Astro-NER -- Astronomy Named Entity Recognition: Is GPT a Good Domain Expert Annotator?
2405.02602
0
0
🌐
Abstract
In this study, we address one of the challenges of developing NER models for scholarly domains, namely the scarcity of suitable labeled data. We experiment with an approach using predictions from a fine-tuned LLM model to aid non-domain experts in annotating scientific entities within astronomy literature, with the goal of uncovering whether such a collaborative process can approximate domain expertise. Our results reveal moderate agreement between a domain expert and the LLM-assisted non-experts, as well as fair agreement between the domain expert and the LLM model's predictions. In an additional experiment, we compare the performance of finetuned and default LLMs on this task. We have also introduced a specialized scientific entity annotation scheme for astronomy, validated by a domain expert. Our approach adopts a scholarly research contribution-centric perspective, focusing exclusively on scientific entities relevant to the research theme. The resultant dataset, containing 5,000 annotated astronomy article titles, is made publicly available.
Create account to get full access
Overview
- This paper discusses the use of a large language model, GPT, as a domain expert annotator for astronomy named entity recognition (Astro-NER).
- The researchers investigate whether GPT can effectively identify and classify astronomical entities in scientific text, which could aid in the creation of high-quality datasets for Astro-NER.
- The paper compares the performance of GPT-based annotation to human expert annotation, evaluating factors such as accuracy, consistency, and efficiency.
Plain English Explanation
In this paper, the researchers explore whether a powerful AI language model called GPT can be used as a "domain expert" to help identify and categorize important terms and concepts in astronomy-related scientific texts. The goal is to see if GPT can assist in the creation of high-quality datasets for astronomy named entity recognition, which is the process of automatically detecting and classifying astronomical objects, instruments, theories, and other key elements in scientific literature.
The researchers compare the performance of GPT-based annotation to annotation done by human astronomy experts. They look at factors like accuracy, consistency, and efficiency to see if GPT can match or even outperform human experts in this task. If GPT proves to be a capable "domain expert annotator," it could significantly streamline the process of building comprehensive datasets for training Astro-NER models, which could in turn advance research in areas like automated understanding of scientific texts.
Technical Explanation
The paper presents an evaluation of using the GPT language model as a domain expert for annotating astronomical named entities in scientific text, a process known as Astro-NER. The researchers collected a dataset of astronomy-related papers and had both GPT and human experts annotate the text, identifying and classifying key entities like celestial objects, instruments, and theories.
They then compared the performance of the GPT-based annotations to the human expert annotations, measuring factors such as entity extraction accuracy, entity classification accuracy, and annotation consistency. The results suggest that GPT can achieve near-human-level performance on many Astro-NER tasks, demonstrating its potential as a scalable, cost-effective tool for constructing high-quality Astro-NER datasets.
The paper also discusses the limitations of the GPT-based approach, noting that it may struggle with rare or context-dependent entities, as well as the need for further research to fine-tune GPT's performance and robustness for domain-specific NER tasks. Overall, the findings indicate that large language models like GPT can serve as valuable domain expert annotators to support the development of advanced natural language processing capabilities in specialized fields like astronomy.
Critical Analysis
The paper presents a thorough and well-designed evaluation of GPT's performance as an Astro-NER annotator, considering important factors like accuracy, consistency, and efficiency. The researchers acknowledge the limitations of the GPT-based approach, such as its potential struggles with rare or context-dependent entities, which is an important caveat to consider.
One area that could benefit from further exploration is the impact of fine-tuning or other techniques to improve GPT's domain-specific capabilities. The paper suggests that additional research is needed in this area, which is a valid point. It would be interesting to see how much performance improvement can be achieved through targeted fine-tuning or other model adaptation methods.
Additionally, the paper could have provided more insight into the practical implications of using GPT as an Astro-NER annotator. For example, how would this approach compare to traditional human expert annotation in terms of cost, scalability, and the ability to handle large-scale datasets? Exploring these practical considerations could further strengthen the arguments for the real-world applicability of the proposed approach.
Overall, the paper presents a compelling case for the use of large language models like GPT as domain expert annotators, with the potential to significantly streamline the creation of high-quality datasets for specialized NER tasks. The critical analysis highlights areas for further research and practical considerations that could strengthen the impact of this work.
Conclusion
This paper investigates the feasibility of using the GPT language model as a domain expert annotator for astronomy named entity recognition (Astro-NER). The researchers find that GPT can achieve near-human-level performance on many Astro-NER tasks, suggesting its potential as a scalable and cost-effective tool for constructing high-quality datasets to support advanced NLP capabilities in astronomy.
The findings have important implications for the field of natural language processing, demonstrating how large language models can be leveraged as "domain experts" to streamline the creation of specialized datasets. This could accelerate progress in a variety of scientific and technical domains that require robust named entity recognition, such as materials science and biomedical literature.
The paper also highlights the need for further research to fine-tune and improve the performance of these language models for domain-specific NER tasks, as well as to address practical considerations around scalability and cost-effectiveness. Nonetheless, the results presented in this work suggest an exciting new direction for leveraging the capabilities of large language models to enhance natural language processing in specialized fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models and Knowledge Graphs for Astronomical Entity Disambiguation
Golnaz Shapurian
0
0
This paper presents an experiment conducted during a hackathon, focusing on using large language models (LLMs) and knowledge graph clustering to extract entities and relationships from astronomical text. The study demonstrates an approach to disambiguate entities that can appear in various contexts within the astronomical domain. By collecting excerpts around specific entities and leveraging the GPT-4 language model, relevant entities and relationships are extracted. The extracted information is then used to construct a knowledge graph, which is clustered using the Leiden algorithm. The resulting Leiden communities are utilized to identify the percentage of association of unknown excerpts to each community, thereby enabling disambiguation. The experiment showcases the potential of combining LLMs and knowledge graph clustering techniques for information extraction in astronomical research. The results highlight the effectiveness of the approach in identifying and disambiguating entities, as well as grouping them into meaningful clusters based on their relationships.
6/18/2024
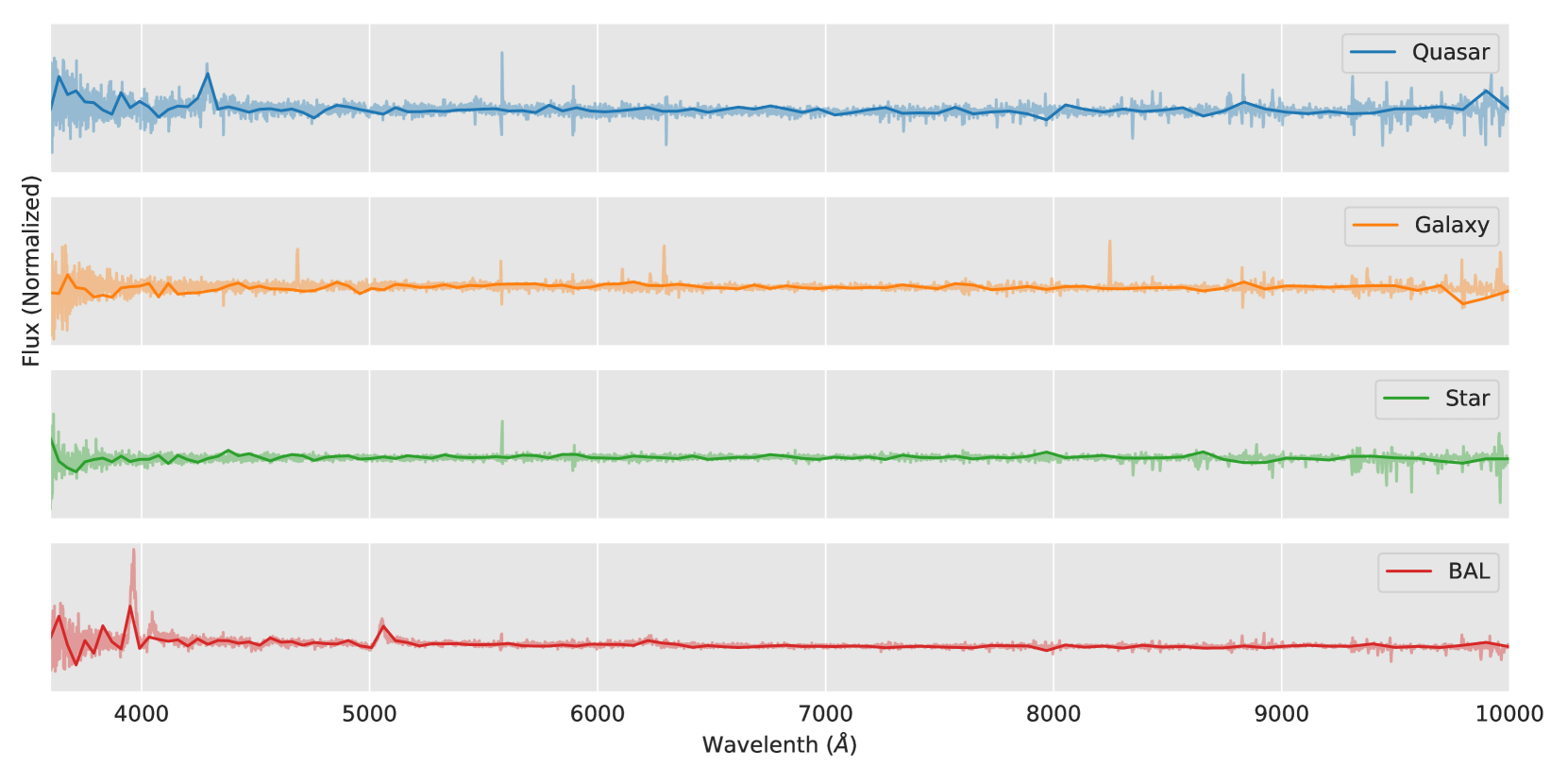
Can AI Understand Our Universe? Test of Fine-Tuning GPT by Astrophysical Data
Yu Wang, Shu-Rui Zhang, Aidin Momtaz, Rahim Moradi, Fatemeh Rastegarnia, Narek Sahakyan, Soroush Shakeri, Liang Li
0
0
ChatGPT has been the most talked-about concept in recent months, captivating both professionals and the general public alike, and has sparked discussions about the changes that artificial intelligence (AI) will bring to the world. As physicists and astrophysicists, we are curious about if scientific data can be correctly analyzed by large language models (LLMs) and yield accurate physics. In this article, we fine-tune the generative pre-trained transformer (GPT) model by the astronomical data from the observations of galaxies, quasars, stars, gamma-ray bursts (GRBs), and the simulations of black holes (BHs), the fine-tuned model demonstrates its capability to classify astrophysical phenomena, distinguish between two types of GRBs, deduce the redshift of quasars, and estimate BH parameters. We regard this as a successful test, marking the LLM's proven efficacy in scientific research. With the ever-growing volume of multidisciplinary data and the advancement of AI technology, we look forward to the emergence of a more fundamental and comprehensive understanding of our universe. This article also shares some interesting thoughts on data collection and AI design. Using the approach of understanding the universe - looking outward at data and inward for fundamental building blocks - as a guideline, we propose a method of series expansion for AI, suggesting ways to train and control AI that is smarter than humans.
4/17/2024
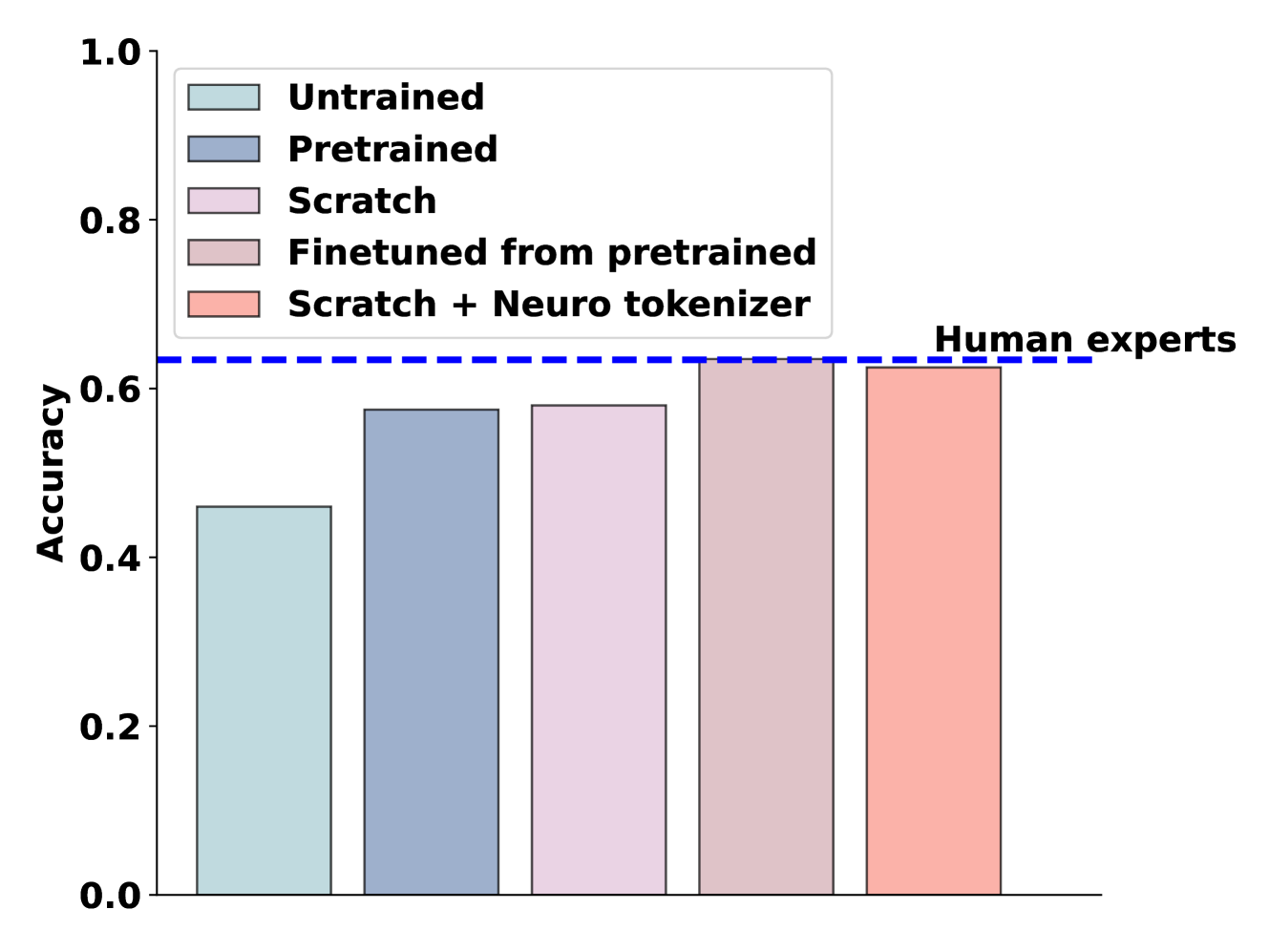
Matching domain experts by training from scratch on domain knowledge
Xiaoliang Luo, Guangzhi Sun, Bradley C. Love
0
0
Recently, large language models (LLMs) have outperformed human experts in predicting the results of neuroscience experiments (Luo et al., 2024). What is the basis for this performance? One possibility is that statistical patterns in that specific scientific literature, as opposed to emergent reasoning abilities arising from broader training, underlie LLMs' performance. To evaluate this possibility, we trained (next word prediction) a relatively small 124M-parameter GPT-2 model on 1.3 billion tokens of domain-specific knowledge. Despite being orders of magnitude smaller than larger LLMs trained on trillions of tokens, small models achieved expert-level performance in predicting neuroscience results. Small models trained on the neuroscience literature succeeded when they were trained from scratch using a tokenizer specifically trained on neuroscience text or when the neuroscience literature was used to finetune a pretrained GPT-2. Our results indicate that expert-level performance may be attained by even small LLMs through domain-specific, auto-regressive training approaches.
5/16/2024
Intent Detection and Entity Extraction from BioMedical Literature
Ankan Mullick, Mukur Gupta, Pawan Goyal
0
0
Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
4/5/2024