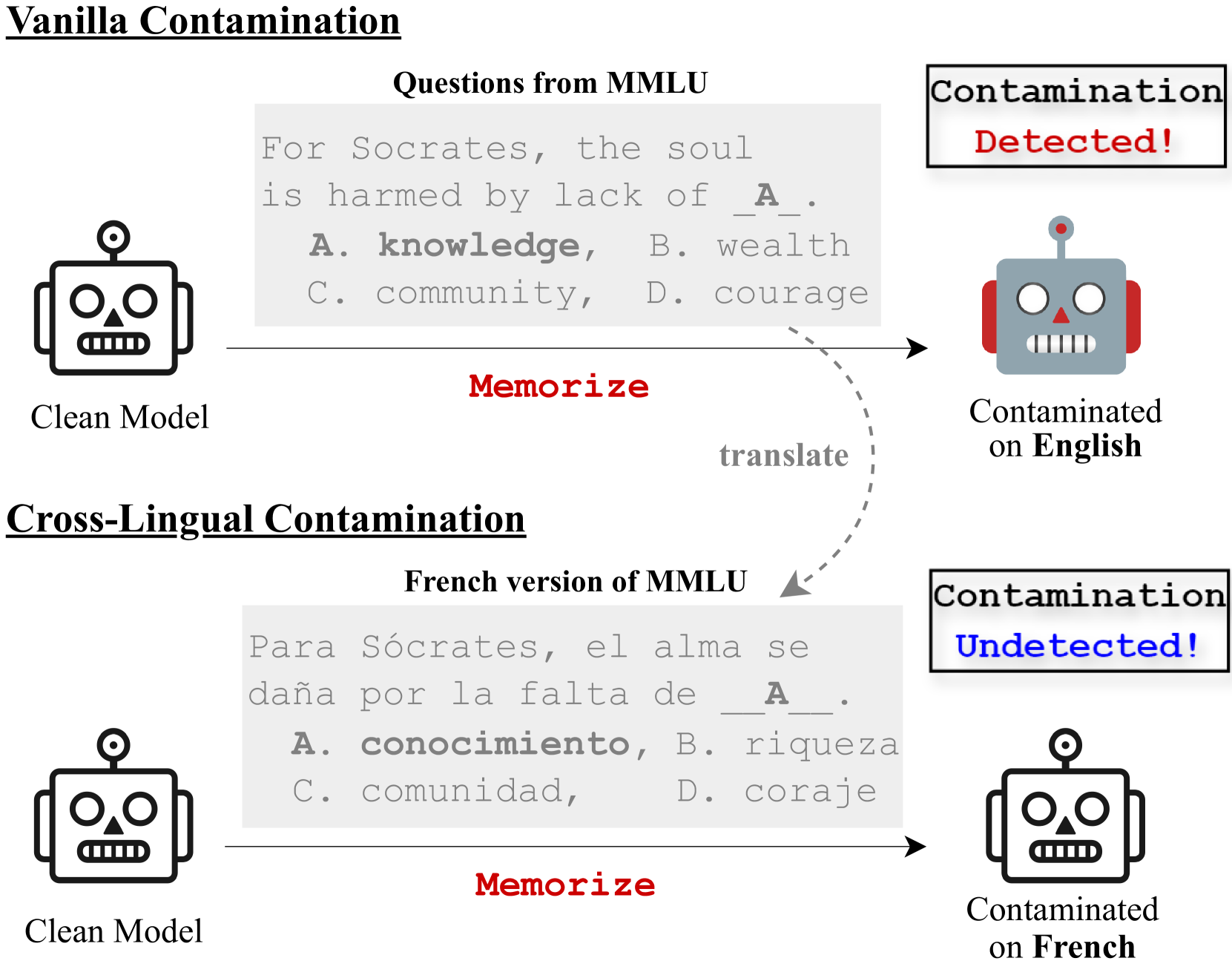
0
Data Contamination Can Cross Language Barriers
Feng Yao, Yufan Zhuang, Zihao Sun, Sunan Xu, Animesh Kumar, Jingbo Shang
The opacity in developing large language models (LLMs) is raising growing concerns about the potential contamination of public benchmarks in the pre-training data. Existing contamination detection methods are typically based on the text overlap between training and evaluation data, which can be too superficial to reflect deeper forms of contamination. In this paper, we first present a cross-lingual form of contamination that inflates LLMs' performance while evading current detection methods, deliberately injected by overfitting LLMs on the translated versions of benchmark test sets. Then, we propose generalization-based approaches to unmask such deeply concealed contamination. Specifically, we examine the LLM's performance change after modifying the original benchmark by replacing the false answer choices with correct ones from other questions. Contaminated models can hardly generalize to such easier situations, where the false choices can be emph{not even wrong}, as all choices are correct in their memorization. Experimental results demonstrate that cross-lingual contamination can easily fool existing detection methods, but not ours. In addition, we discuss the potential utilization of cross-lingual contamination in interpreting LLMs' working mechanisms and in post-training LLMs for enhanced multilingual capabilities. The code and dataset we use can be obtained from url{https://github.com/ShangDataLab/Deep-Contam}.
Read more6/21/2024
📊
0
A Taxonomy for Data Contamination in Large Language Models
Medha Palavalli, Amanda Bertsch, Matthew R. Gormley
Large language models pretrained on extensive web corpora demonstrate remarkable performance across a wide range of downstream tasks. However, a growing concern is data contamination, where evaluation datasets may be contained in the pretraining corpus, inflating model performance. Decontamination, the process of detecting and removing such data, is a potential solution; yet these contaminants may originate from altered versions of the test set, evading detection during decontamination. How different types of contamination impact the performance of language models on downstream tasks is not fully understood. We present a taxonomy that categorizes the various types of contamination encountered by LLMs during the pretraining phase and identify which types pose the highest risk. We analyze the impact of contamination on two key NLP tasks -- summarization and question answering -- revealing how different types of contamination influence task performance during evaluation.
Read more7/12/2024