Can AI Understand Our Universe? Test of Fine-Tuning GPT by Astrophysical Data
2404.10019
0
0
Abstract
ChatGPT has been the most talked-about concept in recent months, captivating both professionals and the general public alike, and has sparked discussions about the changes that artificial intelligence (AI) will bring to the world. As physicists and astrophysicists, we are curious about if scientific data can be correctly analyzed by large language models (LLMs) and yield accurate physics. In this article, we fine-tune the generative pre-trained transformer (GPT) model by the astronomical data from the observations of galaxies, quasars, stars, gamma-ray bursts (GRBs), and the simulations of black holes (BHs), the fine-tuned model demonstrates its capability to classify astrophysical phenomena, distinguish between two types of GRBs, deduce the redshift of quasars, and estimate BH parameters. We regard this as a successful test, marking the LLM's proven efficacy in scientific research. With the ever-growing volume of multidisciplinary data and the advancement of AI technology, we look forward to the emergence of a more fundamental and comprehensive understanding of our universe. This article also shares some interesting thoughts on data collection and AI design. Using the approach of understanding the universe - looking outward at data and inward for fundamental building blocks - as a guideline, we propose a method of series expansion for AI, suggesting ways to train and control AI that is smarter than humans.
Create account to get full access
Overview
- This research paper investigates whether large language models like GPT can be used to understand and make predictions about astrophysical data.
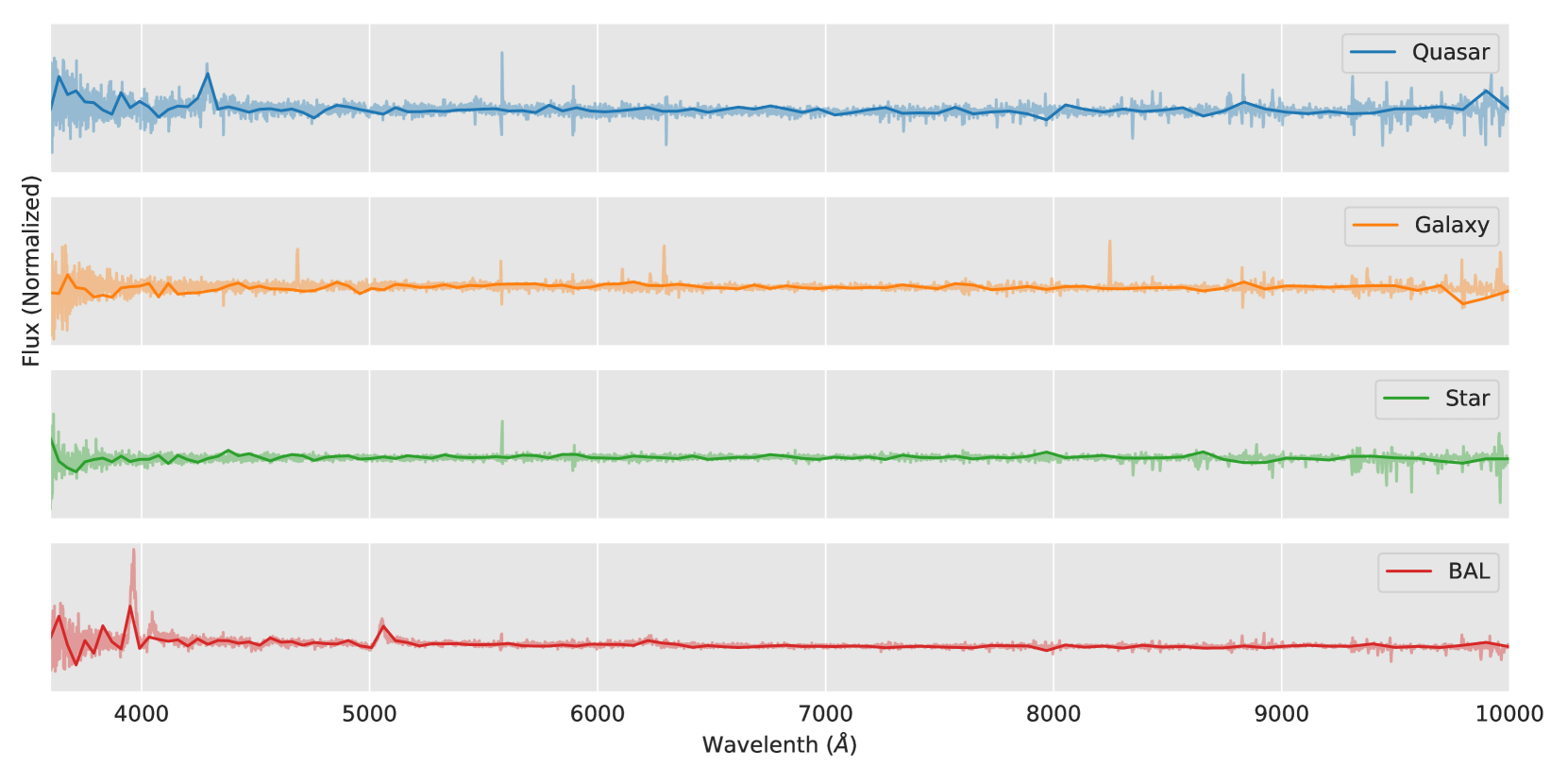
- The authors fine-tuned GPT on a dataset of Gamma-Ray Burst (GRB) observations and then evaluated the model's ability to classify GRBs and predict their properties.
- The results suggest that fine-tuning GPT on astrophysical data can enable it to gain a deeper understanding of the underlying physics and make accurate predictions, showcasing the potential of AI models to contribute to scientific discovery.
Plain English Explanation
In this study, the researchers wanted to see if a powerful AI language model called GPT could be trained to understand and make predictions about data from astrophysics, a field of science that studies the universe. They took GPT and fine-tuned it, which means they trained it on a specific dataset of observations of Gamma-Ray Bursts (GRBs). GRBs are extremely bright flashes of gamma rays that come from space and can provide clues about the most energetic and violent events in the universe.
The researchers found that by fine-tuning GPT on this astrophysical data, the model was able to gain a deeper understanding of the underlying physics and make accurate predictions about the properties of GRBs, like what type they are and how bright they will be. This shows that AI models like GPT have the potential to be powerful tools for scientific discovery, as they can uncover insights and patterns in complex data that humans might miss. The researchers' work demonstrates that AI can be used to study and better understand our universe.
Technical Explanation
The authors of this paper fine-tuned the GPT language model on a dataset of Gamma-Ray Burst (GRB) observations to investigate whether such models can be used to gain a deeper understanding of astrophysical phenomena. GRBs are extremely energetic explosions in space that emit large amounts of gamma radiation, and studying their properties can provide insights into the most extreme events in the universe.
The fine-tuning process involved training the pre-trained GPT model on a curated dataset of GRB parameters, including their duration, spectral properties, and other observed characteristics. The authors then evaluated the fine-tuned model's performance on two key tasks: GRB classification and GRB property prediction. For classification, the model had to determine the type of GRB (short or long). For property prediction, the model had to forecast the values of various GRB parameters.
The results showed that the fine-tuned GPT model was able to achieve high accuracy on both tasks, demonstrating its ability to learn the underlying astrophysical patterns and relationships from the data. The authors argue that this showcases the potential of large language models like GPT to contribute to scientific discovery by uncovering insights that may be difficult for humans to extract from complex astrophysical datasets.
Critical Analysis
The research presented in this paper suggests that fine-tuning large language models like GPT on astrophysical data can enable them to gain a deeper understanding of the underlying physics and make accurate predictions about celestial phenomena. This is an exciting finding, as it demonstrates the potential of AI to augment and accelerate scientific discovery in fields like astrophysics.
However, the authors acknowledge several caveats and limitations to their work. First, the dataset used for fine-tuning was relatively small, and the model's performance may not generalize as well to larger, more diverse astrophysical datasets. Additionally, the authors note that the fine-tuning process was computationally intensive and may not be scalable to larger models or datasets.
Another potential concern is the interpretability of the fine-tuned model's decision-making process. While the model achieved high accuracy on the GRB classification and property prediction tasks, it is not always clear how it arrived at its predictions. Improving the interpretability of such AI systems would be crucial for building trust and confidence in their scientific applications.
Despite these limitations, the researchers' work represents an important step in exploring the use of large language models for astrophysical research. As AI technologies continue to advance, it will be crucial for scientists and researchers to critically evaluate their capabilities and limitations to ensure that they are deployed responsibly and effectively in scientific domains.
Conclusion
This research paper demonstrates the potential of fine-tuning large language models like GPT on astrophysical data to gain a deeper understanding of the underlying physics and make accurate predictions about celestial phenomena. By training GPT on a dataset of Gamma-Ray Burst observations, the authors were able to show that the model could classify GRBs and forecast their properties with high accuracy.
The findings suggest that AI models like GPT could serve as powerful tools for scientific discovery, enabling researchers to uncover insights and patterns in complex astrophysical data that might be difficult for humans to detect. As AI technologies continue to advance, it will be essential for scientists to carefully evaluate their capabilities and limitations to ensure that they are leveraged effectively and responsibly in the pursuit of scientific knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Does GPT Really Get It? A Hierarchical Scale to Quantify Human vs AI's Understanding of Algorithms
Mirabel Reid, Santosh S. Vempala
0
0
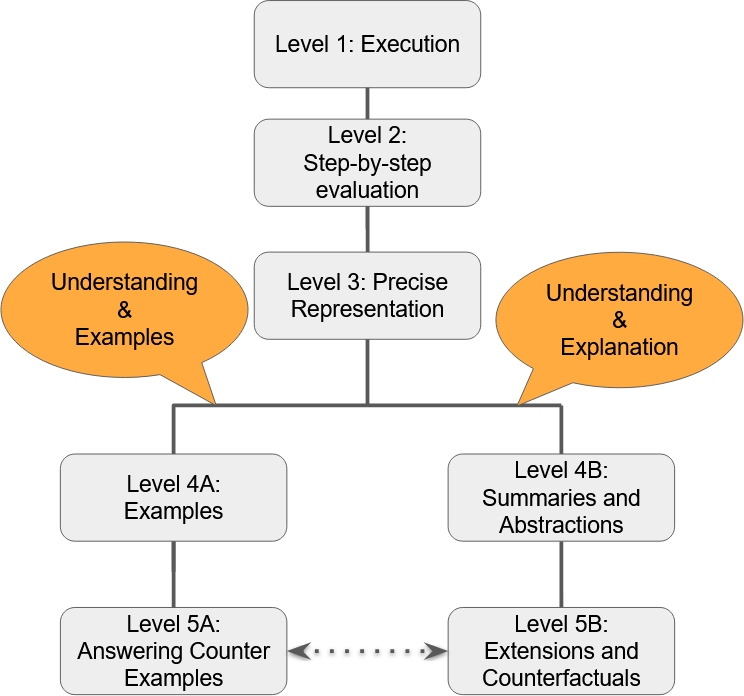
As Large Language Models (LLMs) perform (and sometimes excel at) more and more complex cognitive tasks, a natural question is whether AI really understands. The study of understanding in LLMs is in its infancy, and the community has yet to incorporate well-trodden research in philosophy, psychology, and education. We initiate this, specifically focusing on understanding algorithms, and propose a hierarchy of levels of understanding. We use the hierarchy to design and conduct a study with human subjects (undergraduate and graduate students) as well as large language models (generations of GPT), revealing interesting similarities and differences. We expect that our rigorous criteria will be useful to keep track of AI's progress in such cognitive domains.
6/24/2024
📊
Unmasking the giant: A comprehensive evaluation of ChatGPT's proficiency in coding algorithms and data structures
Sayed Erfan Arefin, Tasnia Ashrafi Heya, Hasan Al-Qudah, Ynes Ineza, Abdul Serwadda
0
0
The transformative influence of Large Language Models (LLMs) is profoundly reshaping the Artificial Intelligence (AI) technology domain. Notably, ChatGPT distinguishes itself within these models, demonstrating remarkable performance in multi-turn conversations and exhibiting code proficiency across an array of languages. In this paper, we carry out a comprehensive evaluation of ChatGPT's coding capabilities based on what is to date the largest catalog of coding challenges. Our focus is on the python programming language and problems centered on data structures and algorithms, two topics at the very foundations of Computer Science. We evaluate ChatGPT for its ability to generate correct solutions to the problems fed to it, its code quality, and nature of run-time errors thrown by its code. Where ChatGPT code successfully executes, but fails to solve the problem at hand, we look into patterns in the test cases passed in order to gain some insights into how wrong ChatGPT code is in these kinds of situations. To infer whether ChatGPT might have directly memorized some of the data that was used to train it, we methodically design an experiment to investigate this phenomena. Making comparisons with human performance whenever feasible, we investigate all the above questions from the context of both its underlying learning models (GPT-3.5 and GPT-4), on a vast array sub-topics within the main topics, and on problems having varying degrees of difficulty.
5/28/2024
🌐
Astro-NER -- Astronomy Named Entity Recognition: Is GPT a Good Domain Expert Annotator?
Julia Evans, Sameer Sadruddin, Jennifer D'Souza
0
0
In this study, we address one of the challenges of developing NER models for scholarly domains, namely the scarcity of suitable labeled data. We experiment with an approach using predictions from a fine-tuned LLM model to aid non-domain experts in annotating scientific entities within astronomy literature, with the goal of uncovering whether such a collaborative process can approximate domain expertise. Our results reveal moderate agreement between a domain expert and the LLM-assisted non-experts, as well as fair agreement between the domain expert and the LLM model's predictions. In an additional experiment, we compare the performance of finetuned and default LLMs on this task. We have also introduced a specialized scientific entity annotation scheme for astronomy, validated by a domain expert. Our approach adopts a scholarly research contribution-centric perspective, focusing exclusively on scientific entities relevant to the research theme. The resultant dataset, containing 5,000 annotated astronomy article titles, is made publicly available.
5/7/2024
📉
On the rate of convergence of an over-parametrized Transformer classifier learned by gradient descent
Michael Kohler, Adam Krzyzak
0
0
One of the most recent and fascinating breakthroughs in artificial intelligence is ChatGPT, a chatbot which can simulate human conversation. ChatGPT is an instance of GPT4, which is a language model based on generative gredictive gransformers. So if one wants to study from a theoretical point of view, how powerful such artificial intelligence can be, one approach is to consider transformer networks and to study which problems one can solve with these networks theoretically. Here it is not only important what kind of models these network can approximate, or how they can generalize their knowledge learned by choosing the best possible approximation to a concrete data set, but also how well optimization of such transformer network based on concrete data set works. In this article we consider all these three different aspects simultaneously and show a theoretical upper bound on the missclassification probability of a transformer network fitted to the observed data. For simplicity we focus in this context on transformer encoder networks which can be applied to define an estimate in the context of a classification problem involving natural language.
6/21/2024